num_words = 10000 # Größe des Vokabulars
cutoff = 500 # so viele Wörter betrachten wir pro Sequenz
epochs = 1015 Rekurrente Netze
In diesem Kapitel geht es um Rekurrente Neuronale Netze (RNN). Das sind Netze, die Zyklen aufweisen und somit eine Art Gedächtnis haben, da sie Informationen aus der Vergangenheit berücksichtigen können. Wir lernen, wie das Problem des Vanishing/Exploding Gradients mit Gated Units reduziert werden kann, wie sie in den Architekturen LSTM (Long Short-Term Memory) und GRUs (Gated Recurrent Units) verwendet werden. Wir sehen uns außerdem die praktische Anwendung in Keras an und vergleichen verschiedene Netzarchitekturen (SimpleRNN, LSTM, GRU, auch kombiniert mit Bidirectional).
Konzepte in diesem Kapitel
Elman-Netze, Bidirektionale RNN, Long Short-Term Memory (LSTM), Gated Recurrent Units (GRU)
15.1 Rekurrente Neuronale Netze (RNN)
In der Geschichte der Sprachverarbeitung kommt den Rekurrenten Neuronalen Netzen (RNN) eine enorm wichtige Bedeutung zu. RNN erlauben die Verarbeitung von beliebig langen Inputs, indem sie eine Art “Gedächtnis” verwenden. Techniken wie LSTM und GRU haben RNN zu hoher Effektivität verholfen. Mittlerweile sind RNN durch Transformer-Netze abgelöst worden, wie wir im nächsten Kapitel sehen werden.
Lesenswert ist der viel beachtete Artikel The Unreasonable Effectiveness of Recurrent Neural Networks von Andrej Karpathy.
15.1.1 Einleitung
Nachdem wir wissen, mit welchen Daten wir arbeiten werden, wenden wir uns den Neuronalen Netzen zu. Wir erweitern unsere Feedforward-Netze (FNN) um rückwärts gerichtete (rekurrente) Verbindungen.
Schauen wir uns nochmal ein FNN mit einer versteckten Schicht an:
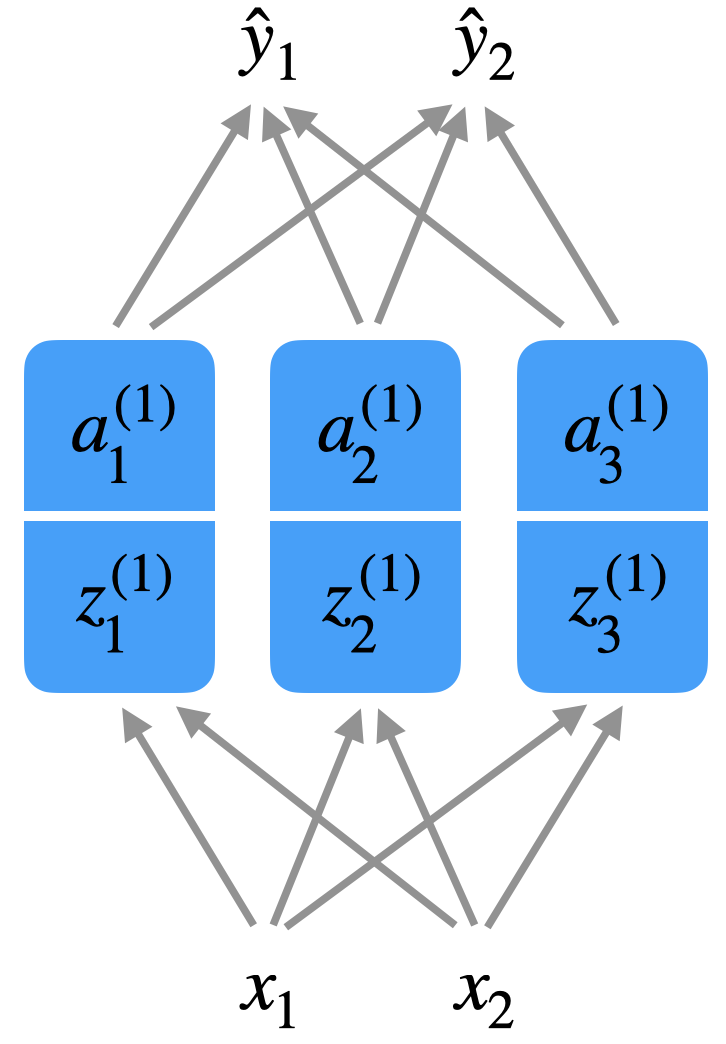
Jetzt soll unser Netzwerk z.B. in einem Satz \(s = (w_1, \ldots, w_n)\) immer das nächste Wort vorhersagen. Wir geben also ein Wort \(w_t\) ein, z.B. in One-Hot-Encoding, und die Ausgabe ist das hypothetische Wort \(\hat{w}_{t+1}\).
Vergleichen Sie diese Sätze. Das eingeklammerte Wort soll von unserem Netz vorhergesagt werden:
Er holte [sein] Buch
Sie holte[ihr] Buch
Wenn wir nur das Wort “holte” in unser Netz eingeben, ist es unmöglich, eine “richtige” Entscheidung zu treffen. Dem Netz braucht mehr Kontext, in diesem Fall würde ein weiteres Wort reichen. Notwendiger Kontext kann auch über Satzgrenzen hinweg reichen.
Peter trat ein. Dann setzte [er] sich.
Maria trat ein. Dann setzte [sie] sich.
Damit wir diesen Kontext erfassen, benötigen wir eine Art Gedächtnis für unsere Netze. Genau darum geht es bei RNN. Es kann auch sein, dass der notwendige Kontext in der Zukunft liegt. Vergleiche:
Er holte sein [Auto] und fuhr nach München.
Er holte sein [Tagebuch] und schrieb los.
Bevor wir uns RNN ansehen, erinnern wir uns an die Formeln für Forward Propagation (in Vektorschreibweise):
\[ \begin{align} a^{(0)} &:= x \tag{Eingabeschicht}\\[3mm] z^{(1)} &:= W^{(1)}\, a^{(0)} + b^{(1)}\tag{Roheingabe}\\[3mm] a^{(1)} &:= g(z^{(1)}) \tag{Aktivierung}\\[3mm] \hat{y} &:= a^{(2)}\tag{Ausgabe} \end{align} \]
Wir beziehen uns im Folgenden auf diese Formeln und modifizieren sie für RNN.
15.1.2 Elman-Netz
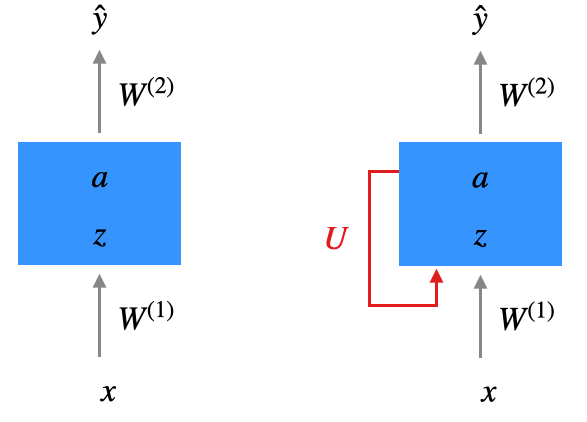
Bei einem einfachen RNN wie dem sogenannten Elman-Netz wird die Ausgabe der versteckten Schicht \(a^{(1)}\) bei der nächsten Eingabe wieder mit aufgenommen (Elman 1990). Natürlich ist diese zusätzliche Eingabe auch über Gewichte reguliert. Diese “neue” Eingabe wird einfach mit der regulären Eingabe, die vom Featurevektor \(x\) kommt, addiert. Aber dazu später.
Zum Begriff Elman-Netz: Ein Elman-Netz hat sogenannte Kontextneuronen. Die Zwischenschicht wird in diese Kontextschicht kopiert und im nächsten Schritt gehen die Neuronen dieser Kontextschicht wieder in die versteckte Schicht ein. Dies ist äquivalent zu dem Netz, das wir hier vorstellen. Bei der Gelegenheit: ein Jordan-Netz ist wie ein Elman-Netz mit dem Unterschied, dass der Output \(\hat{y}\) in die Kontextschicht kopiert wird (Jordan 1990).
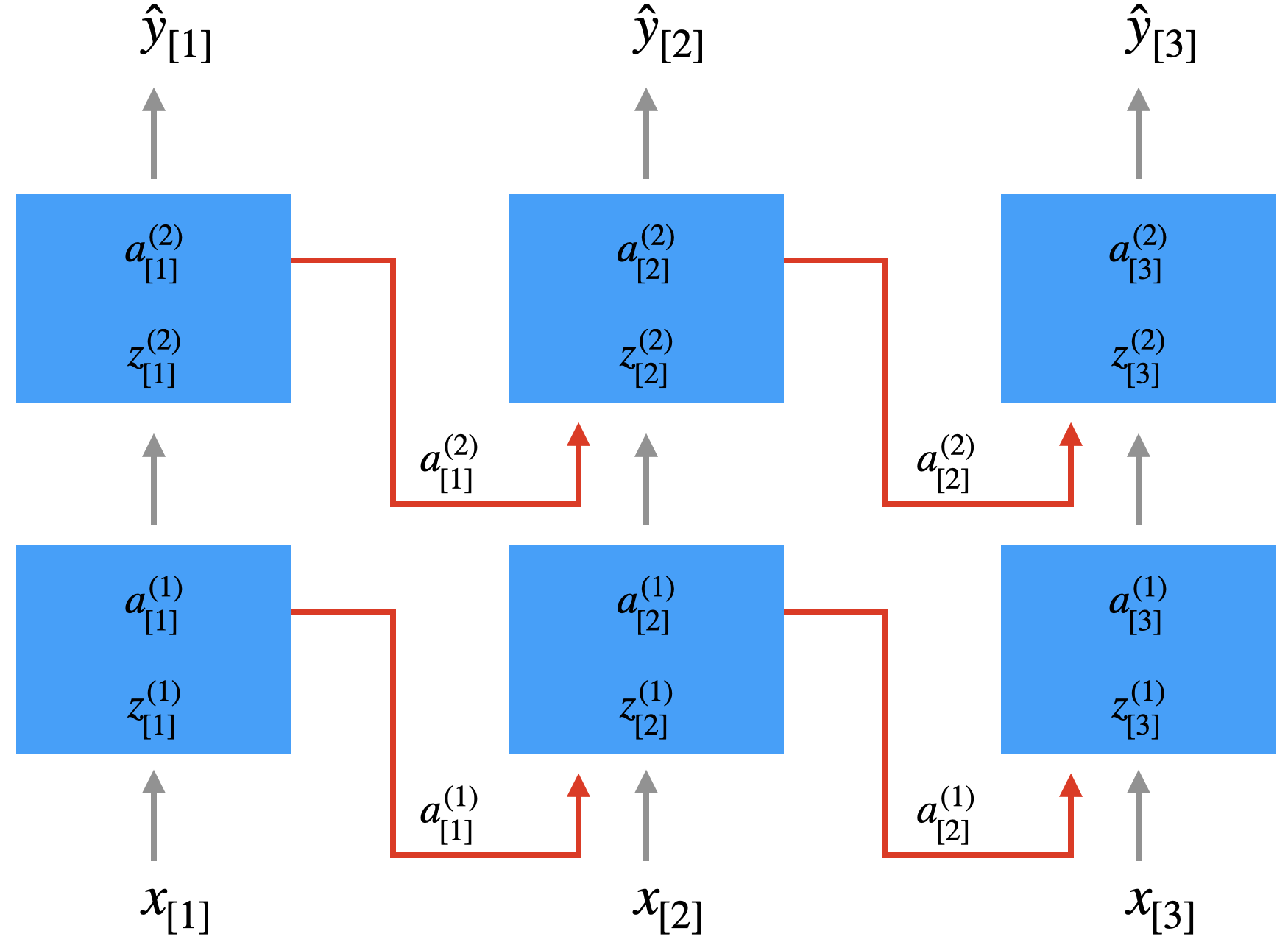
Die Abbildung unten soll zeigen, wie die versteckte Schicht “mit sich selbst” verbunden ist. Die linke Abbildung zeigt exemplarisch die Verbindungen von Neuron \(a_1^{(1)}\). Eigentlich haben Sie hier die volle Konnektivität, wie rechts dargestellt, d.h. es gibt 9 Verbindungen, die mit einer 3x3-Matrix \(U\) repräsentiert werden können.
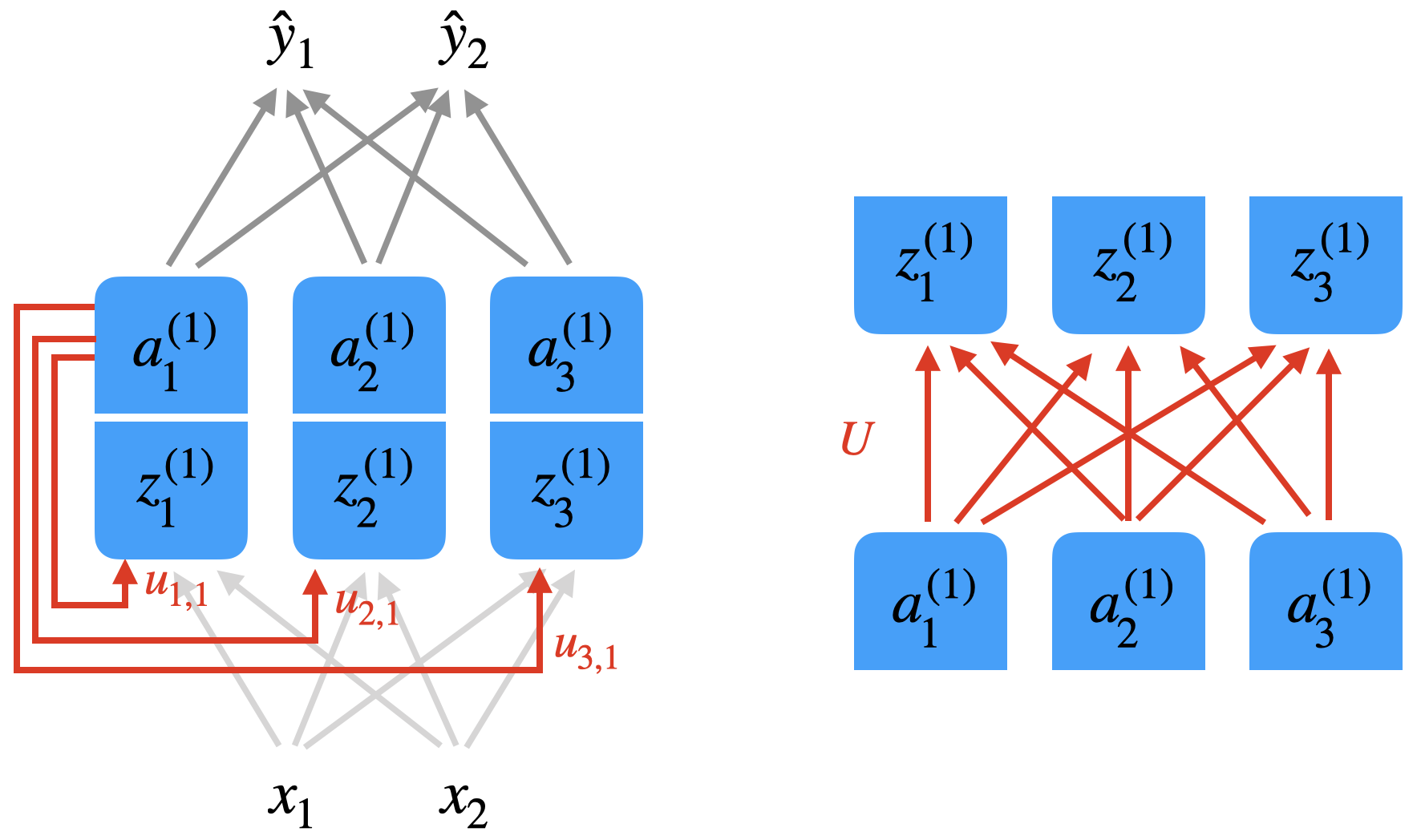
Wir vereinfachen jetzt die Schichtdarstellung. Die Zwischenschicht wird als Box dargestellt, \(z\) und \(a\) sind Vektoren. Die Tatsache, dass \(a\) wieder eingespeist wird, wird durch den roten Pfeil dargestellt. Es handelt sich bei dem Netz jetzt nicht mehr um einen zyklenfreien Graphen (also kein DAG).
Um zu klären, wann genau \(a\) wieder eingespeist wird, führen wir einen Index \(t\) für den Zeitschritt ein. Wir haben es ja mit Inputsequenzen zu tun (z.B. Wörter), so dass wir für eine Inputsequenz \(x_{[1]}, x_{[2]}, \ldots, x_{[N_x]}\) schreiben (\(N_x\) ist also die Länge der aktuellen Inputsequenz). Jedes \(x_{[t]}\) ist hier ein vollwertiger Featurevektor (z.B. ein Wort in One-Hot-Kodierung).
Wir verwenden Index \(t\) nicht nur bei der Eingabe, sondern auch bei den entsprechenden berechneten Werten (Rohinput, Aktivierung, Output). Wenn wir uns das Netz anschauen, sehen wir, dass zum Zeitpunkt \(t\) das Ergebnis der Zwischenschicht vom Zeitpunkt \(t-1\) eingespeist wird. Wie bereits erwähnt soll die Eingabe von \(a_{[t-1]}\) mit der Eingabe von \(x_{[t]}\) addiert werden.
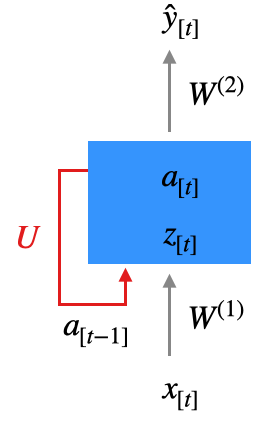
Wir formalisieren wir das? Zunächst mal führen wir den Parameter \(t\) für den Zeitschritt in unsere Formeln für Forward Propagation ein. In der versteckten Schicht \(l=1\) addieren bei den \(a^{(1)}_{[t]}\) einfach die eigene Eingabe vom vorigen Zeitschritt, also \(a^{(1)}_{[t-1]}\). Dazu haben wir eine eigene Gewichtsmatrix \(U\). Sie finden das hier unter “Roheingabe” (wir lassen den Index bei \(a^{(1)}\) und \(z^{(1)}\) weg):
\[ \begin{align} z_{[t]} &:= W^{(1)}\, x_{[t]} + U \,a_{[t-1]} + b \tag{Roheingabe}\\[3mm] a_{[t]} &:= g(z_{[t]}) \tag{Aktivierung}\\[3mm] \hat{y}_{[t]} &:= a_{[t]}\tag{Ausgabe} \end{align} \]
Wenn \(n\) die Größe der Eingabe \(x\) bezeichnet und \(n_1\) die Anzahl der Neuronen in der versteckten Schicht, dann ist \(W\) eine \(n_1 \times n\)-Matrix und \(U\) eine \(n_1\times n_1\)-Matrix.
Betrachten wir uns die Roheingabe:
\[ z_{[t]} := W^{(1)}\, x_{[t]} + U \,a_{[t-1]} + b \]
Wir definieren jetzt einen Operator, der Matrizen konkateniert (also zusammenfügt). Wenn die Matrizen \(A\) und \(B\) die gleiche Zeilenzahl haben, dann ist
\[ \left[ A ; B \right] \]
die zusammengesetzte Matrix, die sich ergibt, wenn man die Elemente von \(B\) direkt rechts neben die Elemente von \(A\) stellt. Ein Beispiel:
\[ \left[ \begin{pmatrix} a & b \\ c & d \end{pmatrix} ; \begin{pmatrix} e & f \\ g & h \end{pmatrix} \right] = \begin{pmatrix} a & b & e & f \\ c & d & g & h \end{pmatrix} \]
Der Operator funktioniert auch in der Vertikalen, dann muss die Spaltenzahl übereinstimmen:
\[ \left[\begin{array}{c} \left( \begin{array}{c} a \\ b \end{array}\right) \\[1mm] \left( \begin{array}{c} c \\ d \end{array}\right) \end{array} \right] = \left( \begin{array}{c} a \\ b \\ c\\d\end{array}\right) \]
Mit Hilfe der Konkatenation kann man die Formel für \(z_{[t]}\) so formulieren (beide Matrizen haben Zeilenzahl \(n_2\)):
\[ z_{[t]} := \left[ W^{(1)} ; U \right] \, \left[\begin{array}{c} x_{[t]} \\[1mm] \,a_{[t-1]} \end{array} \right] + b \]
Die obige Darstellung erlaubt es uns, die Matrix \(\left[ W^{(1)} ; U \right]\) als die eine Gewichtsmatrix der versteckten Schicht aufzufassen.
Eine alternative Darstellung “wickelt” das Verhalten über die Zeit auf in mehrere Netzwerke zu unterschiedlichen Zeiten \(t\). Wir werden uns auch an diese Darstellung halten.
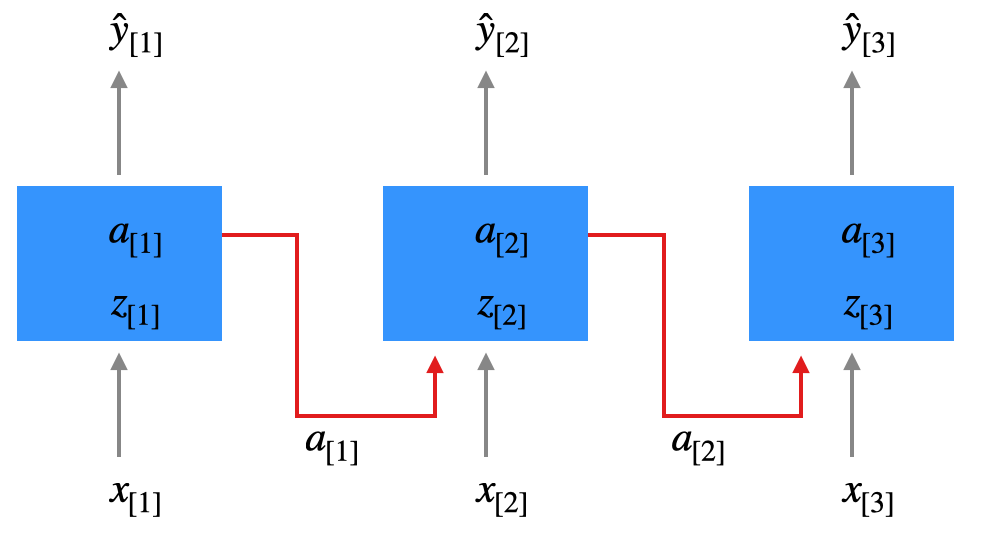
15.1.3 RNN-Architekturen
Das Elman-Netz, das wir oben gesehen haben, ist ein Beispiel für eine Many-to-Many-Architektur, wo die Länge der Eingabesequenz, die wir als \(N_x\) bezeichnen, genauso groß ist wie die Länge der Ausgabesequenz \(N_y\), also \(N_x = N_y\).
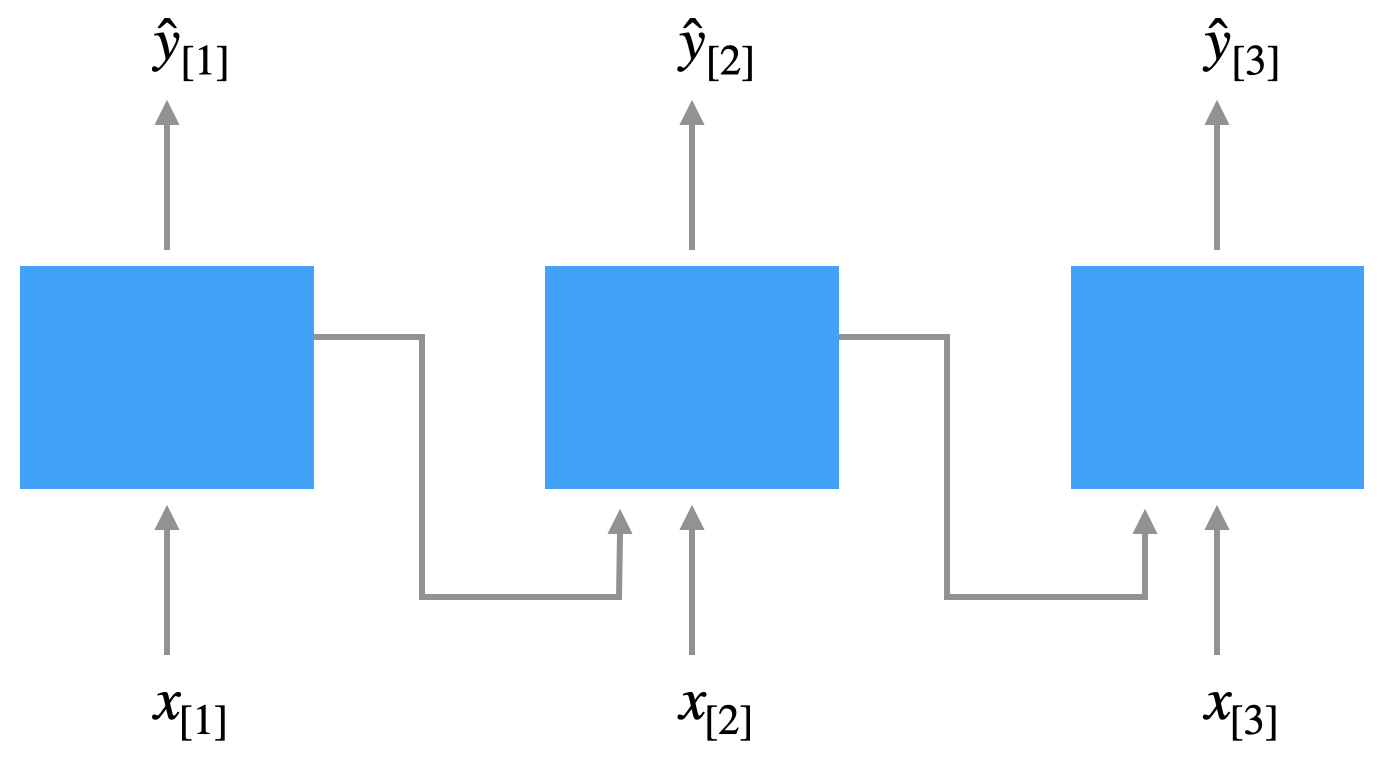
Schauen wir uns noch weitere Architektur-Varianten an.
Bei der Many-to-One-Architektur wird eine Sequenz mit einem Klassenlabel versehen, z.B. bei der Sentiment Analysis (Filmreviews in positiv/negativ kategorisieren). Die Eingabe \(x_{[1]}, x_{[2]}, \ldots\) besteht in diesem Fall aus Wörtern, die Ausgabe \(\hat{y}\) ist eine Zahl \(\in [0, 1]\) für die Wahrscheinlichkeit, dass ein Review positiv ist.
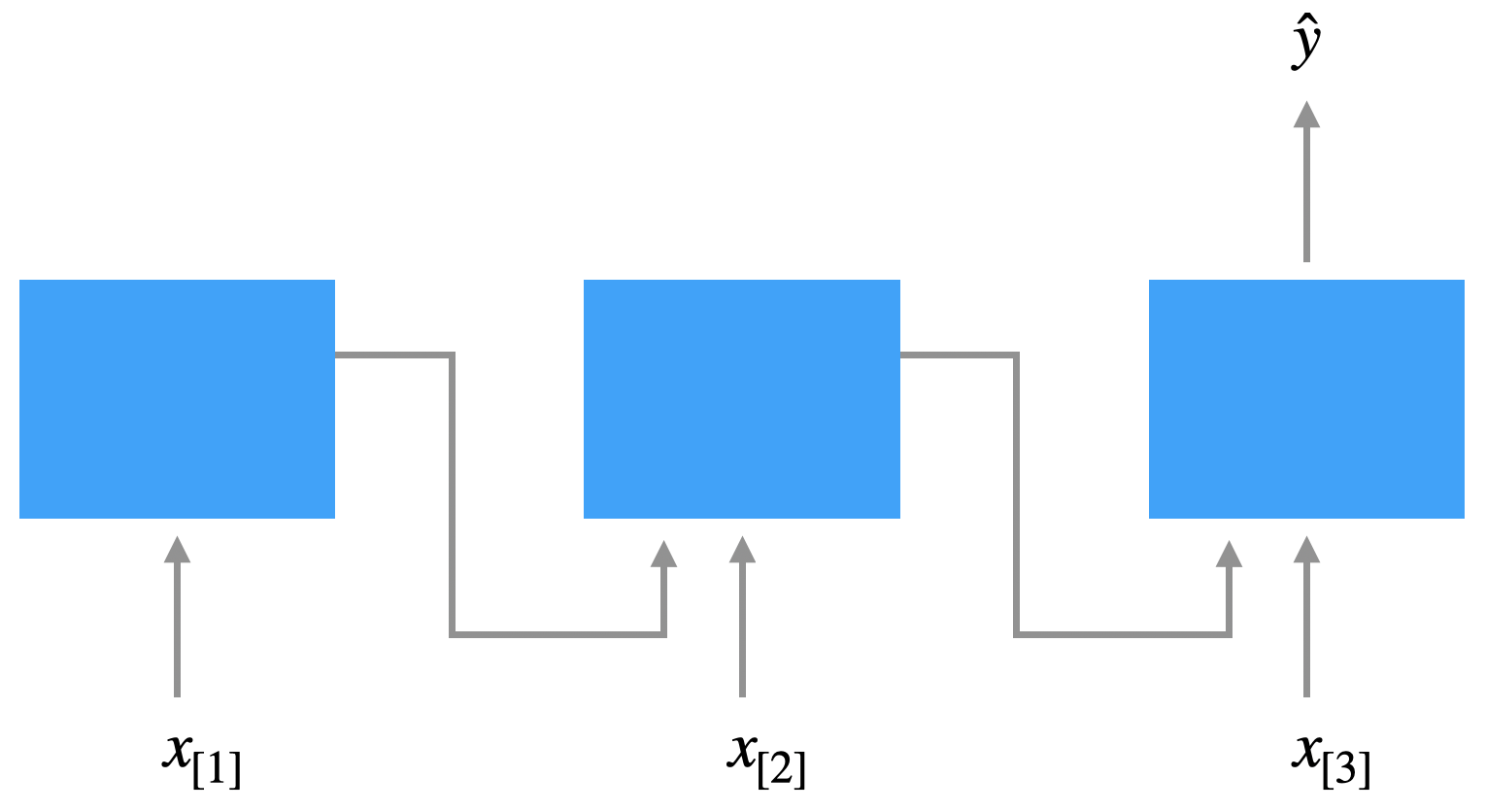
Bei der One-to-Many-Architektur will man Sequenzen generieren, z.B. ein Musikstück aus ein paar Anfangsnoten oder einen Text im Stile eines Autoren (der Autor ist die Eingabeklasse). Hier ist die Eingabe \(x\) zum Beispiel eine Note und die Ausgabe \(\hat{y}_{[1]}, \hat{y}_{[1]}, \ldots\) eine Sequenz von Noten.
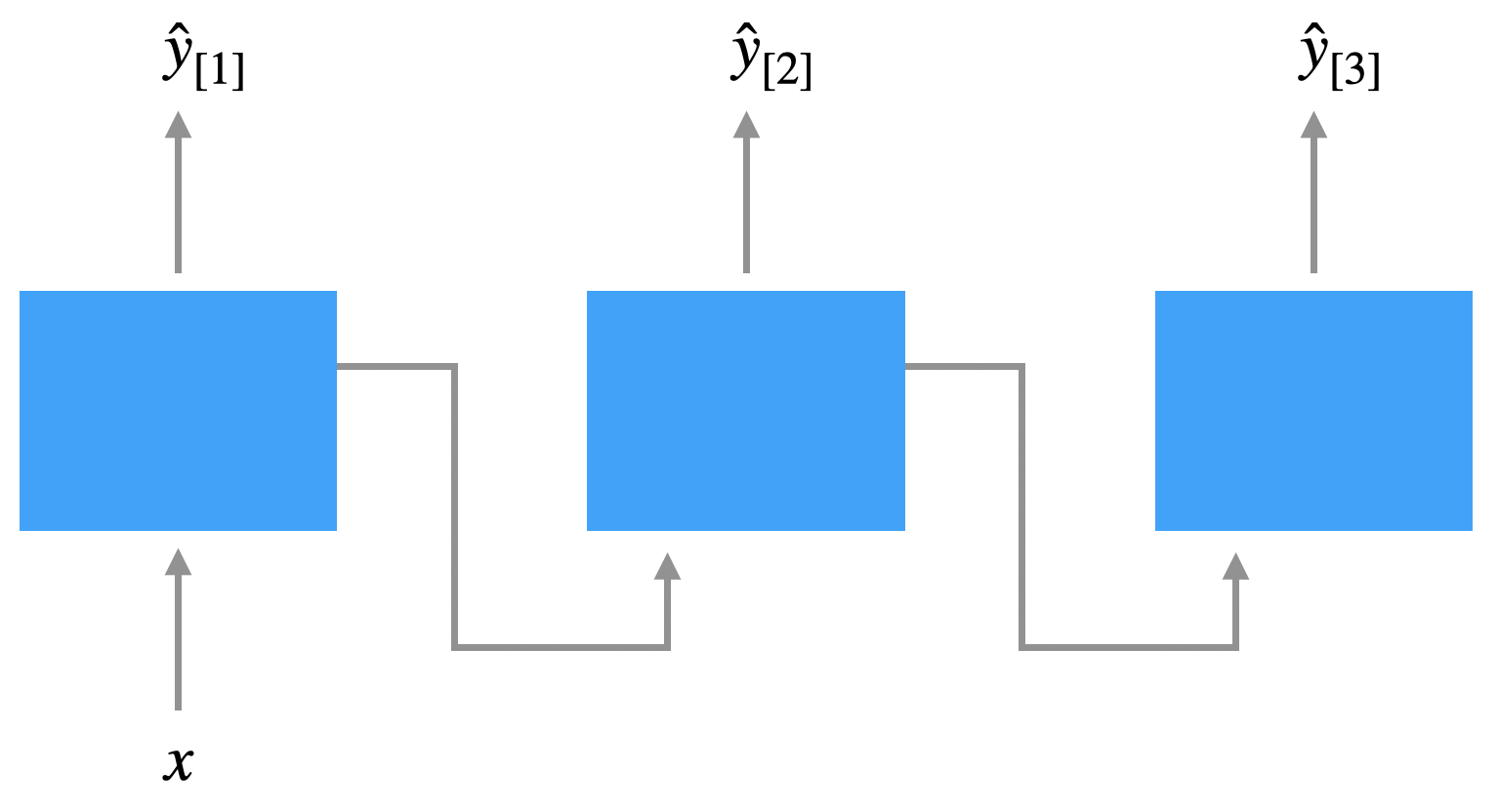
Bei der Many-to-Many-Architektur gibt es noch die Encoder-Decoder-Variante. Dort ist die Eingabelänge \(N_x\) nicht gleich Ausgabelänge \(N_y\) ist, was typischerweise in der maschinellen Übersetzung der Fall ist.
Das funktioniert so, dass erst die Eingabe mit einem Netz - dem Encoder-Netz - verarbeitet wird. Das ist praktisch ein Many-to-One-Netz. Die Ausgabe des Encoder-Netzes wird dem Decoder-Netz übergeben, praktisch ein One-to-Many-Netz, das daraus die Ausgabe generiert.
Hier sind sowohl die Eingabe als auch die Ausgabe Sequenzen von Wörtern.
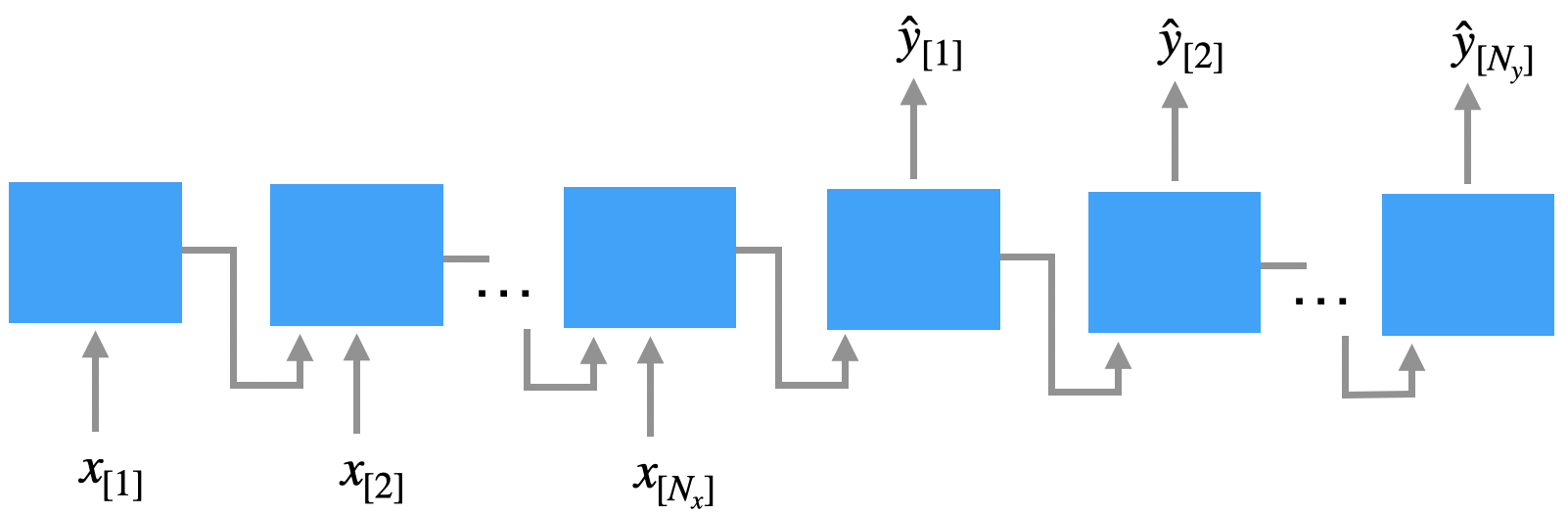
Wie gesagt: Diese Variante ist die typische Wahl für Übersetzungssysteme und überall, wo Eingabe und Ausgabe unterschiedlich lang sind.
15.1.4 RNN mit mehreren Schichten
Es ist naheliegend, ein RNN mit mehr als einer Zwischenschicht zu versehen. Hier sehen wir ein Drei-Schicht-RNN (wenn wir die Eingabeschicht mitzählen):
Bei FNN haben wir gesehen, dass man extrem effizient arbeiten kann, wenn man für einen kompletten “Batch” von Trainingsbeispielen (z.B. 64 Stück) zunächst die Zwischenschicht berechnet (Schicht 2) und anschließend für den Batch den Output (Schicht 3) berechnet.
Bei einem rekurrenten Netz muss man aufpassen. Nehmen wir an, wir haben einen Batch mit zwei Trainingsbeispielen, wobei wir die Inputsequenzen \((b_{[1]}, b_{[2]}, \ldots, b_{[n]})\) und \((c_{[1]}, c_{[2]}, \ldots, c_{[m]})\) nennen.
Bei der Batch-Verarbeitung werden die Werte \(b_{[1]}\) und \(c_{[1]}\) parallel verarbeitet, indem der Output der Schicht 2 berechnet wird. Bei der Berechnung von Schicht 3 kann aber parallel mit der Verarbeitung von \(b_{[2]}\) und \(c_{[2]}\) begonnen werden.
In der folgenden Abbildung sehen Sie die effiziente Berechnung einer Inputsequenz \((x_{[1]},x_{[2]},x_{[3]})\) in einem 3-Schicht-Netz. Sie sehen, dass vier Schritte nötig sind (Schritt = Berechnung innerhalb einer Schicht).
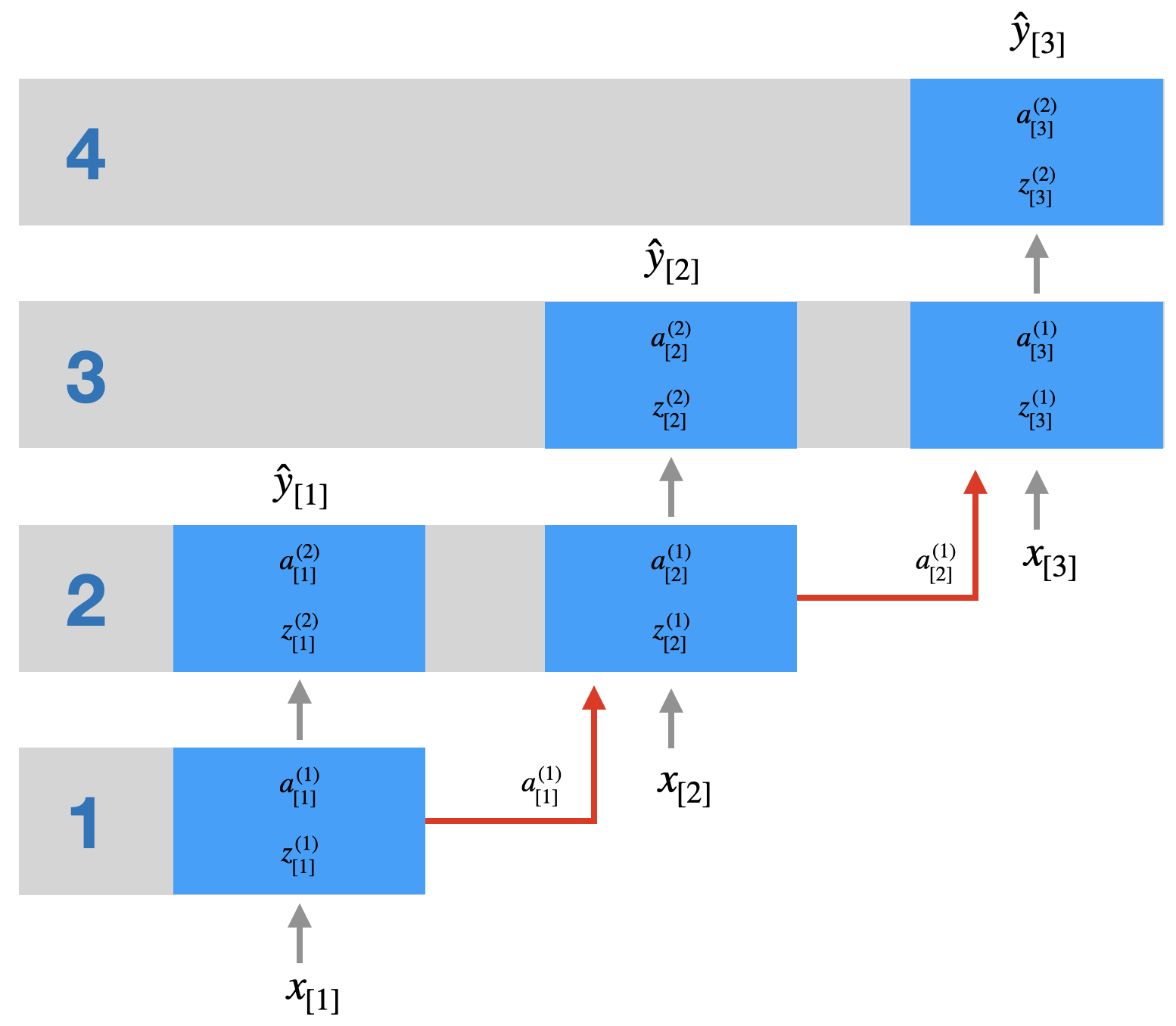
Im Grunde funktioniert ein rekurrentes Netz wie ein “vertieftes” Netz. Im abgebildeten Beispiel haben wir ein 3-Schicht-Netz, wo normalerweise zwei Schichten berechnet werden müssen (Schicht 2 und 3). Wenn wir eine Inputsequenz der Länge 3 haben, berechnen wir aber effektiv 4 Schichten. Bei einer Inputsequenz der Länge 200 (durchaus üblich bei Texten), entspricht dies also einem Netz der Tiefe 201 (wenn das eigentlich Netz drei Schichten hat).
Hinweis zu Keras: Oft haben wir es mit Many-to-One-Problemen zu tun, d.h. eine Inputsequenz wird auf ein Label abgebildet, so dass nur das letzte \(\hat{y}\) relevant ist und alle vorigen Outputs ignoriert werden. Bei obigen Netz sieht man aber, dass die Output der Zwischenschicht \(a^{(2)}\) durchaus in jedem Zeitschritt benötigt werden (im Gegensatz zu den \(a^{(3)} = \hat{y}\). Daher muss man in Keras bei den nicht-finalen rekurrenten Schichten angeben return_sequences=True (Default ist False). Nur dann werden alle \(a^{(2)}\) weitergereicht.
15.1.5 Backpropagation Through Time (BPTT)
Wie werden in einem RNN die Gewichte gelernt? Die Lernmethode ist tatsächlich nur eine leichte Modifikation von Backpropagation (BP) und nennt sich Backpropagation Through Time oder BPTT (Werbos 1990; Williams and Zipser 1989).
Wir skizzieren BPTT anhand eines Many-to-Many-RNN, wo zu jedem Zeitschritt eine Ausgabe produziert wird und mit einer korrekten Ausgabe verglichen werden kann. Hier nochmal als beispielhafte Abbildung:
Interpretation eines RNN als tieferes Netz
Dass BPTT nicht so verschieden von Backpropagation sein kann, wird vielleicht klar, wenn man sich ein RNN in der “aufgewickelten” Darstellung vorstellt, wie wir es beim Thema “RNN mit mehreren Schichten” getan haben. Dort haben wir gesehen, dass man sich ein RNN nach mehreren Zeitschritten als ein “normales” Netz mit vielen Schichten vorstellen kann.
In der folgenden Abbildung sehen wir ein RNN mit zwei Zeitschritten. Die linke Darstellung zeigt die “aufgewickelte” Version. Die Zahlen zeigen die Reihenfolge der Abarbeitung durch die zwei Schichten und über die zwei Zeitschritte. Die rechte Darstellung zeigt die Interpretation als “tieferes” Netz. Der zweite Zeitschritt wird als Zusatzschichten desselben Netzes angesehen.
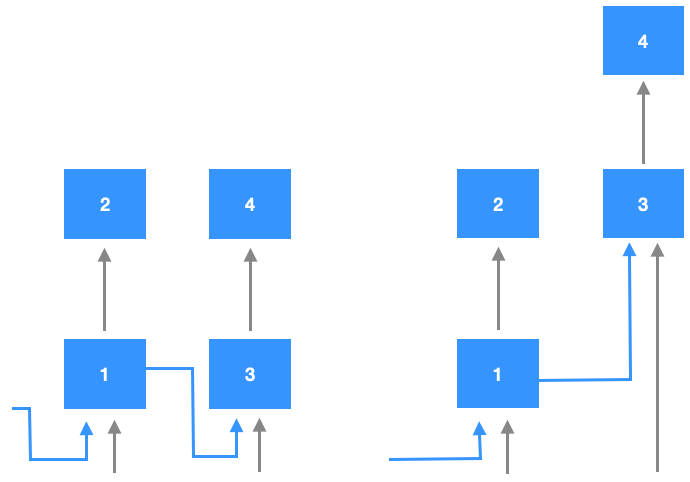
Zielfunktion
Auch bei BPTT muss man eine Zielfunktion definieren.
Wir definieren zunächst \(J_{[t]}\) (ohne Regularisierung) für einen einzelnen Zeitschritt \(t\).
\[ J_{[t]} = - \sum_{i=1}^m \left[ y_{i, [t]} \; log(\hat{y}_{i, [t]}) + (1 - y_{i, [t]}) \; log(1 - \hat{y}_{i, [t]})\right] \]
Wir haben oben über die Komponenten \(i\) der Vektoren \(y\) (korrekte Ausgabe) und \(\hat{y}\) (errechnete Ausgabe) summiert.
Jetzt summieren wird noch über die ganze Sequenz (z.B. Wörter), d.h. wir summieren über alle Zeitschritte \(t\):
\[ J = \sum_{t=1}^{N_x} J_{[t]} \]
Jetzt müsste man noch über alle Trainingsbeispiele im aktuellen Batch (bei Minibatch) summieren, aber das spielt für unseren Gedankengang keine Rolle.
Die Fehlerfunktion ist fast identisch mit unserer Fehlerfunktion im herkömmlichen Backpropagation.
Backpropagation
Jetzt erinnern Sie sich sicher, dass Backpropagation im ersten Schritt einen Fehlerwert \(\delta\) für jedes Neuron berechnet (ausgenommen Eingabeneuronen, siehe Abschnitt 8.2.3).
\[ \delta^{(l)} = \begin{cases} \hat{y} - y & \mbox{wenn}\quad l = L\\[3mm] (W^{(l+1)})^T \; \delta^{l+1} \odot a^{(l)} \odot (1 - a^{(l)})& \mbox{wenn}\quad l \in \{1, \ldots, L-1\} \end{cases} \]
Im zweiten Schritt wird für jedes Gewicht \(w\) ein Änderungswert \(\Delta w\) berechnet (wo die Fehlerwerte \(\delta\) mit eingehen).
\[ \Delta w_{i,j}^{(l)} = - \frac{\partial J}{\partial w_{i,j}^{(l)}} = - a_j^{(l)} \: \delta_i^{(l+1)} \]
Hier sehen wir ein RNN mit den ersten zwei Zeitschritten, also “aufgewickelt”. Im ersten Schritt wurden Fehlerwerte \(\delta\) berechnet. In der Abbildung handelt es sich um Vektoren. Im Gegensatz zur herkömmlichen BP hängt das \(\delta_{[1]}^{(1)}\) auch vom Delta im nächsten Zeitschritt ab.
Die herkömmliche Formel zur Berechnung eines \(\delta\) (nicht an der Ausgabeschicht)
\[ \delta^{(l)}_{[t]} = (W^{(l+1)}_{[t]})^T \; \delta^{l+1}_{[t]} \odot a^{(l)}_{[t]} \odot (1 - a^{(l)}_{[t]}) \]
wird zu folgender Formel:
\[ \delta^{(l)}_{[t]} = ([W^{(l+1)}_{[t]};U^{(l+1)}_{[t+1]}])^T \; \left[ \begin{array}{c} \delta^{l+1}_{[t]}\\ \delta^{l}_{[t+1]}\end{array}\right] \odot \left[ \begin{array}{c} a^{(l)}_{[t]} \\ a^{(l)}_{[t]}\end{array}\right] \odot \left[ \begin{array}{c} (1 - a^{(l)}_{[t]}) \\ (1 - a^{(l)}_{[t]}) \end{array}\right] \]
An dieser Formel ist wichtig, dass \(\delta^{(l)}_{[t]}\) von dem “zukünftigen” \(\delta^{(l)}_{[t+1]}\) abhängt.
Wenn Sie sich die weiteren Zeitschritte vorstellen, verstehen Sie, dass hier Fehlerwerte “durch die Zeit” transportiert werden.
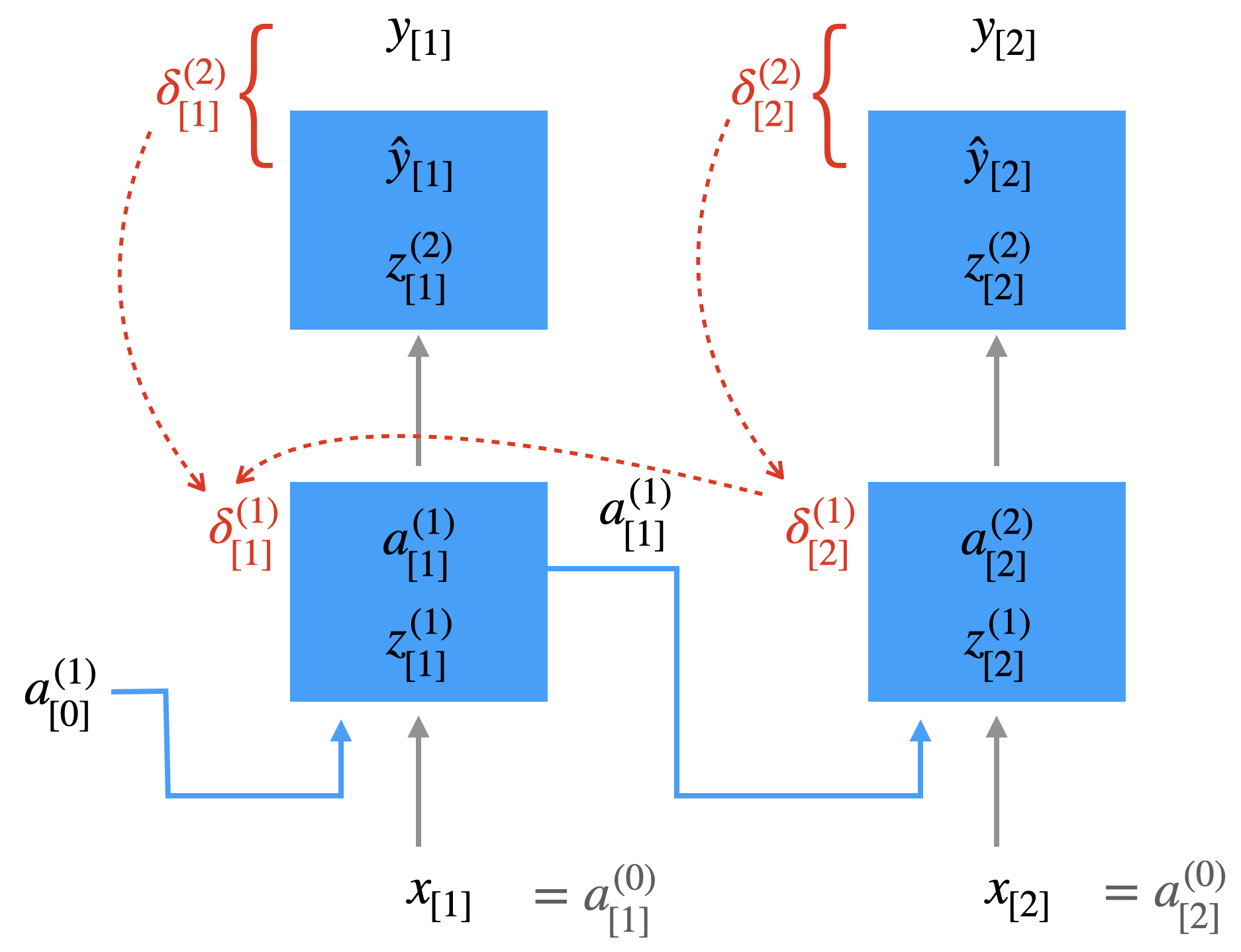
Im zweiten Schritt werden die \(\Delta w\) mit Hilfe der \(\delta\)-Werte berechnet. Beim herkömmlichen Backprop:
\[ \begin{align} \Delta w_{i,j}^{(2)} &= - \frac{\partial J}{\partial w_{i,j}^{(2)}} = - a_j^{(1)} \: \delta_i^{(2)} \\[2mm] \Delta w_{i,j}^{(1)} &= - \frac{\partial J}{\partial w_{i,j}^{(1)}} = - a_j^{(0)} \: \delta_i^{(1)} \end{align} \]
In Vektorschreibweise (und mit Zeitschritt):
\[ \begin{align} \Delta W^{(2)}_{[t]} &= - \delta^{(2)}_{[t]} \: (a^{(1)}_{[t]})^T\\[4mm] \Delta W^{(1)}_{[t]} &= - \delta^{(1)}_{[t]} \: (a^{(0)}_{[t]})^T = - \delta^{(1)}_{[t]} \: (x_{[t]})^T \tag{*} \end{align} \]
Im Unterschied zu BP müssen wie bei BPTT Formel (*) ändern: die \(\delta^{(1)}\)-Werte gehen in die Änderung von sowohl \(W^{(1)}\) als auch \(U\) ein. Wir ersetzen also Formel (*) durch (**).
\[ [\Delta W^{(1)}_{[t]}; \Delta U_{[t]}] = - \delta^{(1)}_{[t]} \: \left[ \begin{array}{c} x_{[t]} \\[2mm] a^{(1)}_{[t-1]} \end{array} \right]^T \tag{**} \]
Verarbeitung über eine Sequenz
Jetzt müssen wir uns noch einmal vergegenwärtigen, dass wir im Training immer eine Sequenz (z.B. von Wörtern) eingeben, also \(x_{[1]}, x_{[2]}, x_{[3]}, \ldots, x_{[N_x]}\). Bei der (Vorwärts-)Verarbeitung einer solchen Sequenz bleiben die Gewichte in unseren Matrizen \(W^l\) und \(U\) natürlich fix. Bei Backpropagation (BPTT) berechnen wir aber Anpassungswerte - also \(\Delta W^l_{[t]}\) und \(\Delta U_{[t]}\) - für jeden Zeitschritt. Das Update summiert erst alle Deltas und mittelt über alle Zeitschritte, bevor die Gewichte angepasst werden.

Vanishing Gradient
Das wichtigste Konzept hinter Backpropagation (und auch hinter BPTT) ist der Gradient, denn dieser ist für die Gewichtsänderung verantwortlich:
\[ \Delta w_{i,j}^{(l)} = - \frac{\partial J}{\partial w_{i,j}^{(l)}} = - a_j^{(l)} \: \delta_i^{(l+1)} \]
Der Gradient wiederum nutzt die Deltawerte und diese hängen teils von einer langen Kette von vorher berechneten Deltawerten ab. Bei vielen Multiplikationen hat man immer das Problem, dass Werte, die nur leicht von \(1\) abweichen, also etwas kleiner oder größer sind, das Gesamtprodukt sehr schnell gegen Null geht oder sehr groß wird.
Oft ist es so, dass die Werte zu klein werden, so dass sie keinerlei Einfluss mehr auf die Gewichte haben. Man spricht hier vom Vanishing Gradient Problem, das wir schon beim ResNet angesprochen haben (analog spricht man vom Exploding Gradient Problem bei Werten \(>1\)). Es verwundert auch nicht, dass dieses Problem sowohl bei vielen Schichten und eben auch bei langen Sequenzen auftaucht, denn die beiden Situationen sind - wie wir oben gesehen haben - äquivalent.
Ein schöner Artikel dazu ist Recurrent Neural Networks Tutorial, Part 3 – Backpropagation Through Time and Vanishing Gradients von Denny Britz (2015).
15.1.6 Bidirektionale RNN (BRNN)
Das vorgestellte Elman-Netz erlaubt es, dass zum Zeitpunkt \(t\) Informationen von vorherigen Eingaben \(1, \ldots, t-1\) mit berücksichtigt werden können. In sprachlichen Äußerungen kommt aber auch oft vor, dass der zukünftige Kontext \(t+1, \ldots, T_x\) eine Rolle spielt.
Will man hier das eingeklammerte Wort vorhersagen, spielt jeweils das fett gesetzte Wort eine Rolle, das in der Zukunft liegt:
Er holte sein [Auto] und fuhr nach München.
Er holte sein [Tagebuch] und schrieb los.
Ein Bidirektionales RNN (BRNN) leitet die Aktivierung der versteckten Schicht \(a_{[t]}\) nicht nur vorwärts weiter, sondern auch rückwärts. Das setzt natürlich voraus, dass der komplette Input (z.b. der vollständige Satz oder ein komplettes Dokument) vollständig durchlaufen werden kann. Das BRNN vollzieht bei der Forward Propagation zwei Durchläufe.
Erster Durchlauf
Wir sehen uns das anhand eines einfachen Beispiels mit drei Zeitschritten an (z.B. drei Wörter). Wir führen mit der Eingabe \(x_{[1]},x_{[2]},x_{[3]}\) zunächst die normale Forward Propagation durch und speisen jeweils \(a_{[t-1]}\) mit in die versteckte Schicht ein.
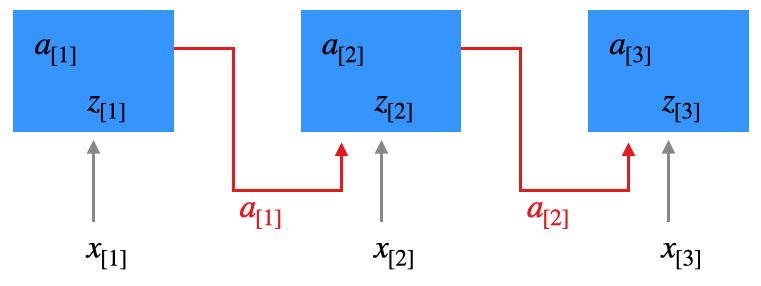
Zweiter Durchlauf
Jetzt rechnen wir rückwärts. Wir berechnen eine zweite Aktivierung \(\tilde{a}_{[t]}\) basierend auf der Eingabe \(x_{[t]}\) und dem zukünftigen Kontext \(\tilde{a}_{[t+1]}\), wobei der initiale Kontext \(\tilde{a}_{[3]} := a_{[3]}\). Man beachte, dass wir trotz der Rückwärtsverarbeitung immer noch von Forward Propagation sprechen, da wir hier kein Lernen durchführen, sondern Aktivierungen berechnen. Am Ende dieses Durchlaufs haben wir in der Zwischenschicht für jeden Zeitschritt zwei Aktivierungsvektoren \(a_{[t]}\) und \(\tilde{a}_{[t]}\) (für die Berechnung von \(\tilde{a}_{[t]}\) benötigt man auch ein separates \(\tilde{z}_{[t]}\), das hier nicht dargestellt ist):
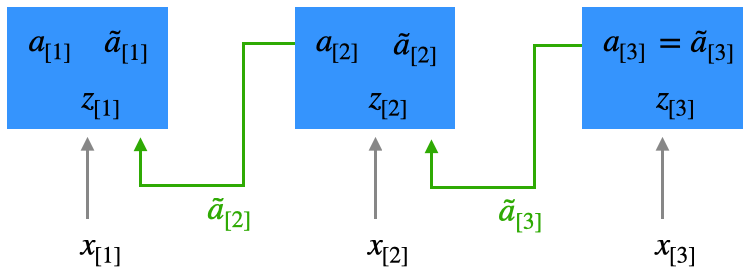
Die beiden Aktivierungen enthalten jeweils den Kontext aus der Vergangenheit (\(a\)) und der Zukunft (\(\tilde{a}\)). Für die Berechnung des Outputs werden beide Aktivierungen benutzt, indem die zwei Vektoren aneinander gehängt werden. Wir haben hier auch eine entsprechend dimensionierte Gewichtsmatrix. Das dargestellte Szenario ist Many-to-Many.
Ein Many-to-One-Szenario ist im Grunde nicht sinnvoll, da die Aktivierungen des zweiten Durchlaufs gar nicht in die Berechnung des letzten \(\hat{y}\) (hier also \(\hat{y}_{[3]}\)) einfließen können.
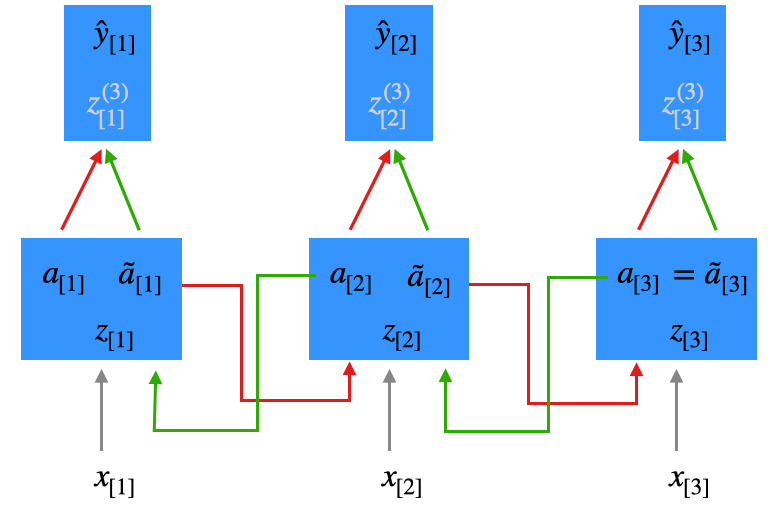
Beim Lernen können wir Backpropagation Through Time (BPTT) entsprechend erweitern. Einmal wird BPTT wie bereits beschrieben angewendet (s.o.). Anschließend wird BPTT für die Rückrichtung angewendet. Sie können sich dazu vorstellen, dass man \(a\) und \(\tilde{a}\) getrennt behandelt. Die Gewichtsmatrizen kann man ebenfalls in zwei Teile \(W^{(l)}\) und \(U^{(l)}\) trennen und bei BPTT entsprechend anpassen.
15.2 RNN mit Gated Units
Ein RNN realisiert mit den rekurrenten Verbindungen eine Art Gedächtnis, da die Aktivierung in Zeitschritt \(t\) in die Verarbeitung im nächsten Zeitschritt \(t+1\) mit eingeht, wie man hier nochmal sieht:
Man kann sich - auch ohne Kenntnis des Vanishing Gradient Problems - vorstellen, dass Abhängigkeiten über mehrere Zeitschritte schwierig zu lernen sind, weil Wichtiges verblasst und Unwichtiges mitgeschleppt wird.
Die Grundidee von “Gated Units” wie GRU oder LSTM ist es, diesen Informationskanal der rekurrenten Verbindungen (in der Abb. rot) zu verwalten bzw. zu steuern: Irrelevante Informationen sollten gelöscht/unterdrückt werden können und relevante Information sollten effizient enkodiert werden können.
15.2.1 GRU: Gated Recurrent Units
Das Konzept der Gated Recurrent Units (GRU) stammt aus dem Jahr 2014 im Zuge des Gated Recursive CNN aus der Arbeitsgruppe von Yoshua Bengio, Universität Montréal (Chung et al. 2014; Cho et al. 2014). Es ist somit deutlich jünger als das LSTM-Konzept, das bereits 1997 vorgestellt wurde (Hochreiter and Schmidhuber 1997). Da GRUs etwas einfacher aufgebaut sind, schauen wir sie uns als erstes an. Wer in das Originalpaper reinschauen möchte: Ich empfehle Chung et al. (2014).
Wir stellen uns zunächst ein NN mit nur einer versteckten Schicht vor. Die Aktivierung der versteckten Schicht \(a_{[t]}\) zum Zeitpunkt \(t\) kann man als Kontext für das Netz zum Zeitpunkt \(t+1\) verstehen. Die Grundidee ist jetzt, dieses Signal \(a_{[t]}\) mit Hilfe von sogenannten Gates zu steuern: Man filtert Irrelevantes heraus, man verstärkt wichtige Aspekte. Dazu wird ein Kandidat \(\tilde{a}\) berechnet, der einen neuen möglichen Kontext repräsentiert, und anschließend wird gesteuert, inwieweit dieser Kandidat verwendet wird oder ob der alte Kontext weiterverwendet wird.
Beim GRU gibt es zwei Gates:
- Vektor \(r\) ist das Reset-Gate, das dabei hilft, den neuen Kontext zu definieren, indem es den alten Kontext filtert
- Vektor \(u\) ist das Update-Gate, das entscheidet, ob alter oder neuer Kontext weitergeleitet wird (bzw. zu welchem Grad)
Diese beiden Vektoren werden mit eigenen Gewichten angelernt.
Wir definieren zunächst die zwei Gates:
\[ \begin{align} r &:= \sigma\, (W_r \left[\begin{array}{c} a_{[t-1]}\\ x_{[t]}\end{array}\right] + b_r) \tag{Reset}\\[2mm] u &:= \sigma\, (W_u \left[\begin{array}{c} a_{[t-1]}\\ x_{[t]}\end{array}\right] + b_u) \tag{Update} \end{align} \]
Hier bezieht sich \(\sigma\) (griechischer Kleinbuchstabe Sigma) auf die alt bekannte logistische Funktion (Sigmoid-Funktion), die den Wertebereich \([0, 1]\) hat.
\[ \sigma(z) = \frac{1}{1+e^{-z}} \]
Der resultierenden Vektoren können also Komponenten auslöschen (mit 0) oder erhalten (mit 1) oder mit Zwischenwerten abschwächen.
Schematisch kann man den Zusammenhang so darstellen:
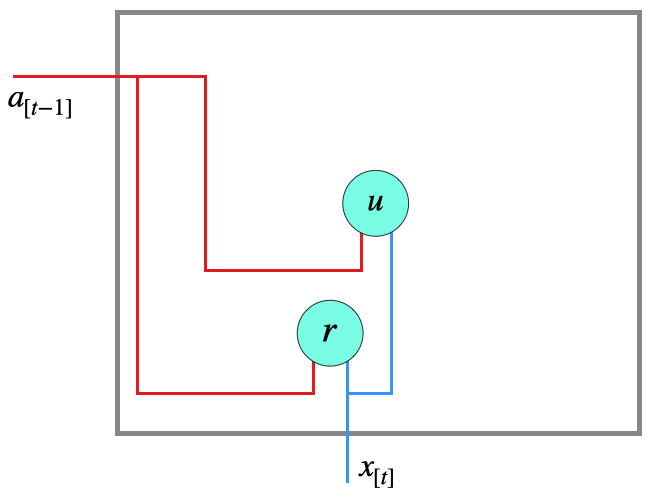
Jetzt können wir den Kandidaten \(\tilde{a}\) für einen neuen Kontext berechnen:
\[ \tilde{a} := \tanh (W_a \left[\begin{array}{c} r \odot a_{[t-1]}\\ x_{[t]}\end{array}\right] + b_a) \tag{Kandidat} \]
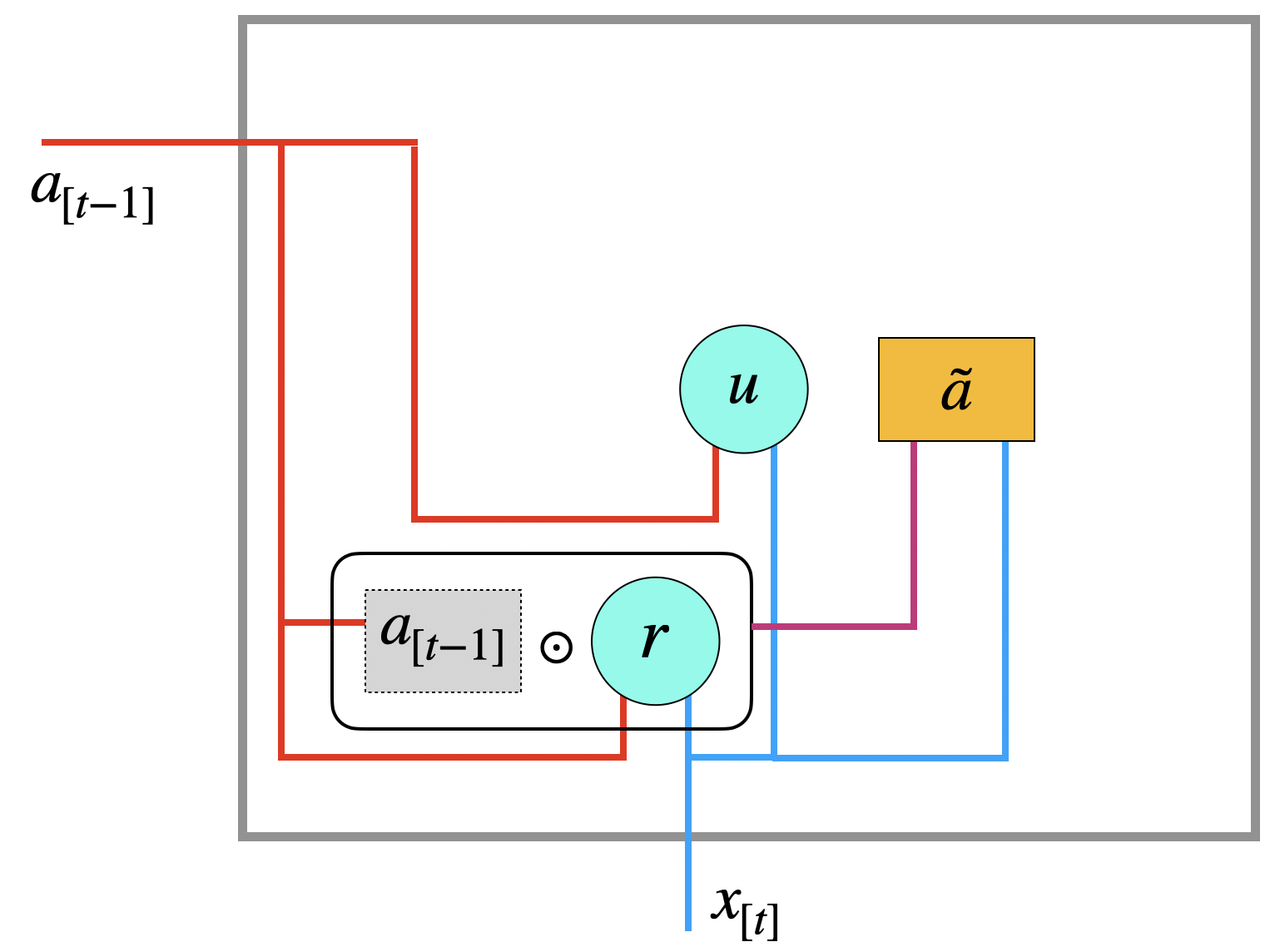
Um \(\tilde{a}\) zu berechnen wird erst der alte Zustand \(a_{[t-1]}\) mit Hilfe des Reset-Gates \(r\) gefiltert (mit dem Hadamard-Operator \(\odot\)). Der Name deutet darauf hin, dass einzelne Komponenten auf Null gesetzt (Reset) oder zumindest abgeschwächt werden können. Dann wird der gefilterte Zustand mit der Eingabe \(x_{[t]}\) und den (gelernten) Gewichten verarbeitet.
Die Idee hinter dem möglichen neuen Kontext \(\tilde{a}\) ist, wichtige Informationen zu akzentuieren, indem irrelevante Informationen gelöscht werden. Man könnte sich z.B. einen Genus (männlich/weiblich) oder eine Numerusinformation (singular/plural) vorstellen, die am Satzende beim Verb wichtig ist. Aktivierungsfunktion ist hier der \(\tanh\), der in den Bereich \([-1, 1]\) abbildet.
Im letzten Schritt wird aber noch über das Update-Gate \(u\) entschieden, ob dieser neue Zustand \(\tilde{a}\) verwendet wird bzw. in welchem Umfang oder ob der alte Kontext \(a_{[t-1]}\) weiterverwendet wird.
\[ a_{[t]} := u \odot \tilde{a} + (1 - u) \odot a_{[t-1]} \]
Da Update-Gate \(u\) ein Vektor mit kontinuierlichen Werten \(\in [0, 1]\) ist, werden die beiden Vektoren komplementär gemischt (z.B. 30% zu 70%), man nennt das eine Linearkombination. Wichtig ist hier, dass der alte Vektor \(a_{[t-1]}\) weitergereicht werden könnte, sollte er wichtige Informationen enthalten. Anderfalls wird der neu erstellte Kontextvektor \(\tilde{a}\) verwendet (wobei auch dieser auf dem alten Kontext beruht, aber dieser vorher gefiltert wurde). Das Update-Gate gibt dem Netz aber die Möglichkeit den neuen Kandidaten komplett zu ignorieren.
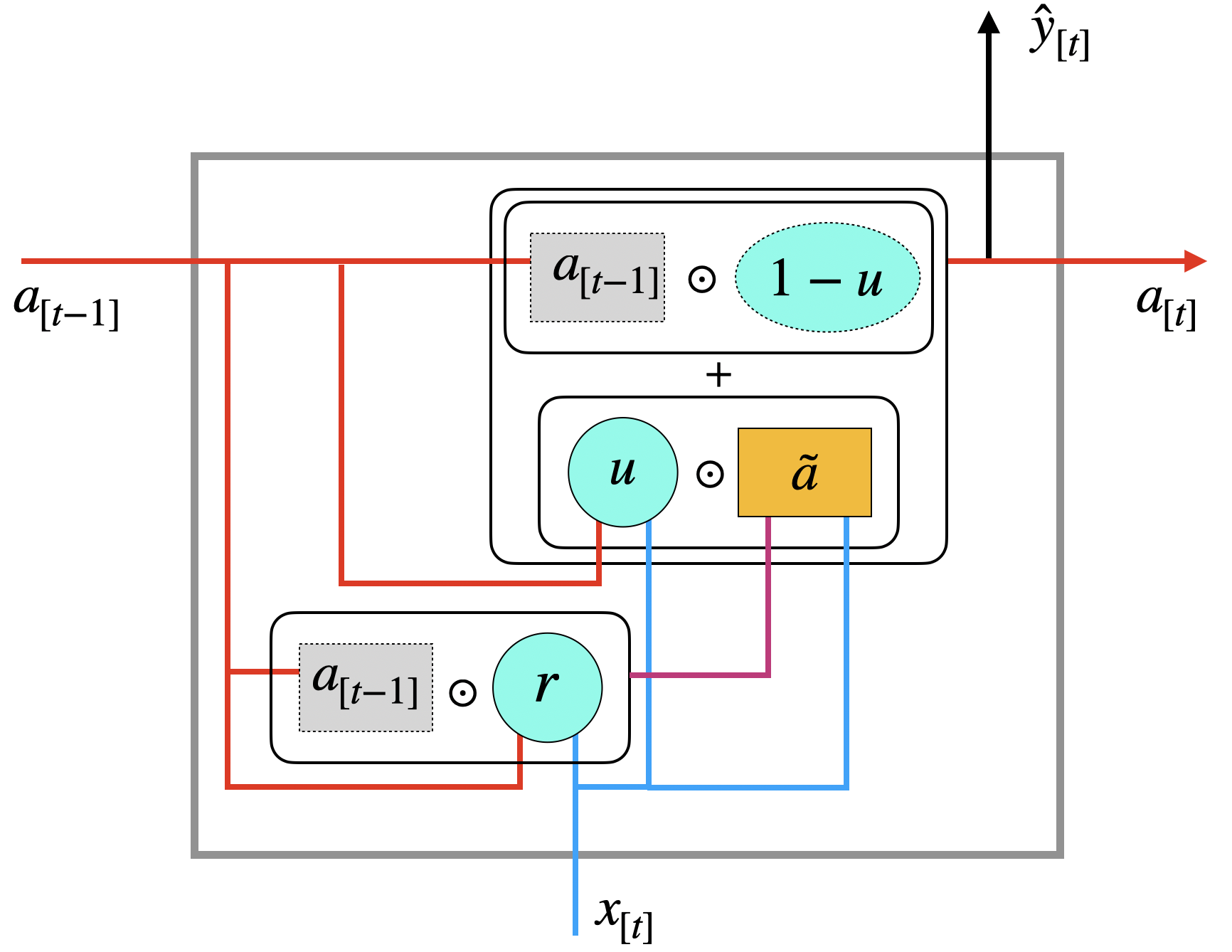
Die Ausgabe \(a_{[t]}\) ist dann der neue Kontext und die Eingabe für den nächsten Zeitschritt. Zusätzlich kann es sein, dass noch weitere Schichten vorhanden sind, dann ist das auch der Input für die nächste Schicht. Es kann auch sein, dass dies bereits die Ausgabeschicht ist, dann ist \(\hat{y}_{[t]} = a_{[t]}\), eventuell wird vorher noch die Softmax-Funktion angewandt.
Darstellungen von GRU-Netzen finden Sie auch in den Artikeln Illustrated Guide to LSTM’s and GRU’s: A step by step explanation von Michael Phi und Understanding GRU Networks von Simeon Kostadinov.
15.2.2 LSTM: Long Short-Term Memory
Das LSTM-Netz wurde bereits 1997 von Sepp Hochreiter und Jürgen Schmidhuber an der TU München entwickelt (Hochreiter and Schmidhuber 1997; Schmidhuber 2015) und basiert auf der Diplomarbeit von Hochreiter (1991). Man kann die oben vorgestellten GRU-Einheiten auch als vereinfachte Version von LSTM-Einheiten betrachten.
Die zwei Hauptunterschiede sind:
- beim GRU ist das Signal \(a_{[t]}\) sowohl die Aktivierung der Zwischenschicht als auch der Kontext für den nächsten Zeitschritt; beim LSTM unterscheidet man zwischen Aktivierung \(a_{[t]}\) ein einem separatem Kontext \(c_{[t]}\), dabei ist die Aktivierung \(a_{[t]}\) ein “gefilterter” Kontext \(c_{[t]}\).
- es gibt beim LSTM drei Gates \(u\), \(f\) und \(o\); beim GRU gibt es nur zwei Gates
In einem LSTM haben wir die drei Gates: Update, Forget und Output:
\[ \begin{align} u &:= \sigma\, (W_u \left[\begin{array}{c} a_{[t-1]}\\ x_{[t]}\end{array}\right] + b_u) \tag{Update}\\[2mm] f &:= \sigma\, (W_f \left[\begin{array}{c} a_{[t-1]}\\ x_{[t]}\end{array}\right] + b_f) \tag{Forget}\\[2mm] o &:= \sigma\, (W_o \left[\begin{array}{c} a_{[t-1]}\\ x_{[t]}\end{array}\right] + b_o) \tag{Output} \end{align} \]
Wir haben auch im LSTM eine Kandidatenzelle für einen neuen Kontext, die wir \(\tilde{c}\) nennen. Hier wird der \(a\)-Wert nicht (wie beim GRU) gefiltert.
\[ \tilde{c} := \tanh (W_c \left[\begin{array}{c} a_{[t-1]}\\ x_{[t]}\end{array}\right] + b_c) \tag{Kandidat} \]
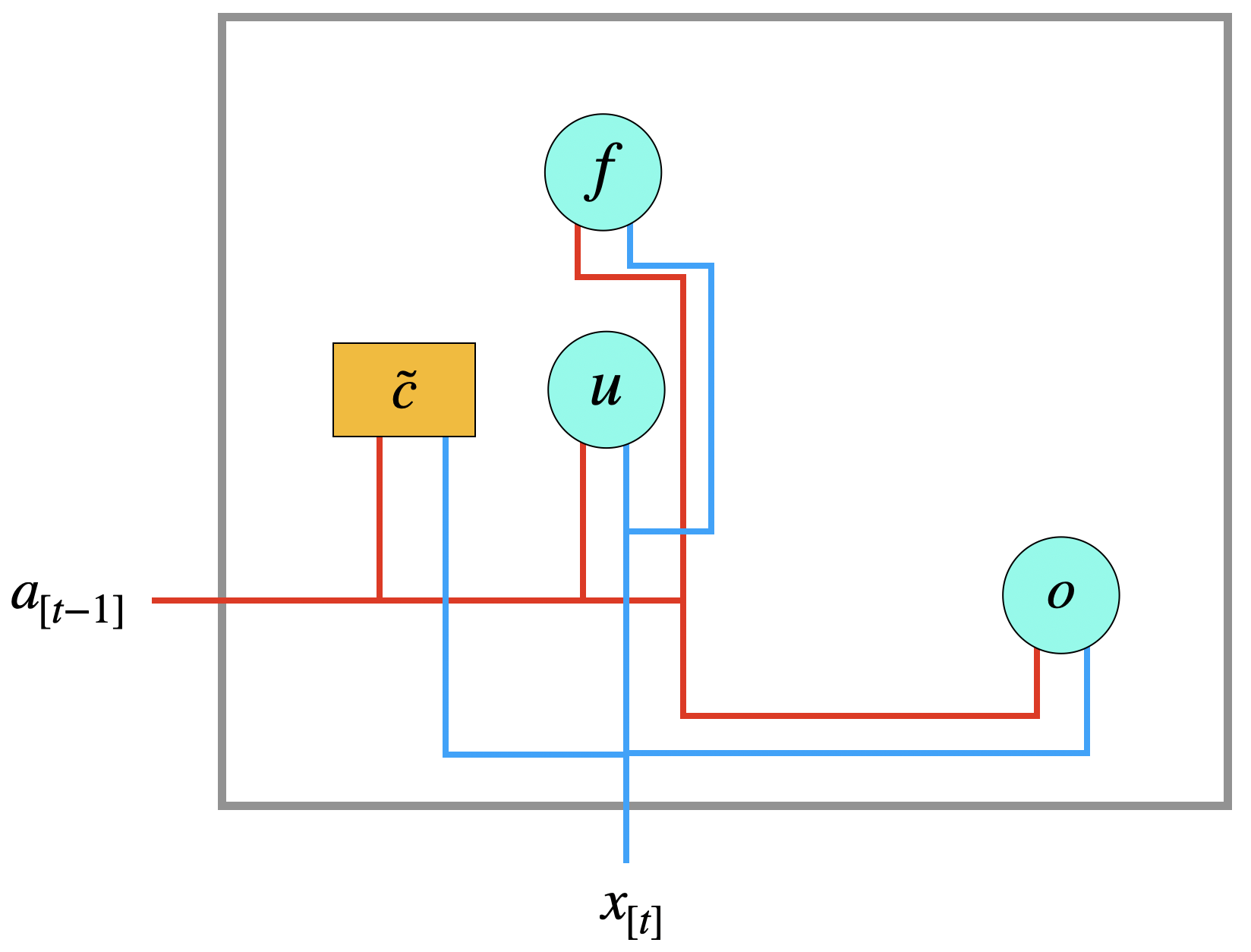
Beim LSTM hat jede Schicht einen Kontextvektor \(c_{[t]}\), der im nächsten Zeitschritt wieder eingespeist wird. Im LSTM wird zunächst ein Kandidat \(\tilde{c}\) berechnet, wie oben gezeigt. Ob das neue \(\tilde{c}\) weitergeleitet wird oder das alte \(c_{[t-1]}\), bestimmen das Update-Gate und das Forget-Gate:
\[ c_{[t]} := u \odot \tilde{c} + f \odot c_{[t-1]} \]
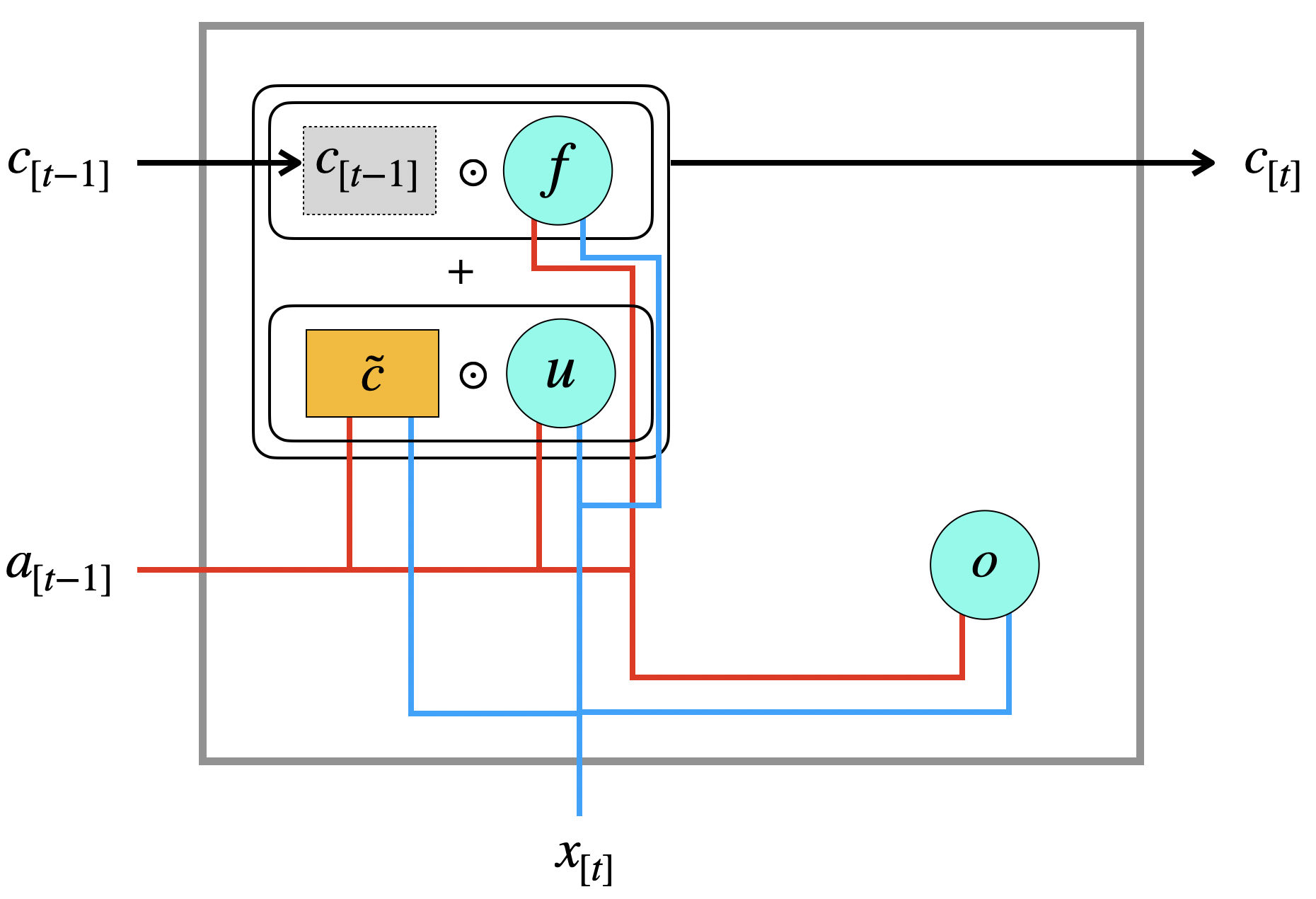
Man beachte den Unterschied zum GRU: statt einer Linearkombination (\(u\) und \(1-u\)) werden hier zwei Vektoren, \(u\) und \(f\) verwendet. Das heißt, zwei separate Werte bestimmen die Anteile von altem und neuem Kandidaten. Das \(f\) bestimmt, wie viel vom alten Wert vergessen werden soll.
Die Aktivierung der Schicht - also \(a_{[t]}\) - bestimmt das Output-Gate \(o\), indem es den Kontext “filtert”:
\[ a_{[t]} = o \odot c_{[t]} \]
Aus der Aktivierung ergibt sich auch wie gewohnt die Ausgabe \(\hat{y}_{[t]}\).
Hier sehen wir jetzt die vollständige LSTM-Schicht:
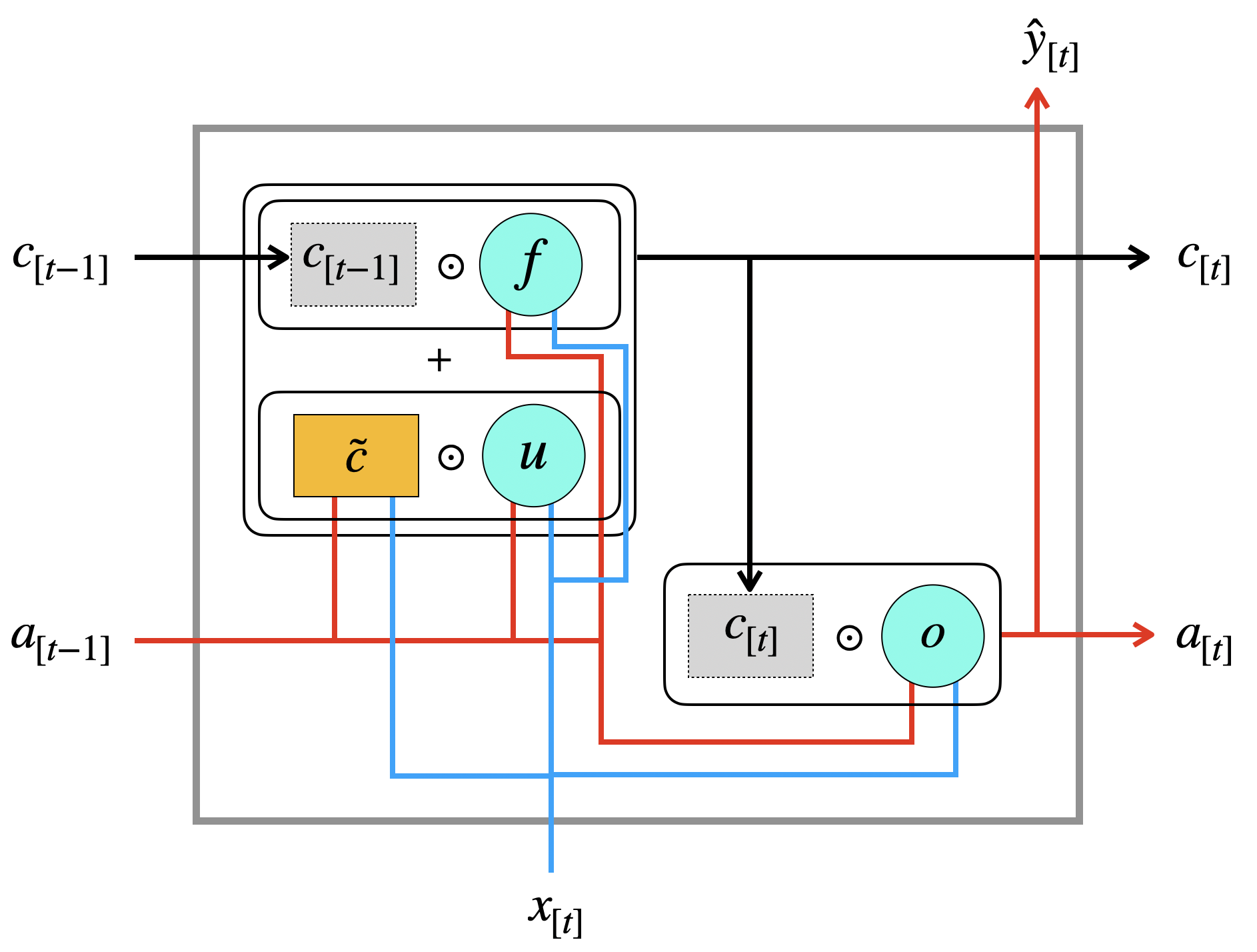
Der wichtige Unterschied ist ja offensichtlich die Trennung von \(c_{[t]}\) und \(a_{[t]}\). In der Abbildung sieht man, dass das \(a_{[t]}\) im Grunde eine “gefilterte” Version von \(c_{[t]}\) ist. Man könnte das so verstehen, dass man mit \(c_{[t]}\) einen “globaleren” Kontext hat, den man über lange Zeit behält, wohingegen Informationen, die direkt für die aktuelle Ausgabe \(\hat{y}_{[t]}\) relevant sind, mit dem Output-Gate herausgefiltert werden können, ohne den globalen Kontext zu “stören”.
Schauen Sie sich gern auch den viel zitierten Blogartikel Understanding LSTM Networks von Christopher Olah oder den Illustrated Guide to LSTM’s and GRU’s von Michael Phi an.
15.3 Keras 5: Rekurrente Netze und Sentiment Analysis
Der Erfinder von Keras, François Chollet, rief das Projekt Keras auch deshalb ins Leben rief, weil es seinerzeit keine guten Softwareframeworks für RNNs gab. Insofern sind RNNs wie LSTM und GRU in Keras besonders gut behandelt.
Um RNNs auszuprobieren, verwenden wir den Datensatz IMDB (Abschnitt 14.6.3). Dort liegen textuelle Rezensionen von Filmen vor, die in einer binären Klassifikationsaufgabe in positiv und negativ kategorisiert werden sollen.
Für diese Aufgabenstellung benötigen wir eine Many-to-One-Konstruktion, da der Satz (Sequenz) komplett eingespeist wird und ein einziger Output (positiv/negativ) erwartet wird.
Wir werden hier die Netz-Typen Elman-Netz, GRU und LSTM betrachten. Außerdem sehen wir uns an, wie wir Bidirektionalität einbauen können.
Lesenswert sind der Keras-Guide Working with RNNs und die Keras-APIs der rekurrenten Schichten.
Parameter
Zunächst einige Parameter für alle Netze.
Hilfsfunktion
Eine Hilfsfunktion zur Visualisierung der Trainingshistorie:
# Zwei Abbildungen: Loss (train/val) und Accuracy (train/val)
import matplotlib.pyplot as plt
def show_loss_acc(h):
plt.figure(figsize=(12, 8))
plt.subplot(2, 2, 1)
plt.plot(h['loss'], label='train loss')
plt.plot(h['val_loss'], label='val loss')
plt.legend()
plt.subplot(2, 2, 2)
plt.plot(h['acc'], label='train acc')
plt.plot(h['val_acc'], label='val acc')
plt.legend()
plt.show()15.3.1 Daten: IMDB-Datensatz
Wir lesen die IMDB-Daten ein, die mit Keras ausgeliefert werden (Abschnitt 14.6.3).
Bei der Funktion load_data können wir mit num_words das Vokabular beschränken, hier beschränken uns auf 10000 (häufigsten) Wörter.
from tensorflow.keras.datasets import imdb
from tensorflow.keras.preprocessing import sequence
(train_x, train_y), (test_x, test_y) = imdb.load_data(num_words=num_words)
print(f'{train_x.shape}, {test_x.shape}')(25000,), (25000,)Die Struktur der Daten ist eigentümlich. Es handelt sich um einen NumPy-Array von Listen.
type(train_x)numpy.ndarraytype(train_x[0])listSchauen wir uns die ersten zwei Elemente der Trainingsdaten an:
train_x[:2]array([list([1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65, 458, 4468, 66, 3941, 4, 173, 36, 256, 5, 25, 100, 43, 838, 112, 50, 670, 2, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167, 2, 336, 385, 39, 4, 172, 4536, 1111, 17, 546, 38, 13, 447, 4, 192, 50, 16, 6, 147, 2025, 19, 14, 22, 4, 1920, 4613, 469, 4, 22, 71, 87, 12, 16, 43, 530, 38, 76, 15, 13, 1247, 4, 22, 17, 515, 17, 12, 16, 626, 18, 2, 5, 62, 386, 12, 8, 316, 8, 106, 5, 4, 2223, 5244, 16, 480, 66, 3785, 33, 4, 130, 12, 16, 38, 619, 5, 25, 124, 51, 36, 135, 48, 25, 1415, 33, 6, 22, 12, 215, 28, 77, 52, 5, 14, 407, 16, 82, 2, 8, 4, 107, 117, 5952, 15, 256, 4, 2, 7, 3766, 5, 723, 36, 71, 43, 530, 476, 26, 400, 317, 46, 7, 4, 2, 1029, 13, 104, 88, 4, 381, 15, 297, 98, 32, 2071, 56, 26, 141, 6, 194, 7486, 18, 4, 226, 22, 21, 134, 476, 26, 480, 5, 144, 30, 5535, 18, 51, 36, 28, 224, 92, 25, 104, 4, 226, 65, 16, 38, 1334, 88, 12, 16, 283, 5, 16, 4472, 113, 103, 32, 15, 16, 5345, 19, 178, 32]),
list([1, 194, 1153, 194, 8255, 78, 228, 5, 6, 1463, 4369, 5012, 134, 26, 4, 715, 8, 118, 1634, 14, 394, 20, 13, 119, 954, 189, 102, 5, 207, 110, 3103, 21, 14, 69, 188, 8, 30, 23, 7, 4, 249, 126, 93, 4, 114, 9, 2300, 1523, 5, 647, 4, 116, 9, 35, 8163, 4, 229, 9, 340, 1322, 4, 118, 9, 4, 130, 4901, 19, 4, 1002, 5, 89, 29, 952, 46, 37, 4, 455, 9, 45, 43, 38, 1543, 1905, 398, 4, 1649, 26, 6853, 5, 163, 11, 3215, 2, 4, 1153, 9, 194, 775, 7, 8255, 2, 349, 2637, 148, 605, 2, 8003, 15, 123, 125, 68, 2, 6853, 15, 349, 165, 4362, 98, 5, 4, 228, 9, 43, 2, 1157, 15, 299, 120, 5, 120, 174, 11, 220, 175, 136, 50, 9, 4373, 228, 8255, 5, 2, 656, 245, 2350, 5, 4, 9837, 131, 152, 491, 18, 2, 32, 7464, 1212, 14, 9, 6, 371, 78, 22, 625, 64, 1382, 9, 8, 168, 145, 23, 4, 1690, 15, 16, 4, 1355, 5, 28, 6, 52, 154, 462, 33, 89, 78, 285, 16, 145, 95])],
dtype=object)Wir sehen zwei Python-Listen unterschiedlicher Länge. Jede Liste entspricht einem Text, jede Zahl entspricht einem Wort. Wir schauen uns an, wie lang die ersten 5 Listen sind.
for i in range(5):
print(len(train_x[i]))218
189
141
550
147Offensichtlich sind alle Texte unterschiedlich lang.
Jetzt sehen wir uns die Label an:
train_y[:10]array([1, 0, 0, 1, 0, 0, 1, 0, 1, 0])Die Funktion pad_sequences schneiden die Reviews auf eine fixe Länge von 500 Wörtern. Ist ein Text kürzer, wird er mit Nullen aufgefüllt (deshalb “pad”).
train_x = sequence.pad_sequences(train_x, maxlen=cutoff)
test_x = sequence.pad_sequences(test_x, maxlen=cutoff)
print(f'{train_x.shape}, {test_x.shape}')(25000, 500), (25000, 500)Wir sehen uns an, wie das funktioniert hat.
train_x[:2]array([[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 1, 14, 22, 16,
43, 530, 973, 1622, 1385, 65, 458, 4468, 66, 3941, 4,
173, 36, 256, 5, 25, 100, 43, 838, 112, 50, 670,
2, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167,
2, 336, 385, 39, 4, 172, 4536, 1111, 17, 546, 38,
13, 447, 4, 192, 50, 16, 6, 147, 2025, 19, 14,
22, 4, 1920, 4613, 469, 4, 22, 71, 87, 12, 16,
43, 530, 38, 76, 15, 13, 1247, 4, 22, 17, 515,
17, 12, 16, 626, 18, 2, 5, 62, 386, 12, 8,
316, 8, 106, 5, 4, 2223, 5244, 16, 480, 66, 3785,
33, 4, 130, 12, 16, 38, 619, 5, 25, 124, 51,
36, 135, 48, 25, 1415, 33, 6, 22, 12, 215, 28,
77, 52, 5, 14, 407, 16, 82, 2, 8, 4, 107,
117, 5952, 15, 256, 4, 2, 7, 3766, 5, 723, 36,
71, 43, 530, 476, 26, 400, 317, 46, 7, 4, 2,
1029, 13, 104, 88, 4, 381, 15, 297, 98, 32, 2071,
56, 26, 141, 6, 194, 7486, 18, 4, 226, 22, 21,
134, 476, 26, 480, 5, 144, 30, 5535, 18, 51, 36,
28, 224, 92, 25, 104, 4, 226, 65, 16, 38, 1334,
88, 12, 16, 283, 5, 16, 4472, 113, 103, 32, 15,
16, 5345, 19, 178, 32],
[ 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 1, 194, 1153, 194, 8255, 78, 228, 5,
6, 1463, 4369, 5012, 134, 26, 4, 715, 8, 118, 1634,
14, 394, 20, 13, 119, 954, 189, 102, 5, 207, 110,
3103, 21, 14, 69, 188, 8, 30, 23, 7, 4, 249,
126, 93, 4, 114, 9, 2300, 1523, 5, 647, 4, 116,
9, 35, 8163, 4, 229, 9, 340, 1322, 4, 118, 9,
4, 130, 4901, 19, 4, 1002, 5, 89, 29, 952, 46,
37, 4, 455, 9, 45, 43, 38, 1543, 1905, 398, 4,
1649, 26, 6853, 5, 163, 11, 3215, 2, 4, 1153, 9,
194, 775, 7, 8255, 2, 349, 2637, 148, 605, 2, 8003,
15, 123, 125, 68, 2, 6853, 15, 349, 165, 4362, 98,
5, 4, 228, 9, 43, 2, 1157, 15, 299, 120, 5,
120, 174, 11, 220, 175, 136, 50, 9, 4373, 228, 8255,
5, 2, 656, 245, 2350, 5, 4, 9837, 131, 152, 491,
18, 2, 32, 7464, 1212, 14, 9, 6, 371, 78, 22,
625, 64, 1382, 9, 8, 168, 145, 23, 4, 1690, 15,
16, 4, 1355, 5, 28, 6, 52, 154, 462, 33, 89,
78, 285, 16, 145, 95]], dtype=int32)Und führen noch einen Sanity Check durch: Wie lang sind die ersten 5 Listen?
for i in range(5):
print(len(train_x[i]))500
500
500
500
500Die x-Daten (= Rezensionen) liegen jetzt als Vektoren der Länge 500 vor. Jeder Vektor enthält die Indexzahlen der Wörter in entsprechenden Reihenfolge des Textes.
Die Netze werden eine entsprechende Eingabeschicht haben, wo ein Embedding durch Lernen erzeugt wird.
15.3.2 Elman-Netz (SimpleRNN)
Wir beginnen mit einem einfachen RNN, dem Elman-Netz, das in Keras SimpleRNN heißt. Die erste Schicht ist vom Typ Embedding. Diese Schicht lernt eine Embedding-Matrix, die die Eingabe eines One-Hot-Vektors der Länge 10000 auf einen embedded Vektor der Länge 32 abbildet. Die 32 wird als Parameter übergeben und spiegelt den Grad der “Kompression” eines Worts wider.
Unsere Zwischenschicht enthält 32 Neuronen. Also Ausgabeaktivierung wählen wir die logistische Funktion.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, SimpleRNN, Dense
model = Sequential(name="SimpleRNN")
model.add(Embedding(num_words, 32))
model.add(SimpleRNN(32))
model.add(Dense(1, activation='sigmoid'))
model.summary()Model: "SimpleRNN"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, None, 32) 320000
_________________________________________________________________
simple_rnn (SimpleRNN) (None, 32) 2080
_________________________________________________________________
dense (Dense) (None, 1) 33
=================================================================
Total params: 322,113
Trainable params: 322,113
Non-trainable params: 0
_________________________________________________________________Training
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(train_x, train_y,
epochs=epochs,
validation_data=(test_x, test_y))Train on 25000 samples, validate on 25000 samples
Epoch 1/10
25000/25000 [==============================] - 158s 6ms/sample - loss: 0.5160 - acc: 0.7358 - val_loss: 0.4210 - val_acc: 0.8100
Epoch 2/10
25000/25000 [==============================] - 147s 6ms/sample - loss: 0.3461 - acc: 0.8580 - val_loss: 0.4273 - val_acc: 0.8026
Epoch 3/10
25000/25000 [==============================] - 141s 6ms/sample - loss: 0.3003 - acc: 0.8795 - val_loss: 0.3677 - val_acc: 0.8375
Epoch 4/10
25000/25000 [==============================] - 146s 6ms/sample - loss: 0.2737 - acc: 0.8933 - val_loss: 0.3843 - val_acc: 0.8530
Epoch 5/10
25000/25000 [==============================] - 142s 6ms/sample - loss: 0.2690 - acc: 0.8923 - val_loss: 0.3798 - val_acc: 0.8360
Epoch 6/10
25000/25000 [==============================] - 131s 5ms/sample - loss: 0.2228 - acc: 0.9148 - val_loss: 0.4315 - val_acc: 0.8011
Epoch 7/10
25000/25000 [==============================] - 138s 6ms/sample - loss: 0.1776 - acc: 0.9325 - val_loss: 0.4639 - val_acc: 0.8478
Epoch 8/10
25000/25000 [==============================] - 135s 5ms/sample - loss: 0.1563 - acc: 0.9405 - val_loss: 0.5189 - val_acc: 0.8430
Epoch 9/10
25000/25000 [==============================] - 136s 5ms/sample - loss: 0.1354 - acc: 0.9515 - val_loss: 0.5299 - val_acc: 0.8179
Epoch 10/10
25000/25000 [==============================] - 134s 5ms/sample - loss: 0.1158 - acc: 0.9589 - val_loss: 0.5310 - val_acc: 0.8410Trainingsverlauf
show_loss_acc(history.history)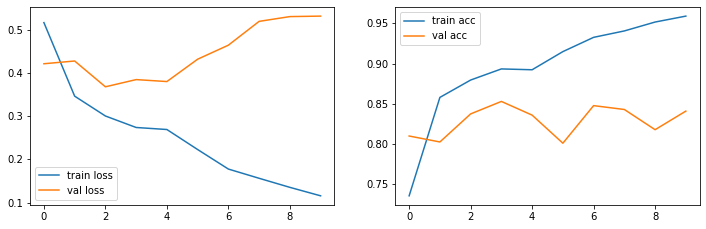
Ergebnisse
Das einfache RNN erzielt ca. 84% Accuracy auf den Testdaten und zwar nach der 4. Epoche.
15.3.3 Bidirektionales RNN
In Keras wird Bidirektionalität durch ein “Wrapper-Objekt” namens Bidirectional erreicht. So kann man beliebige rekurrente Schichten in bidirektionale Schichten ummünzen (auch z.B. LSTM oder GRU).
Siehe auch das Beispiel Bidirectional LSTM on IMDB von Chollet in Keras.
from tensorflow.keras.layers import Bidirectional
model = Sequential(name="BRNN")
model.add(Embedding(num_words, 32))
model.add(Bidirectional(SimpleRNN(32)))
model.add(Dense(1, activation='sigmoid'))
model.summary()Model: "BRNN"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_2 (Embedding) (None, None, 32) 320000
_________________________________________________________________
bidirectional (Bidirectional (None, 64) 4160
_________________________________________________________________
dense_1 (Dense) (None, 1) 65
=================================================================
Total params: 324,225
Trainable params: 324,225
Non-trainable params: 0
_________________________________________________________________Training
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(train_x, train_y,
epochs=epochs,
validation_data=(test_x, test_y))Train on 25000 samples, validate on 25000 samples
Epoch 1/10
25000/25000 [==============================] - 215s 9ms/sample - loss: 0.5248 - acc: 0.7181 - val_loss: 0.3919 - val_acc: 0.8312
Epoch 2/10
25000/25000 [==============================] - 249s 10ms/sample - loss: 0.3482 - acc: 0.8583 - val_loss: 0.4702 - val_acc: 0.7730
Epoch 3/10
25000/25000 [==============================] - 212s 8ms/sample - loss: 0.3233 - acc: 0.8718 - val_loss: 0.4120 - val_acc: 0.8422
Epoch 4/10
25000/25000 [==============================] - 199s 8ms/sample - loss: 0.3229 - acc: 0.8732 - val_loss: 0.3704 - val_acc: 0.8421
Epoch 5/10
25000/25000 [==============================] - 188s 8ms/sample - loss: 0.2863 - acc: 0.8874 - val_loss: 0.3461 - val_acc: 0.8580
Epoch 6/10
25000/25000 [==============================] - 187s 7ms/sample - loss: 0.2900 - acc: 0.8876 - val_loss: 0.4138 - val_acc: 0.8434
Epoch 7/10
25000/25000 [==============================] - 180s 7ms/sample - loss: 0.2723 - acc: 0.8940 - val_loss: 0.3697 - val_acc: 0.8424
Epoch 8/10
25000/25000 [==============================] - 181s 7ms/sample - loss: 0.2465 - acc: 0.9049 - val_loss: 0.3677 - val_acc: 0.8356
Epoch 9/10
25000/25000 [==============================] - 180s 7ms/sample - loss: 0.2488 - acc: 0.9036 - val_loss: 0.3772 - val_acc: 0.8383
Epoch 10/10
25000/25000 [==============================] - 173s 7ms/sample - loss: 0.2329 - acc: 0.9126 - val_loss: 0.3748 - val_acc: 0.8603Trainingsverlauf
show_loss_acc(history.history)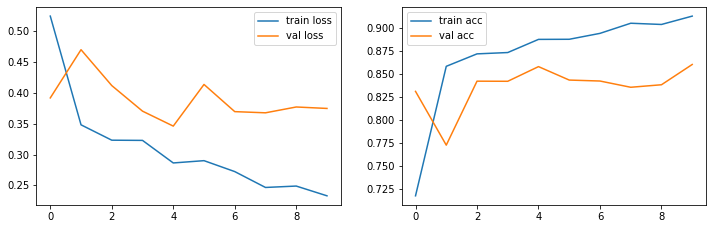
Ergebnisse
Das BRNN-Netz erzielt als ca. 86.0% Accuracy auf den Testdaten und in der 10. Epoche.
15.3.4 LSTM
Wir tauschen jetzt einfach die Schicht SimpleRNN durch eine LSTM-Schicht aus.
from tensorflow.keras.layers import LSTM
model = Sequential(name="LSTM")
model.add(Embedding(num_words, 32))
model.add(LSTM(32))
model.add(Dense(1, activation='sigmoid'))
model.summary()Model: "LSTM"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_2 (Embedding) (None, None, 32) 320000
_________________________________________________________________
lstm (LSTM) (None, 32) 8320
_________________________________________________________________
dense_1 (Dense) (None, 1) 33
=================================================================
Total params: 328,353
Trainable params: 328,353
Non-trainable params: 0
_________________________________________________________________Training
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(train_x, train_y,
epochs=epochs,
validation_data=(test_x, test_y))Train on 25000 samples, validate on 25000 samples
Epoch 1/10
25000/25000 [==============================] - 270s 11ms/sample - loss: 0.3991 - acc: 0.8241 - val_loss: 0.2905 - val_acc: 0.8828
Epoch 2/10
25000/25000 [==============================] - 227s 9ms/sample - loss: 0.2606 - acc: 0.8994 - val_loss: 0.2804 - val_acc: 0.8844
Epoch 3/10
25000/25000 [==============================] - 227s 9ms/sample - loss: 0.2211 - acc: 0.9167 - val_loss: 0.3275 - val_acc: 0.8796
Epoch 4/10
25000/25000 [==============================] - 226s 9ms/sample - loss: 0.2040 - acc: 0.9236 - val_loss: 0.3313 - val_acc: 0.8756
Epoch 5/10
25000/25000 [==============================] - 238s 10ms/sample - loss: 0.1874 - acc: 0.9294 - val_loss: 0.4380 - val_acc: 0.8257
Epoch 6/10
25000/25000 [==============================] - 236s 9ms/sample - loss: 0.1743 - acc: 0.9360 - val_loss: 0.6423 - val_acc: 0.8086
Epoch 7/10
25000/25000 [==============================] - 236s 9ms/sample - loss: 0.1666 - acc: 0.9386 - val_loss: 0.2955 - val_acc: 0.8822
Epoch 8/10
25000/25000 [==============================] - 227s 9ms/sample - loss: 0.1557 - acc: 0.9443 - val_loss: 0.2968 - val_acc: 0.8770
Epoch 9/10
25000/25000 [==============================] - 244s 10ms/sample - loss: 0.1474 - acc: 0.9460 - val_loss: 0.3052 - val_acc: 0.8790
Epoch 10/10
25000/25000 [==============================] - 243s 10ms/sample - loss: 0.1394 - acc: 0.9501 - val_loss: 0.3227 - val_acc: 0.8817Trainingsverlauf
show_loss_acc(history.history)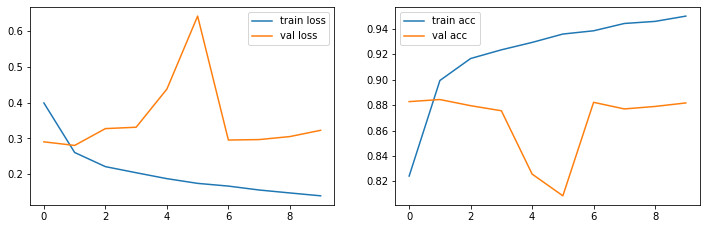
Ergebnisse
Das LSTM-Netz erzielt als ca. 88.2% Accuracy auf den Testdaten und zwar im Grunde schon nach der 1. Epoche.
15.3.5 GRU
Zu guter letzt noch ein Netz mit GRU-Schicht.
from tensorflow.keras.layers import GRU
model = Sequential(name="GRU")
model.add(Embedding(num_words, 32))
model.add(GRU(32))
model.add(Dense(1, activation='sigmoid'))
model.summary()Model: "GRU"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_4 (Embedding) (None, None, 32) 320000
_________________________________________________________________
gru (GRU) (None, 32) 6336
_________________________________________________________________
dense_2 (Dense) (None, 1) 33
=================================================================
Total params: 326,369
Trainable params: 326,369
Non-trainable params: 0
_________________________________________________________________Training
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(train_x, train_y,
epochs=epochs,
validation_data=(test_x, test_y))Train on 25000 samples, validate on 25000 samples
Epoch 1/10
25000/25000 [==============================] - 259s 10ms/sample - loss: 0.4238 - acc: 0.7992 - val_loss: 0.3128 - val_acc: 0.8694
Epoch 2/10
25000/25000 [==============================] - 251s 10ms/sample - loss: 0.2708 - acc: 0.8962 - val_loss: 0.2811 - val_acc: 0.8858
Epoch 3/10
25000/25000 [==============================] - 259s 10ms/sample - loss: 0.2209 - acc: 0.9167 - val_loss: 0.4687 - val_acc: 0.8343
Epoch 4/10
25000/25000 [==============================] - 235s 9ms/sample - loss: 0.1926 - acc: 0.9279 - val_loss: 0.3031 - val_acc: 0.8722
Epoch 5/10
25000/25000 [==============================] - 209s 8ms/sample - loss: 0.1695 - acc: 0.9377 - val_loss: 0.3769 - val_acc: 0.8640
Epoch 6/10
25000/25000 [==============================] - 209s 8ms/sample - loss: 0.1490 - acc: 0.9452 - val_loss: 0.3022 - val_acc: 0.8939
Epoch 7/10
25000/25000 [==============================] - 206s 8ms/sample - loss: 0.1351 - acc: 0.9520 - val_loss: 0.2701 - val_acc: 0.8943
Epoch 8/10
25000/25000 [==============================] - 262s 10ms/sample - loss: 0.1246 - acc: 0.9574 - val_loss: 0.3049 - val_acc: 0.8841
Epoch 9/10
25000/25000 [==============================] - 268s 11ms/sample - loss: 0.1138 - acc: 0.9600 - val_loss: 0.3223 - val_acc: 0.8837
Epoch 10/10
25000/25000 [==============================] - 268s 11ms/sample - loss: 0.1038 - acc: 0.9636 - val_loss: 0.3402 - val_acc: 0.8858Trainingsverlauf
show_loss_acc(history.history)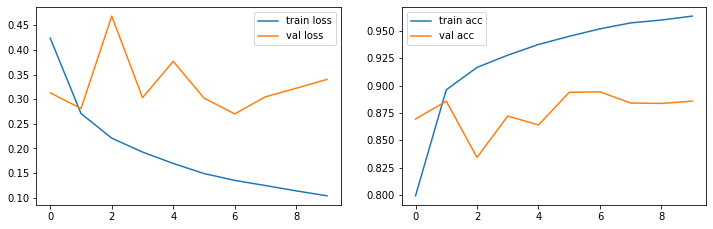
Ergebnisse
Das GRU-Netz erzielt als ca. 88.6% Accuracy auf den Testdaten und zwar im Grunde schon nach der 2. Epoche.
15.3.6 Bidirektionales GRU
Da unser GRU so gut abgeschnitten hat, probieren wir die bidirektionale Variante des GRU.
model = Sequential(name="BidirGRU")
model.add(Embedding(num_words, 32))
model.add(Bidirectional(GRU(32)))
model.add(Dense(1, activation='sigmoid'))
model.summary()Model: "BidirGRU"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_6 (Embedding) (None, None, 32) 320000
_________________________________________________________________
bidirectional_2 (Bidirection (None, 64) 12672
_________________________________________________________________
dense_4 (Dense) (None, 1) 65
=================================================================
Total params: 332,737
Trainable params: 332,737
Non-trainable params: 0
_________________________________________________________________Training
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(train_x, train_y,
epochs=epochs,
validation_data=(test_x, test_y))Train on 25000 samples, validate on 25000 samples
Epoch 1/10
25000/25000 [==============================] - 236s 9ms/sample - loss: 0.4372 - acc: 0.7886 - val_loss: 0.5580 - val_acc: 0.7377
Epoch 2/10
25000/25000 [==============================] - 223s 9ms/sample - loss: 0.2754 - acc: 0.8912 - val_loss: 0.3019 - val_acc: 0.8752
Epoch 3/10
25000/25000 [==============================] - 268s 11ms/sample - loss: 0.2268 - acc: 0.9130 - val_loss: 0.2977 - val_acc: 0.8764
Epoch 4/10
25000/25000 [==============================] - 247s 10ms/sample - loss: 0.1954 - acc: 0.9283 - val_loss: 0.2876 - val_acc: 0.8890
Epoch 5/10
25000/25000 [==============================] - 218s 9ms/sample - loss: 0.1759 - acc: 0.9352 - val_loss: 0.2848 - val_acc: 0.8842
Epoch 6/10
25000/25000 [==============================] - 217s 9ms/sample - loss: 0.1547 - acc: 0.9436 - val_loss: 0.2938 - val_acc: 0.8901
Epoch 7/10
25000/25000 [==============================] - 216s 9ms/sample - loss: 0.1408 - acc: 0.9489 - val_loss: 0.2662 - val_acc: 0.8940
Epoch 8/10
25000/25000 [==============================] - 217s 9ms/sample - loss: 0.1282 - acc: 0.9549 - val_loss: 0.2744 - val_acc: 0.8955
Epoch 9/10
25000/25000 [==============================] - 217s 9ms/sample - loss: 0.1160 - acc: 0.9600 - val_loss: 0.2965 - val_acc: 0.8929
Epoch 10/10
25000/25000 [==============================] - 219s 9ms/sample - loss: 0.1056 - acc: 0.9635 - val_loss: 0.3369 - val_acc: 0.8803Trainingsverlauf
show_loss_acc(history.history)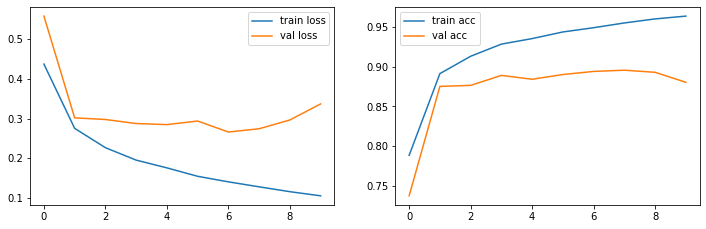
Ergebnisse
Das Bidirektionale GRU-Netz erzielt als ca. 89.5% Accuracy auf den Testdaten in der 8. Epoche.
15.3.7 Performanzvergleich
Unsere Ergebnisse sind wie folgt. Für wirklich seriöse Resultate müsste man viele Durchläufe durchführen und die Werte dann mitteln. Wir zeigen hier die höchste erzielte Accuracy auf den Testdaten und die jeweilige Epoche, in der das Ergebnis auftrat. Beachten Sie also, dass kleinere Unterschiede mit hoher Wahrscheinlichkeit auf statistische Schwankungen zurückzuführen sind. Man “sieht” hier also höchstens zwei Klassen von Ergebnissen, einmal um 85/86% und einmal um 88/89%.
Bidirektionalität sollte eigentlich keine Rolle spielen, da wir hier ein Many-to-One-Szenario vorliegen haben. Die leicht höheren Werte sind wohl eher Schwankungen.
| Netz | Acc Testdaten | Epoche |
|---|---|---|
| SimpleRNN | 85.3 | 4 |
| Bidirektionales RNN | 86.0 | 10 |
| LSTM | 88.4 | 2 |
| GRU | 89.4 | 7 |
| Bidirektionales GRU | 89.5 | 8 |
Die Ergebnisse spiegeln die Aussagen aus der Literatur wider: LSTM und GRU werden oft als gleichwertig betrachtet und nur bei ganz spezifischen Aufgaben scheinen Vor- und Nachteile sichtbar zu werden. LSTM/GRU sind aber in der Regel dem einfachen RNN klar überlegen. Bidirektionalität scheint weder beim einfachen RNN noch beim GRU einen echten Vorteil zu bringen. Auch das scheint plausibel, da man für einen kompletten Text eine Klasse sucht und daher ohnehin alle Wörter berücksichtigt werden. Bidirektionalität ist vielleicht eher für Many-to-many-Szenarien geeignet.
In Understanding LSTM Networks sagt Christopher Olah, dass die Unterschiede zwischen den RNN-Varianten wie LSTM und GRU eher gering seien:
Which of these variants is best? Do the differences matter? Greff et al. (2015) do a nice comparison of popular variants, finding that they’re all about the same.
Im Literaturverzeichnis finden Sie die Referenz als Greff et al. (2017). Es ist das gleiche Paper wie oben, nur dass es schon 2015 online erschien, aber erst 2017 in der Fachzeitschrift. Es sei auch nochmal auf Schmidhuber (2015) verwiesen, wo auf die Performanz verschiedener RNN eingegangen wird.