In diesem Kapitel lernen wir wichtige neue Mechanismen kennen, die den Erfolg des Deep Learning in der Bildverarbeitung ermöglicht haben. Wir erweitern Neuronale Netze um zwei neue Typen von Schichten, der Konvolutionsschicht (Konv-Schicht) und der Pooling-Schicht. Die Konvolutionsoperation kommt aus der Bildverarbeitung und gibt den Convolutional Neural Networks (CNNs) ihren Namen. Eine Konv-Schicht arbeitet fundamental anders als eine reguläre Schicht, die wir fortan Fully Connected (FC-Schicht) Layer nennen. Eine Konv-Schicht besteht aus einer Anzahl von Filtern, die eine Parallelität in der Verarbeitung bewirken. Wir sehen uns an, wie Konvolutionsfilter mit Backpropagation gelernt werden und wie CNNs in Keras mit dem Datensatz CIFAR-10 umgesetzt werden. Zusätzlich lernen wir die Methode Early Stopping in Keras kennen.
das Konzept von Convolutional Neural Networks und ihre Besonderheiten gegenüber Feedforward-Netzen erklären
den Konvolutionsoperator erklären, inklusive Padding und Stride, und entsprechende Berechnungen durchführen
die Funktionsweise einer Konvolutionsschicht skizzieren und den Unterschied zu einem Fully-Connected Layer darlegen
die Konzepte von Kanälen, Filteranzahl und Pooling unterscheiden und beispielhafte Berechnungen durchführen
Konv-Netze schematisch skizzieren, erklären (als Kombination von Konv-, Pooling- und Fully Connected-Schichten) und die Parameterzahl und Tensorgrößen bestimmen
in Keras Konv-Netze anwenden (Funktionen Conv2D, MaxPooling2D und Flatten) und Early Stopping im Training verwenden und mit dem Datensatz CIFAR-10 umgehen
Updates dieser Seite
24.05.2025: Hinweise bei Kanälen
22.05.2025: Datensatzhinweis raus, Überschrift Keras geändert
16.05.2024: Links in 8.6
Notation
In diesem Kapitel werden wir folgende Notation verwenden.
Symbol
Bedeutung
\(I\)
Matrix mit Bilddaten
\(F\)
Filter-Matrix
\(n_H\)
Höhe eines Bildes (Pixel)
\(n_W\)
Breite eines Bildes (Pixel)
\(f\)
Größe des (quadratischen) Filters, also sowohl Höhe als auch Breite
\(s\)
Stride (Schrittweite) der Konvolution
\(p\)
Padding der Konvolution
\(w_i\)
Gewicht
\(z_i\)
Rohinput
\(a_i\)
Aktivierung
\(g\)
Aktivierungsfunktion
\(b\)
Bias
\(n_c\)
Anzahl der Kanäle, meistens die dritte Dimension des entsprechenden Tensors
\(J\)
Fehler-/Kostenfunktion (loss function)
\(P\)
Anzahl der Parameter einer Schicht oder eines NN
10.1 Was sind Konvolutionsnetze?
Convolutional Neural Networks (CNNs) haben in 2010er-Jahren eine Popularitätswelle der Neuronalen Netze unter dem Begriff Deep Learning losgetreten. Gute Darstellungen zur Geschicht der CNNs findet man bei Khan et al. (2020) und Schmidhuber (2015).
Geschichte
Den Durchbruch in der Geschichte der CNN erzielt 2012 das AlexNet als Gewinner der ImageNet ILSVRC Challenge 2012 (Krizhevsky, Sutskever, and Hinton 2012). Der Name AlexNet geht zurück auf den Erstautoren Alex Krizhevsky, der bei Geoffrey Hinton seine Doktorarbeit schrieb, für einige Zeit bei Google Brain arbeitete und Mitinitiator der Datensätze CIFAR-10 und CIFAR-100 war. Der Zweitautor Ilya Sutskever ist aktuell KI-Wissenschaftler bei OpenAI und Mitautor der Systeme AlphaGo und GPT-3.
Die Architektur von AlexNet lässt sich wiederum zurückführen auf LeNet-5 aus dem Jahr 1998(LeCun et al. 1998), das sich mit der Erkennung von handgeschriebenen Postleitzahlen befasste und als das erste Convolutional Neural Network gilt. Es stammt von Yann LeCun, der - wie schon in Abschnitt {-Section 4.2} erwähnt - 2018 den Turing Award für seine Arbeit auf dem Gebiet Deep Learning erhielt (zusammen mit Geoffrey Hinton und Yoshua Bengio). Aktuell ist LeCun Professor an der New York University und leitender KI-Wissenschaftler bei Meta (Facebook).
LeCun et al. (1989) stellt noch früher Konvolutionen als Bestandteil eines Netzes vor. Als noch früherer Vorläufer der Konvolutionsnetze gilt das Neocognitron von Fukushima (1980) bzw. Fukushima, Miyake, and Ito (1983).
Interssant ist auch die Phase 2000-2006, also etwa zwischen LeNet-5 und AlexNet. In dieser Zeit stagnierten die Fortschritte der frühen CNN, weil man das Training nicht in den Griff bekam (Khan et al. 2020). In dieser Phase waren statistische Methoden, insbes. Support Vector Machines (SVM) die Spitzenreiter in der Bilderkennung. Erst neue (wenngleich kleine) Anpassungen des Trainings (Aktivierung ReLU, Data augmentation, Dropout), neue, große Bild-Datensätze wie ImageNet und der Einsatz der hohen Rechenleistung von GPUs verhalfen dann CNNs zum oben genannten Durchbruch mit dem AlexNet.
Visuelle Verarbeitung im Gehirn
CNNs sind inspiriert von den Erkenntnissen über die visuelle Verarbeitung im Gehirn. David H. Hubel und Torsten Wiesel fanden bereits 1959 experimentell heraus, dass bei der visuellen Verarbeitung auf dem Weg von der Retina im Auge zur weiteren Verarbeitung im Hirn bestimmte “Features” erkannt werden, z.B. horizontale oder diagonale Linien. Die Verarbeitung findet dabei “lokal” statt, d.h. regional begrenzte, überlappende Sehfelder (receptive fields) auf der Retina werden vorverarbeitet. Dabei werden schicht-weise immer komplexere und nicht-lokale Features (z.B. Formen oder Bewegung) abgeleitet.
In one experiment, done in 1959, they inserted a microelectrode into the primary visual cortex of an anesthetized cat. They then projected patterns of light and dark on a screen in front of the cat. They found that some neurons fired rapidly when presented with lines at one angle, while others responded best to another angle. Some of these neurons responded to light patterns and dark patterns differently. Hubel and Wiesel called these neurons simple cells.”Still other neurons, which they termed complex cells, detected edges regardless of where they were placed in the receptive field of the neuron and could preferentially detect motion in certain directions. These studies showed how the visual system constructs complex representations of visual information from simple stimulus features.
Hubel und Wiesel erhielten 1981 den Nobelpreis für ihre Forschungen “für ihre Entdeckungen über Informationsverarbeitung im Sehwahrnehmungssystem” (auch lesenswert: ein kurzer Artikel von Arvid Leyh zu den Anfängen der Forschung von Hubel und Wiesel). Die enorme Bedeutung dieser Forschung für die Neurowissenschaften kann nicht genug betont werden.
Konvolutionsnetze
Konvolutionsnetze (CNNs) greifen die Idee auf, ein lokales Sehfeld von mehreren Neuronen auf ein einziges Neuron abzubilden und so abstraktere Features herauszubilden und die Anzahl der Parameter (Gewichte) zu reduzieren. Insbesondere werden aber gezielt Operationen aus der Bildverarbeitung (Convolution) eingesetzt, um diese Abstraktion erfolgreich umzusetzen.
Ein CNN enthält eine oder mehrere Convolutional Layers (Konvolutionsschichten), die diesem Netzwerktyp ihren Namen geben. Convoluational Layers können sehr kompliziert wirken, wenn man Darstellungen sieht. Deshalb gehen wir schrittweise vor und stellen zunächst die Operation der Konvolution vor.
10.2 Konvolution und Konvolutionsschicht
Konvolution ist eine mathematische Operation aus der Bildverarbeitung, bei der Bilddaten (Pixelmatrix) mit Filtern manipuliert werden, um im gefilterten Bild besser Objekte zu erkenen oder anderen höherwertige Probleme zu lösen.
Eine Konvolution wird auch Faltung genannt und ist eine Art Filter. Das Grundprinzip ist, dass eine kleine Matrix (z.B. 3x3) schrittweise über das Bild geschoben wird: erst pixelweise nach rechts, dann am Ende der Zeile zurück auf den Beginn der nächsten Zeile einen Pixel tiefer etc. Man nennt diese Technik auch ein Sliding Window.
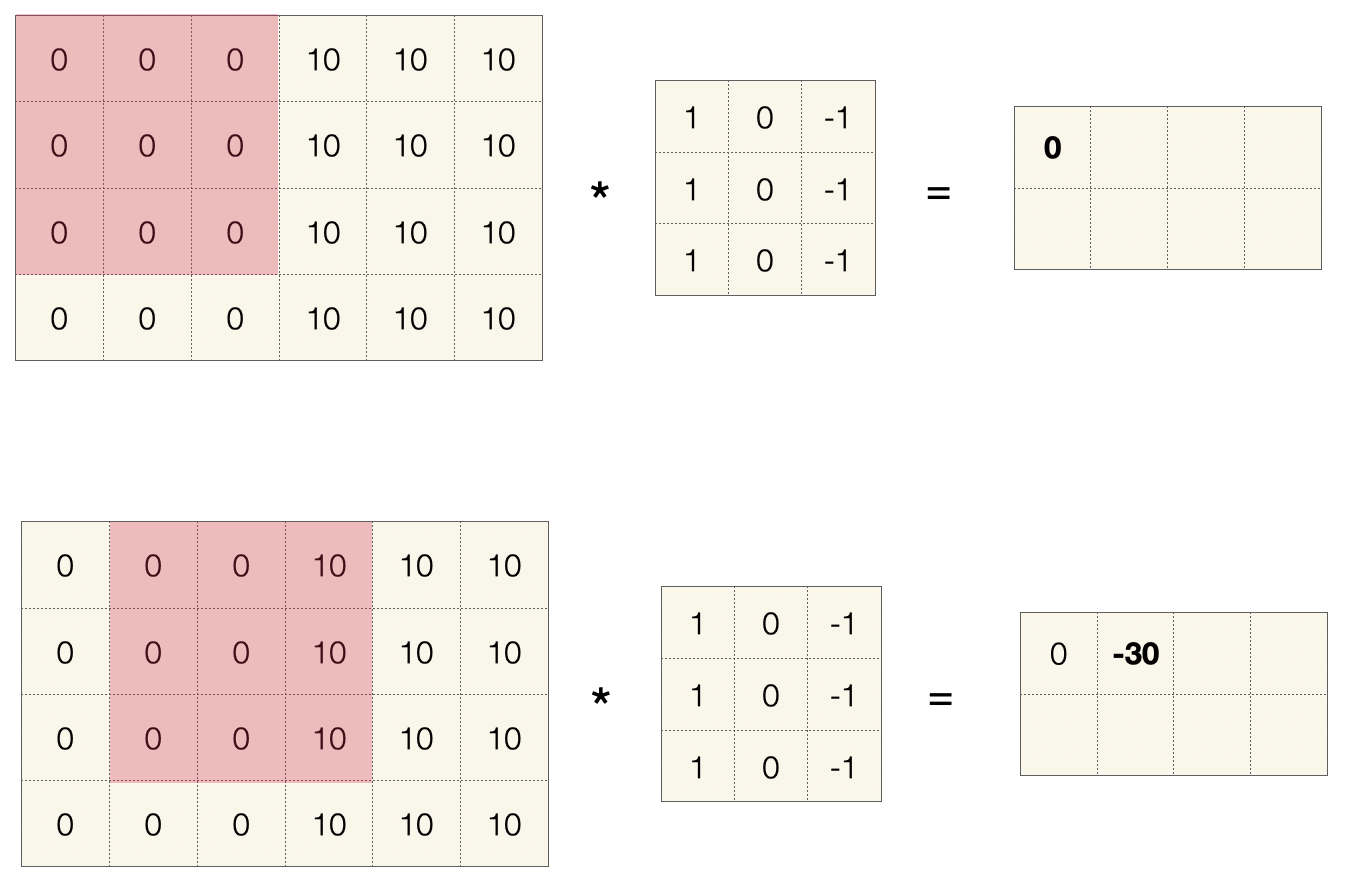
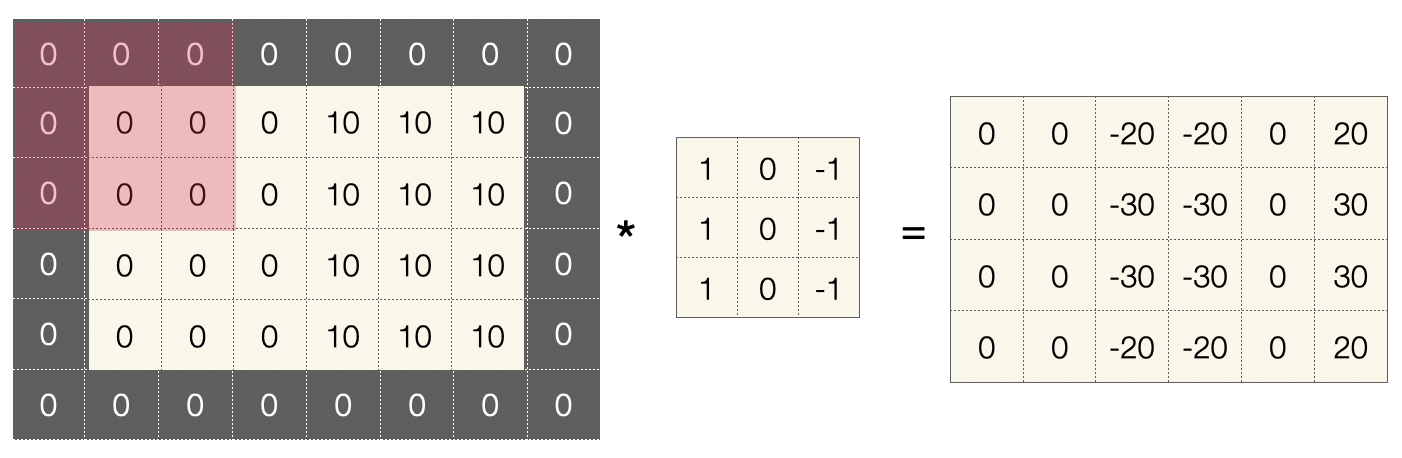
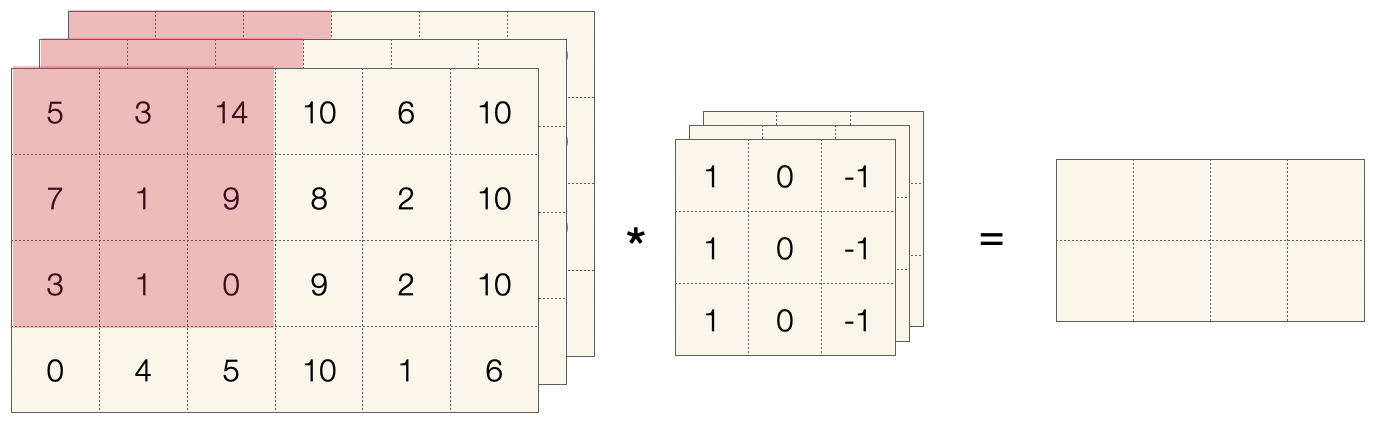
Unten sehen wir ein konkretes Beispiel mit einem 3x3-Filter, diesen nennt man auch Kernel, angewandt auf die ersten zwei Felder eines 4x6-Bildes. Die Ergebnismatrix (rechts) wird zeilenweise aufgebaut.
Um die Konvolution auszudrücken, verwenden wir den Stern als Konvolutionsoperator, z.B. für Bild \(I\) und Filter \(F\):
\[ I * F \]
Die Berechnung in jedem Schritt ist sehr leicht. Wenn \(F\) die 3x3-Filtermatrix ist und \(I^1\) das erste 3x3-Feld des Bildes (in der Abbildung rot markiert), dann werden einfach alle Zellen von \(F\) mit den entsprechenden Zellen von \(I^1\) multipliziert und die Ergebnisse addiert:
Im abgebildeten Beispiel resultiert das im ersten Schritt in einer \(0\). Im zweiten Schritt bekommt man eine \(-30\).
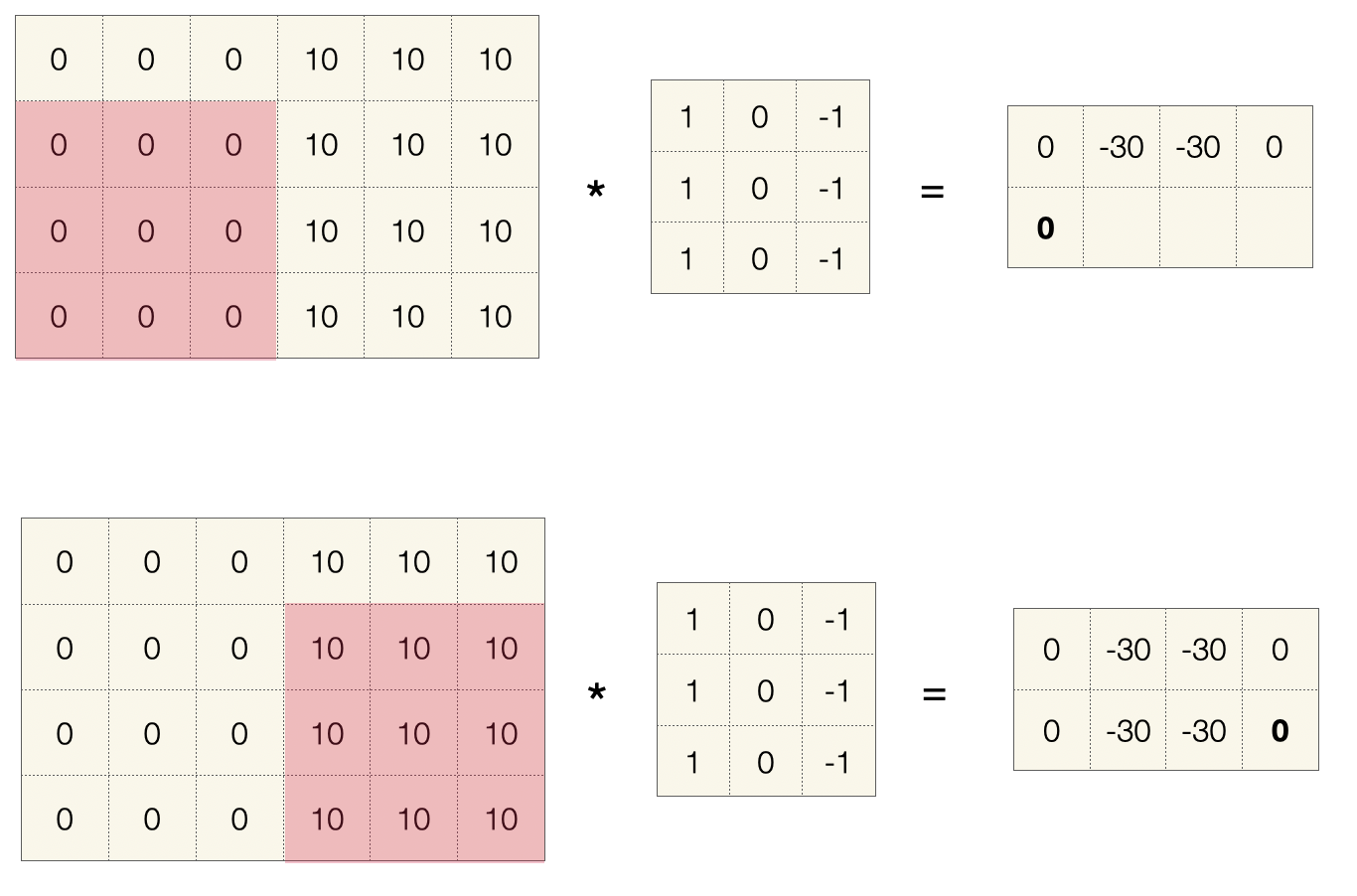
Im weiteren sehen wir den Sprung nach Abarbeitung einer Zeile. Der Filter springt einen Pixel nach unten und geht erneut durch die Zeile. In der Abbildung unten zeigen wir nur den ersten und den vierten Schritt.
Das Ergebnis ist eine 2x4-Matrix.
Dieser Filter ist übrigens ein Detektor für vertikale Kanten. Sie sehen, dass im Bild zwei Flächen aufeinander stoßen (Graustufe 0 vs. Graustufe 10). Für die visuelle Verarbeitung sind solche Übergänge besonders interessant, weil sie auf den Umriss eines Objekts oder eines Lebewesens hindeuten. Der Filter ignoriert ausgefüllte Flächen (Wert 0) und hebt vertikale Kanten hervor (hier Wert -30).
Das Beispiel oben ist eine Vereinfachung eines bekannten Filters aus der Bildverarbeitung, dem Sobel-Filter. Dieser erkennt ebenfalls vertikale und horizontale Kanten:
Dann resultiert die Anwendung von \(F_v\) auf das Bild in folgender Ausgabe:
Die Anwendung von \(F_h\) auf das Bild führt zu dieser Ausgabe:
Konvolution oder Kreuzkorrelation?
Die Konvolutionsoperation kommt aus der Signalverarbeitung. Die oben dargestellte Operation ist streng genommen aber nicht die traditionelle Konvolution, sondern die Operation der Kreuzkorrelation. In der “echten” Konvolution der Signalverarbeitung muss der Filter erst zweimal gespiegelt werden, bevor er angewandt wird.
Wir sehen das z.B. im Paket signal der Bibliothek SciPy. Dort wird die “echte” Konvolution durchgeführt und führt somit zu einem anderen Ergebnis als oben (man beachte die Vorzeichen).
Wir bereiten erstmal das Bild (image) und den Filter (filter) vor:
import numpy as npfrom scipy import signalimage = [[0, 0, 0, 10, 10, 10] for i inrange(4)] # python list comprehensionfilter= [[1, 0, -1] for i inrange(3)]print(f"image:\n{image}\n\nfilter:\n{filter}")
Jetzt wenden wir die eingebaute Konvolutionsoperation an. Der Parameter mode wird später beim Thema Padding erläutert.
signal.convolve2d(image, filter, mode='valid')
array([[ 0, 30, 30, 0],
[ 0, 30, 30, 0]])
Hier finden Sie eine Erklärung dazu: https://cs.stackexchange.com/questions/11591/2d-convolution-flipping-the-kernel
Im Bereich Deep Learning wird der Unterschied zwischen Konvolution und Kreuzkorrelation praktisch ignoriert: es wird also die (einfachere) Operation wie weiter oben gezeigt durchgeführt und dennoch wird von Konvolution gesprochen.
Notation
Wir führen ein wenig Notation ein. Für Höhe und Breite des obigen Bildes, eine Matrix, schreiben wir:
Als Stride bezeichnet man die Schrittweite. Im obigen Beispiel hatten wir einen Stride von 1, denn wir haben den Filter immer um einen Pixel nach rechts bewegt bzw. um einen Pixel nach unten, wenn die Zeile abgearbeitet war.
Der Stride kann aber auch höher ausfallen, z.B. mit einem Wert von 2 oder 3. Der Stride gilt immer sowohl für die horizontale als auch für die vertikale Bewegung des Filters.
Hier ein Beispiel mit Stride 2 als Schema ohne konkrete Zahlen. Der rote Kasten zeigt den Filter. Rechts wird die Ausgabematrix dargestellt.
Wir beschreiben Stride mit dem Buchstaben \(s\), also zum Beispiel
\[ s = 2 \]
Dann berechnen wir die Breite der Ausgabematrix \(\bar{n}_W\) wie folgt (analog für \(n_H\)):
Die Klammern mit der Kante unten bedeuten, dass der eingeklammerte Term abgerundet wird, in Englischen nennt man die Operation floor. Es gibt auch die Umkehroperation \(\lceil x \rceil\) oder englisch ceiling.
In der Abbildung oben sehen wir ein Input-Bild, das 7 Pixel breit ist und 5 Pixel hoch, mit einem 3x3-Filter und einem Stride von 2. Wir setzen das in unsere Formeln ein:
Die Konvolutionsoperation hat zwei Effekte, denen wir eventuell entgegenwirken möchten:
Unsere Ergebnismatrix ist kleiner als das ursprüngliche Bild. Bei einem 3x3-Filter verlieren wir in jede der vier Richtungen jeweils einen Pixel, so dass aus dem 4x6-Bild eine 2x3 Matrix wird.
Pixel am Rand gehen weniger in die Ergebnismatrix ein. Das Pixel in der linken oberen Ecke wird genau 1x mit einbezogen, wohingegen ein Pixel im Inneren 9x einbezogen wird (bei einem 3x3-Filter und Stride 1).
Beim Padding werden “virtuelle” Randpixel zur Berechnung der Konvolution hinzugefügt. Dabei gibt man an, wieviele Pixel tief dieser Rand sein soll. Beim 3x3-Filter würde man ein Padding von 1 anlegen. Als Inhalt des Paddings nimmt man typischerweise Nullen, es wären aber auch andere Werte denkbar (z.B. Wert eines Nachbarpixels).
Bild und Ausgabematrix haben in diesem Beispiel die gleichen Dimensionen. Außerdem gehen die Randpixel nun häufiger in die Ergebnismatrix mit ein.
Wir bezeichnen den Umfang des Padding (in Pixeln) mit dem Buchstaben \(p\). Oben haben wir ein Beispiel mit \(p=1\) gesehen. Wir passen unsere Formel für die Ausgabegröße \(\bar{n}_W\) (analog \(\bar{n}_H\)) an:
Wir sehen, dass die Ausgabematrix die gleiche Höhe und Breite hat wie die Eingabematrix.
Jetzt können wir berechnen, wie allgemein das Padding aussehen muss, damit die Ausgabematrix genauso groß ist wie die Eingabematrix (wir gehen von \(s=1\) aus). Es gilt die Beziehung:
\[
\bar{n}_W =n_W +2p- f + 1
\]
Jetzt wollen wir, dass \(\bar{n}_W = n_W\), also:
\[
\begin{align*}
0 &=2p- f + 1\\[2mm]
p &= \frac{f-1}{2}
\end{align*}
\]
Filter sind in der Praxis immer ungerade, am häufigsten sieht man \(f=3\) und \(f=5\). Entsprechend muss man für \(f=5\) auch \(p=2\) wählen, wenn die Matrixgrößen erhalten bleiben sollen.
VALID vs. SAME
Beim Padding geht es im Grunde darum, dafür zu sorgen, dass die Ausgabematrix die gleiche Größe hat wie die Eingabematrix. Wenn das nicht erwünscht ist, setzt man einfach \(p\) auf Null.
Daher haben sich zwei Begriffe für diese beiden Fälle eingebürgert, die z.B. auch in Keras so verwendet werden:
VALID: Hier wird Konvolution ohne Padding durchgeführt, also \(p=0\)
SAME: Hier wird Konvolution so mit Padding versehen, dass die Ausgabe dieselbe Größe hat wie die Eingabe, deshalb auch “same” (size), also bei uns \(p = \frac{f-1}{2}\)
Oben hatten wir einen Konvolutionsoperator angesehen. Auch hier können wir als Modalität same einstellen.
image = [[0, 0, 0, 10, 10, 10] for i inrange(4)]filter= [[1, 0, -1] for i inrange(3)]signal.convolve2d(image, filter, mode='same')
10.2.2 Formale Definition der Konvolution (optional)
Wir möchten die Konvolutionsoperation mathematisch definieren. Der Einfachtheit halber ignorieren wir den Stride, d.h. \(s\) ist immer gleich 1.
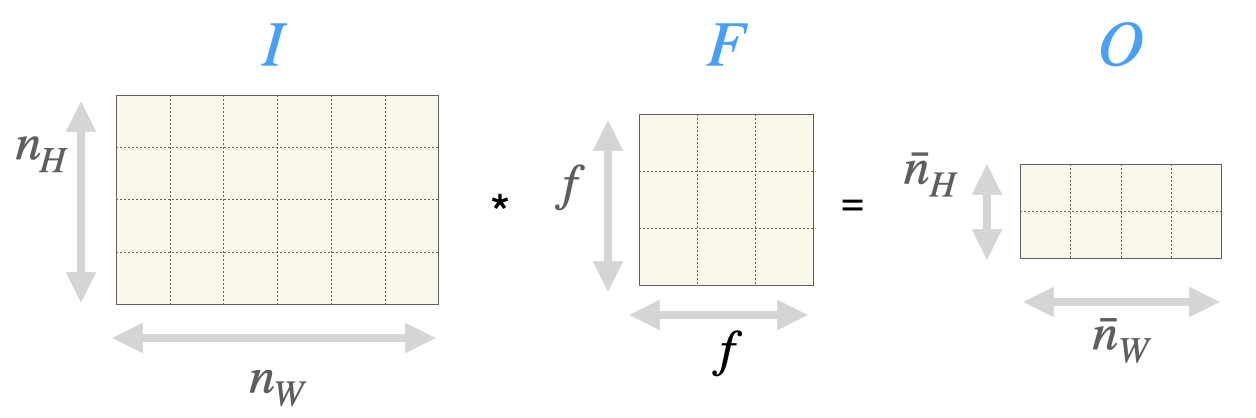
Wir haben ein Bild \(I\) (Image), einen Filter \(F\) und nennen den resultierenden Output \(O\), also
\[ O := I * F \]
Für die Höhe und Breite von Bild \(I\) haben wir die Parameter \(n_H\) und \(n_W\). Der Filter \(F\) ist immer eine quadratische Matrix mit Höhe und Breite \(f\). Die Höhe und Breite des Outputs kann wie oben gezeigt berechnet werden und wird mit \(\bar{n}_H\) und \(\bar{n}_W\) bezeichnet.
Die Abbildung zeigt alle relevanten Größen:
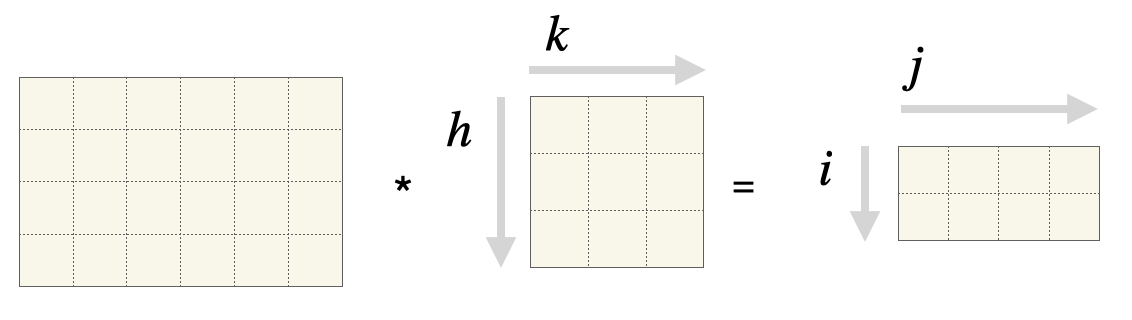
Um den Output \(O\) zu berechnen, können wir folgende Formel für jede Komponente \(o_{i,j}\) der Martrix \(O\) wie folgt darstellen.
\[ o_{i,j} = (I * F)_{i,j}\]
Jetzt können wir die Berechnung wie folgt beschreiben:
wobei \(i = 1, \ldots, \bar{n}_H\) und \(j = 1, \ldots, \bar{n}_W\).
Die folgende Abbildung zeigt die Parameter der Formel (KV) an den entsprechenden Matrizen.
Versuchen Sie, die Formel mit Hilfe der Abbildung nachzuvollziehen. Wählen Sie dazu ein Outputelement, z.B. \(o_{1, 1}\) oder \(o_{2, 4}\), und kontrollieren Sie, ob die korrekten Elemente von \(I\) und \(F\) in die Rechnung eingehen.
10.3 Konvolutionsschicht
In einer Konvolutionsschicht werden nun die oben gezeigten Filter gelernt und nicht “per Hand” von einem Ingenieur erdacht. In der Regel wird nur die Größe des Filters vorgegeben (z.B. 5x5) und die Werte durch Training optimiert.
Konvolutionsschichten haben Parameter, sind aber dennoch fundamental verschieden von herkömmlichen Schichten in FNNs. Interessant ist einerseits, dass ihre Eingabe stark begrenzt ist - ähnlich wie im Auge mit den receptive field. Das führt zu einer geringeren Anzahl an Parametern. Andererseits können Filter, da sie über das ganze Bild “geschoben” werden, auch an solchen Stellen wirken, wo sie gar nicht “angelernt” wurden. Wenn diese Schichten hintereinander geschaltet werden, können somit räumlich-hierarchische Muster gelernt werden, von lokalen Features wir Kanten zu globaleren, semantischeren Features wir Auge, Mund oder Gesicht.
Wie wir sehen werden, kommen Gewichte in einer Konvolutionsschicht mehrfach zum Einsatz, so dass lokale Muster im gesamten Bild “erkannt” werden können. Yann LeCun benutzt den Begriff weight sharing für dieses Phänomen (LeCun et al. 1989).
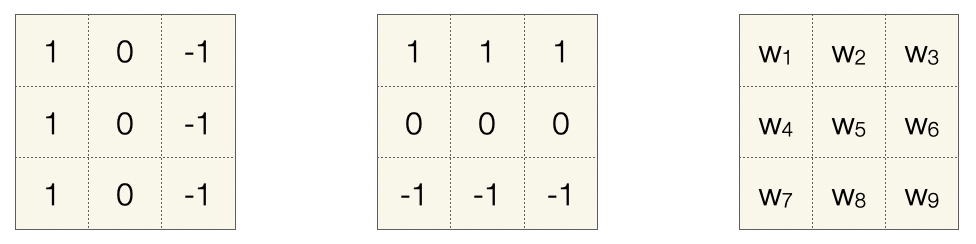
Filter lernen
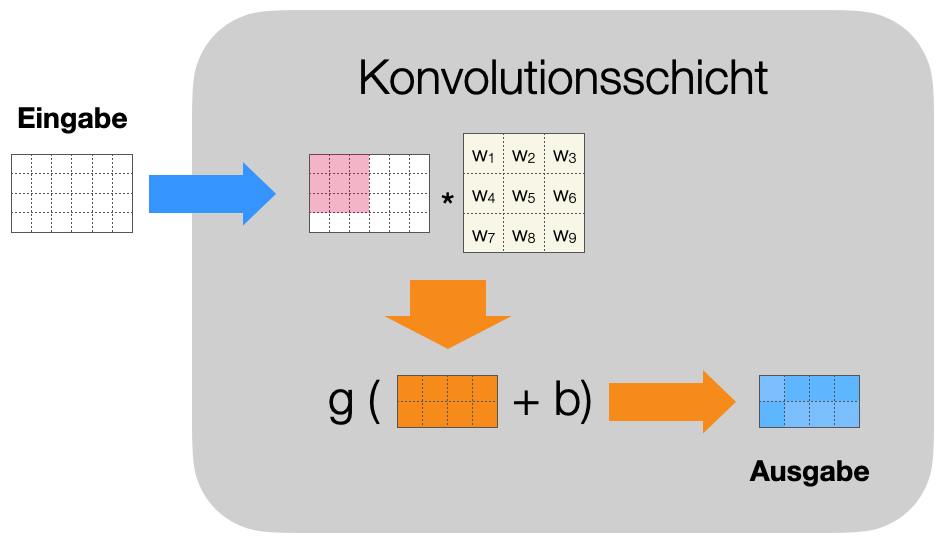
In der nachfolgenden Abbildung sehen wir zunächst zwei typische Filter mit festen Werten und dann die entsprechende Matrix mit variablen Werten, die wir mit \(w_i\) bezeichnen. Diese “Gewichte” sollen jetzt gelernt werden.
Die Anwendung des Filters resultiert in einer Ausgabematrix. Zu dieser Ausgabematrix addieren wir noch einen Bias \(b\), ein Skalar, auf jedes Element der Matrix. Schließlich wenden wir eine Aktivierungsfunktion \(g\) auf jedes Element an, zum Beispiel die Sigmoid- oder die ReLU-Funktion. Abbildung 10.1 zeigt das noch einmal schematisch.
Figure 10.1: Schematische Darstellung einer Konvolutionsschicht
Insofern ist die Konvolutionsschicht nicht unähnlich einer “normalen” Schicht. Es gibt einen linearen Teil - Konvolutionsoperation und Bias - und einen nicht-linearen Teil über die Aktivierungsfunktion.
Konvolutionsschicht vs. Fully-Connected-Schicht (FC-Schicht)
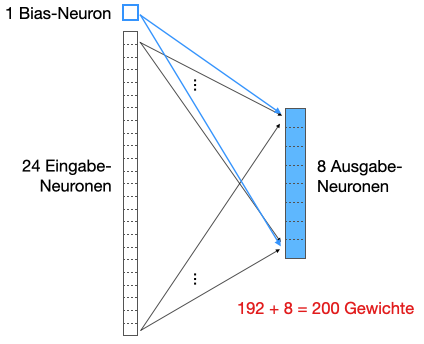
Die in der obigen Abbildung dargestellte Schicht hat als Eingabe 4x6=24 Neuronen und als Ausgabe 2x4=8 Neuronen. An Parametern zählen wir 9 Gewichte im Filter plus einen Bias, also insgesamt 10 Parameter.
Wenn man die Zahl der Parameter mit einer “normalen” Schicht vergleicht, so kann man sich die Eingabe- und Ausgabeneuronen wie folgt linearisiert vorstellen:
Wir zählen hier also 24x8=192 Gewichte an den Verbindungen plus 8 Bias-Neuronen, also insgesamt 200 Parameter.
Wir nennen eine konventionelle Schicht wie wir sie aus Kapitel 4 kennen ab sofort Fully Connected Layer oder FC-Schicht. Eine FC-Schicht hat deutlich mehr Verbindungen und somit Gewichte als eine Konvolutionsschicht, im Beispiel oben das 20-fache. In Keras heißt diese Schicht Dense Layer (wegen der hohen Dichte an Verbindungen/Gewichten).
Linearisierte Sicht auf die Konvolutionsschicht
Um die Unterschiede und Gemeinsamkeiten zwischen Konvolutionsschicht und FC-Schicht besser zu verstehen, betrachten wir die beteiligten Matrizen in einer linearisierten Form (die Amerikaner sprechen hier von “unrolling”, also auseinander wickeln).
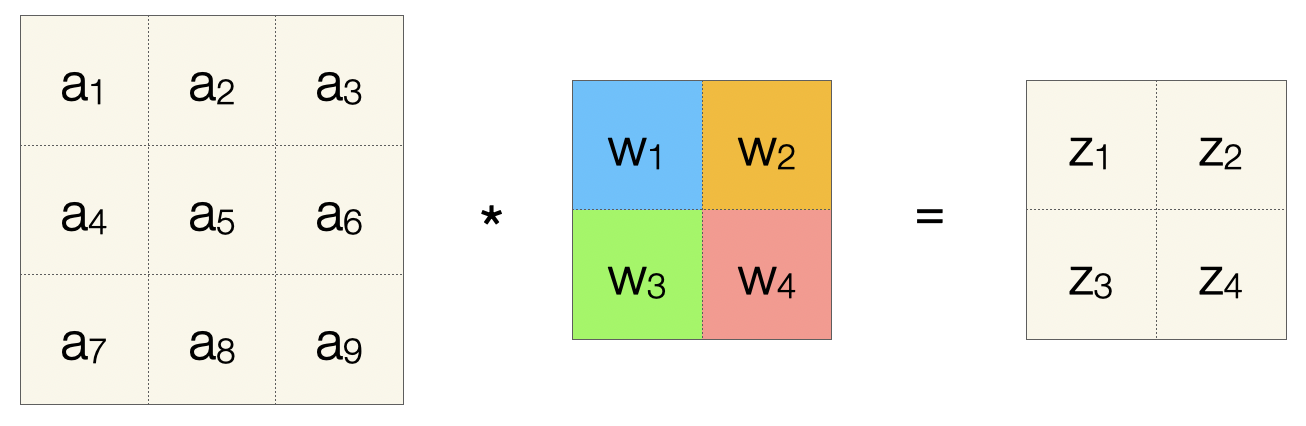
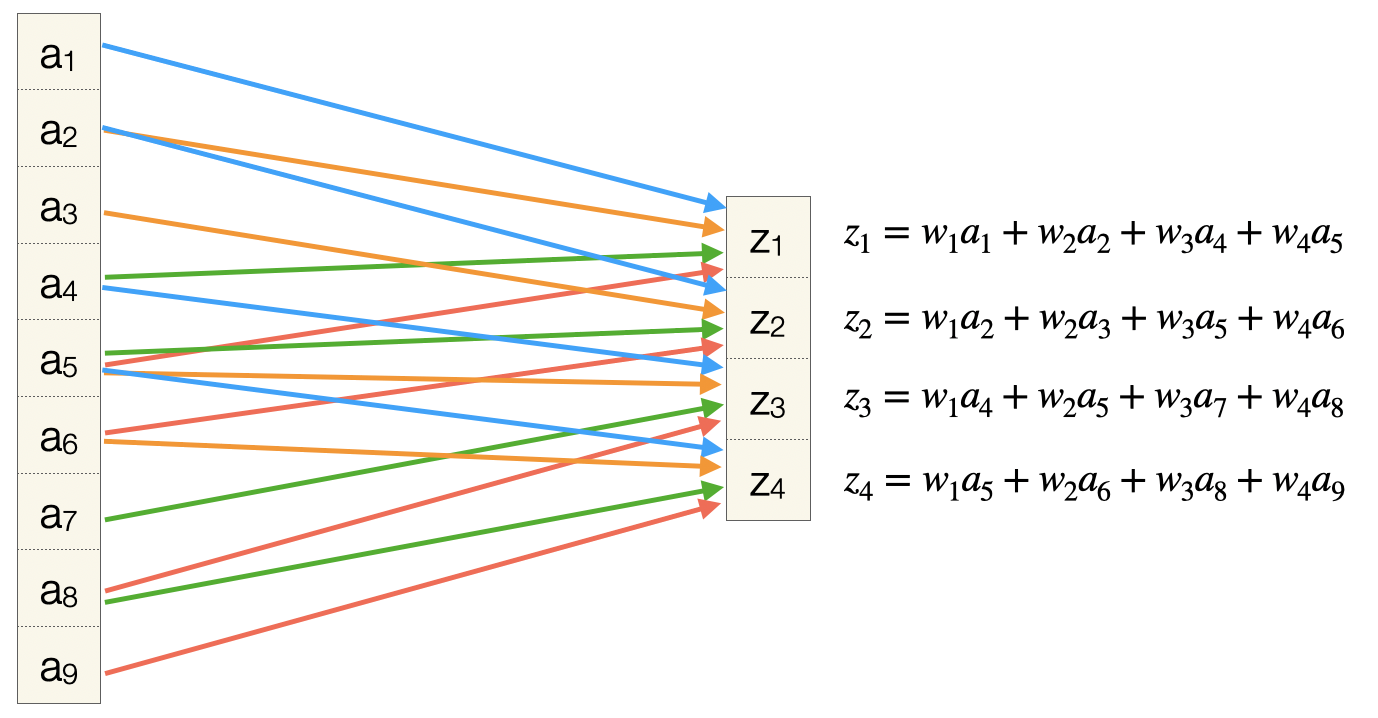
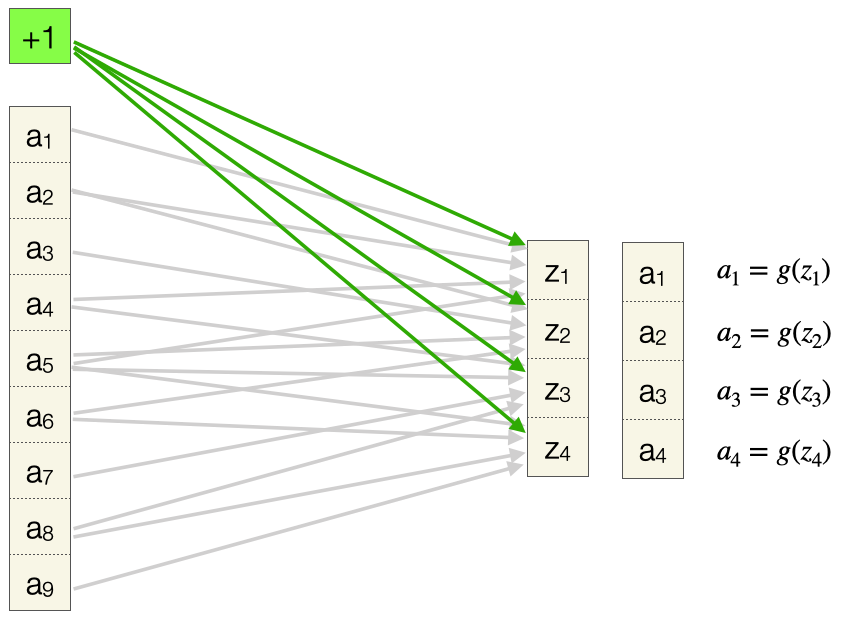
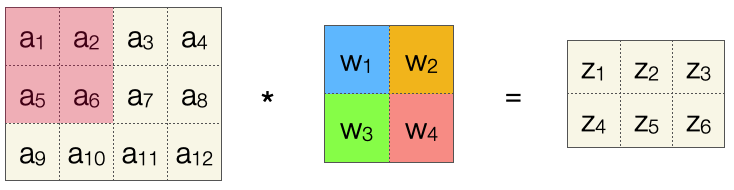
Wir betrachten zunächst nur die Konvolutionsoperation mit einer 3x3-Inputmatrix, einem 2x2-Filter, ohne Padding und mit Stride 1. Die Werte der Inputmatrix sind hier linear durchnummeriert, wir nennen sie \(a_1, \ldots, a_9\). Wir müssen uns diese Werte als die Aktiverung der Vorgängerschicht vorstellen. Der Filter hat die Werte \(w_1, w_2, w_3, w_4\). Die Ausgabe ist analog zum Rohinput im FNN, also nennen wir die vier Zellen \(z_1, \ldots, z_4\).
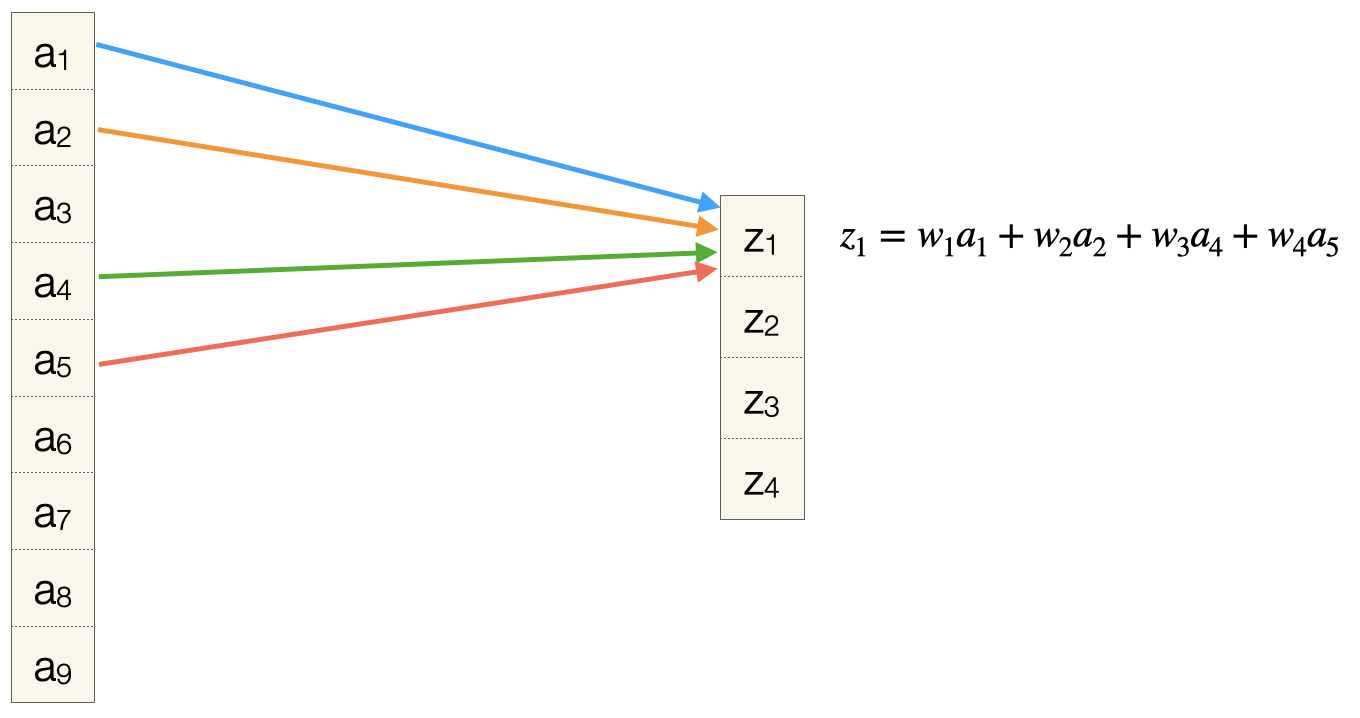
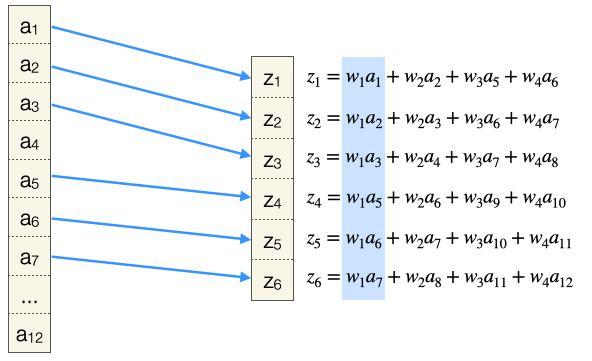
Jetzt stellen wir die linearisierte Eingabematrix analog zu einer Schicht in einem FNN dar. Ebenso die linearisierte Ausgabematrix. Die erste Operation der Konvolution lässt sich dann wie folgt darstellen (die Gewichte \(w_1, w_2, w_3, w_4\) sind farbkodiert). Ein Pfeil zeigt, dass ein Gewicht in die Berechnung des Werts \(z_1\) mit eingeht, und somit ist die Darstellung “kompatibel” zur Darstellung einer FC-Schicht.
Nach vier Schritten haben wir alle z-Werte berechnet und wir sehen hier, welche Gewichte in welche Berechnung mit eingehen.
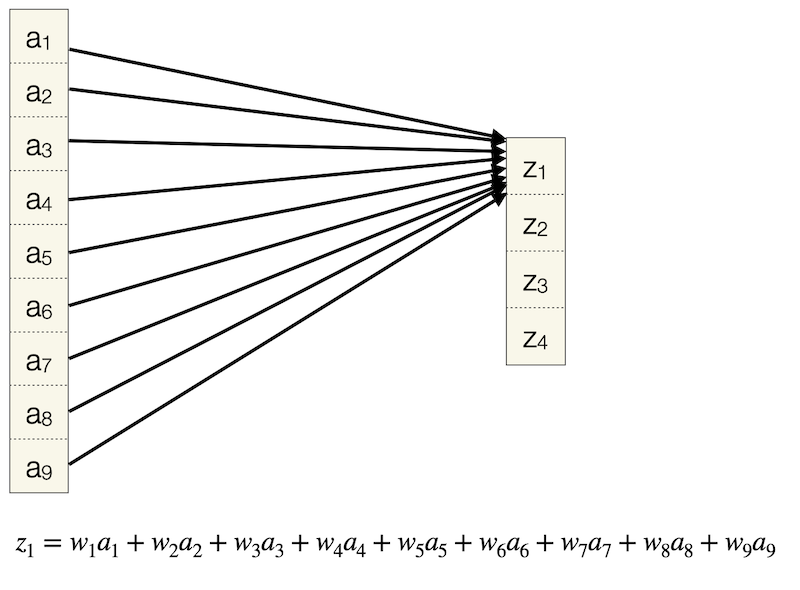
Sehen wir uns im Vergleich eine FC-Version an. Nur für den ersten Output \(z_1\) haben wir bereits 9 Parameter:
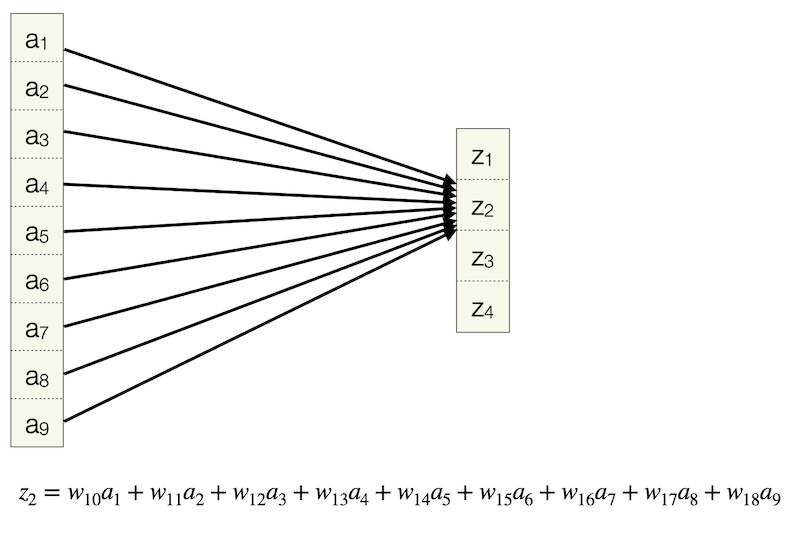
Für den zweiten Output \(z_2\) dann weitere 9:
Insgesamt haben wir 4x9, also 36 Verbindungen. Jede Verbindung zeigt auf genau ein Output-Neuron.
Wenn wir Konv-Schicht und FC-Schicht vergleichen, fallen folgende Eigenschaften einer Konv-Schicht auf:
jedes Ausgabeneuron ist mit nur vier Eingabeneuronen verbunden
Eingabeneuronen kommen unterschiedlich oft zum Einsatz, zum Beispiel geht \(a_3\) nur in eine Rechnung ein (\(z_2\)) und \(a_5\) in vier Rechnungen (alle \(z\)); das haben wir bereits beim Thema Padding beobachtet
jedes Gewicht wird mehrfach (4x) eingesetzt, bei der FC-Schicht kommt jedes Gewicht genau 1x zum Einsatz
es werden viele Verbindungen hergestellt, aber unter Verwendung von insgesamt nur vier Gewichten, und es sind nicht so viele Verbindungen wie bei der FC-Schicht (nicht jedes \(a_i\) zeigt auf jedes \(z_j\))
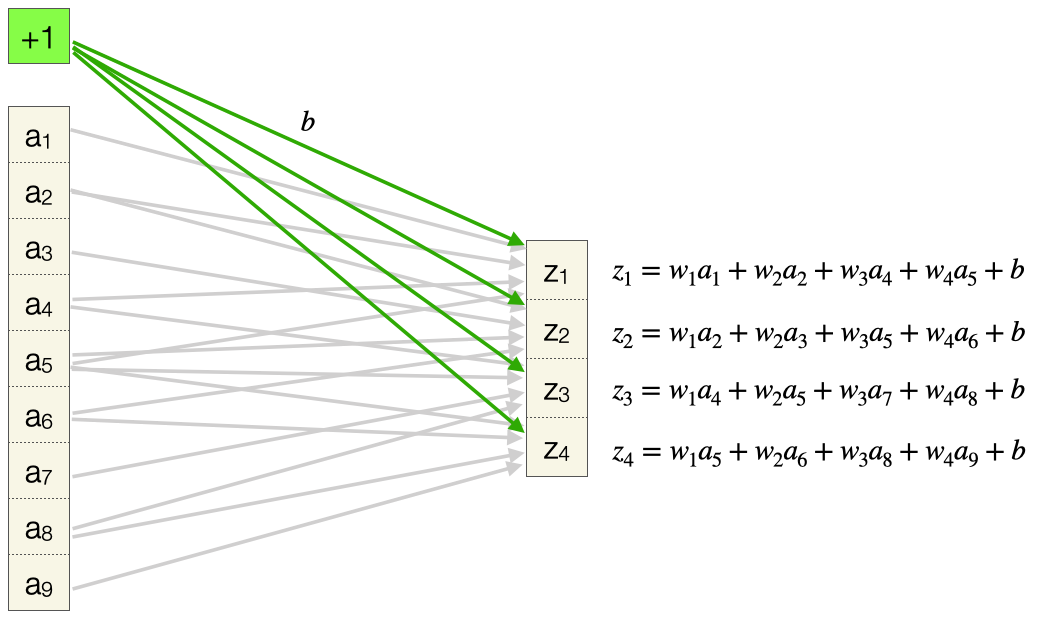
Wir möchten noch den Funktionsumfang der Konvolutionsschicht vervollständigen. Es fehlt noch der Bias-Wert. Es gibt genau einen pro Filter, d.h. auch hier wird ein Gewicht mehrfach eingesetzt. Auch hier wählen wir eine Darstellung, die analog zur FC-Schicht ist:
Zum Schluss zeigen wir die Anwendung der Aktivierungsfunktion \(g\), so dass wir unsere finalen Ausgabewerte \(a_1, \ldots, a_4\) bekommen:
Auch wenn wir im nächsten Abschnitt über mehrdimensionale Konvolution sprechen, ändert dies nichts an dieser Darstellung. Auch die Eingabe eines 16x16x128-Tensors kann linearisiert werden und sieht dann genauso aus wie oben dargestellt (gleiches gilt für den Filter und die Ausgabe).
10.4 Konv-Schicht: Kanäle und Filterzahl
Nachdem wir wissen, dass eine Konv-Schicht aus Filter, Bias und Aktivierungsfunktion besteht, wenden wir uns wieder der Konvolutionsoperation zu und erweitern diese auf mehrere Kanäle und auf mehrere parallele Filter.
Daten sind weiterhin 2-dimensional
Beachten Sie im Folgenden, dass das Datenmaterial immer 2-dimensional bleibt, denn das Quellmaterial (Bilder) hat 2 räumliche Dimensionen. Deshalb nennt man diese Schicht in Keras auch Conv2D. Die Kanäle (hier Farbkanäle) fügen keine Raumdimension hinzu. Wenn Sie in Keras 60000 Bilder der Größe 32x32 mit 3 Farbkanälen in den Speicher laden, hat der entsprechende Tensor vier Dimensionen und die Shape (60000, 32, 32, 3). Dennoch bleiben es zwei räumliche Dimensionen, die in den Daten kodiert sind.
10.4.1 Mehrere Kanäle
Ein 4x6-Bild mit 3 Farbkanälen (RGB) kann man sich als 3-dimensionalen 4x6x3-Tensor vorstellen. Ein Bild kann natürlich auch andere oder zusätzliche Kanäle haben, z.B. für Infrarotdaten (Satellitenbilder) oder für Tiefeninformation. Zudem kann eine Matrix aufgrund einer vorigen Verarbeitung viele Kanäle haben.
Wir benennen die Anzahl der Kanäle mit \(n_c\) und bleiben aber bei den 3 Farbkanälen als Beispiel, also \(n_c = 3\).
Will man auf diesen Eingabetensor eine Konvolution anwenden, kann man sich das so vorstellen, dass man dem Filter auch 3 Kanäle spendiert. Die Operation ist wie im 2D-Fall einfach eine komponentweise Multiplikation mit einer anschließenden Summenbildung. Bei den drei Kanälen hat man quasi drei einzelne Konvolutionen, die man einfach zusammenaddiert.
Man beachte, dass das Resultat eine 2-dimensionale 2x4-Matrix ist, d.h. \({n'}_c = 1\), wenn wir mit \({n'}_c\) die Kanäle der Ausgabematrix bezeichnen.
Der Filter kann entweder jeweils der gleiche Filter sein (hier: Detektor für vertikale Kanten) oder auch unterschiedliche Filter enthalten für den jeweiligen Kanal (R, G oder B). Ein Kanalfilter kann auch nur aus Nullen bestehen und somit den Farbkanal ignorieren.
Da wir bereits wissen, dass unser Netz die Werte des Filter lernt, können wir uns vorstellen, dass ein Netz in unterschiedlichen Farbkanälen unterschiedliche Features detektieren will.
Wichtig ist, dass der Filter immer exakt so viele Kanäle haben muss wie die Eingabe. Hier wird klar, warum wir oben gesagt haben, dass die Operation auf 2D-Daten verläuft. Wir haben hier keine räumliche dritte Dimension, es handelt sich lediglich um Kanäle eines 2D-Bildes.
Kanäle werden eingedampft
Sie sollten sich zwei Dinge merken, wenn Sie es mit mehreren Kanälen zu tun haben. Erstens: Der Filter muss genauso viele Kanäle haben wie der Input. Zweitens: Die Kanäle werden “eingedampft” zu einem einzigen Kanal.
Beispiel
Ein Beispiel mit echten Zahlen, um zu zeigen, wie man die Kanäle hinschreiben könnte:
Rechnen Sie zur Übung gern das Beispiel durch. Die Ergebnismatrix hat nur noch einen Kanal.
Formal
Wir bezeichnen wieder das Bild als \(I\), den Filter als \(F\) und die Outputmatrix als \(O\) mit Komponenten \(o_{i,j}\):
\[ o_{i,j} = (I * F)_{i,j}\]
Bei der Berechnung nehmen wir noch die Kanäle (Anzahl der Kanäle ist \(n_c\)) mit der Laufvariablen \(c\) hinzu, ansonsten ist es die gleiche Formel wie (KV) oben:
wobei \(i = 1, \ldots, \bar{n}_H\) und \(j = 1, \ldots, \bar{n}_W\).
10.4.2 Mehrere Filter
Oben haben wir gesehen, dass man eine Eingabe mit mehreren Kanälen durch einen 3-dimensionalen Filter verarbeiten kann. Dabei werden die Kanälen quasi “eingedampft”.
Jetzt kann es sein, dass wir in einem Schritt mehrere unterschiedliche Filter parallel auf ein Bild anwenden möchten, z.B. zwei Filter: einen für horizontale Kanten und einen für vertikale Kanten.
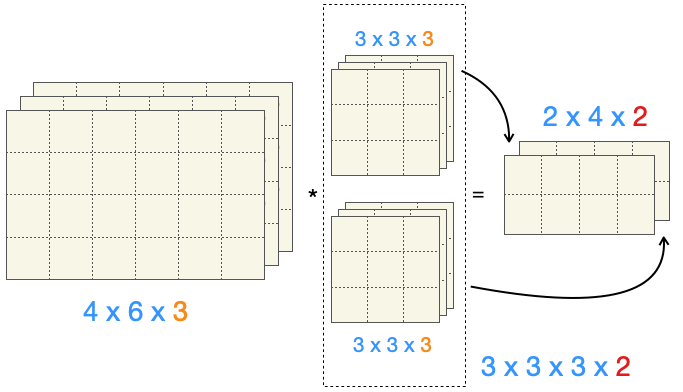
Wir möchten die Resultate der zwei Filter auch parallel weiterführen. Da bei jedem Filter eine 2-dimensionale Ausgabe erfolgt, haben wir als Endresultat eine 3-dimensionale Matrix, weil wir die beiden Ausgaben einfach “übereinander” legen:
Das obige Beispiel sehen wir uns nochmal in Zahlen an:
das Eingabebild ist ein 4x6x3-Tensor (3 Kanäle, orange)
jeder Filter ist ein 3x3x3-Tensor (auch hier 3 Kanäle, orange)
die zwei Filter zusammen genommen bilden einen 3x3x3x2-Tensor (zwei in rot)
die Ausgabe nach Anwendung eines Filters ist eine 2x4-Matrix
beide Ausgaben zusammen genommen bilden einen 2x4x2-Tensor (die zwei, in rot, geht auf die zwei Filter zurück)
Schauen wir uns das als Schema für eine Konvolutionsschicht an (Abb. unten). Hier geben wir die Anzahl der Kanäle der Eingabe an. Die Tatsache, dass die zwei Filter auch 3 Kanäle haben, brauchen wir nicht zu notieren. Ansonsten sehen wir, dass die Anzahl der Filter sich in der Anzahl der Kanäle der Ausgabe wiederfindet.
Obwohl wir hier teilweise sehr viele Filter parallel anwenden und wir 3 Kanäle behandeln, bleibt es dabei, dass wir ein 2D-Bild verarbeiten.
Pro Filter ein Kanal im Output
Bei mehreren Filtern sollten Sie sich merken, dass jeder Filter einen Kanal in der Ausgabe “erzeugt”.
Siehe auch: Im Skript der Univ. Stanford zu CNNs finden Sie eine schöne animierte Grafik zur Konvolutionsoperation mit mehreren Kanälen und mehreren Filtern (auf der Seite nach “Convolution Demo” suchen).
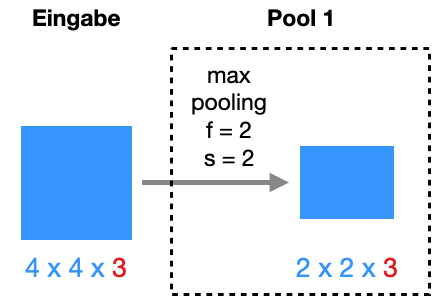
10.4.3 Pooling
Pooling ist im Vergleich zu Convolution eine einfache Operation und wird wie Convolution als eine Verarbeitungsschicht implementiert. Bei einer Pooling-Schicht geht es lediglich darum, die Größe der Eingabe zu reduzieren, um die Anzahl der Parameter zu reduzieren, um die Generalisierung zu erhöhen und größere “Toleranz” zu erwirken. Pooling kann man auch als eine Form von Subsampling bezeichnen.
Auch beim Pooling wird ein Filter als Sliding Window über die Eingabe geschoben. Auf die von den Zellen der Filtermatrix überdeckten Zahlen wird eine einfache Operation ausgeführt, meistens das Maximum, man spricht dann auch von Max Pooling. Alternativ kann auch der Durchschnitt berechnet werden, dann spricht man von Average Pooling oder Mean Pooling.
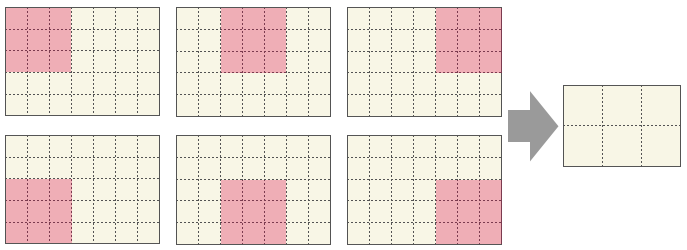
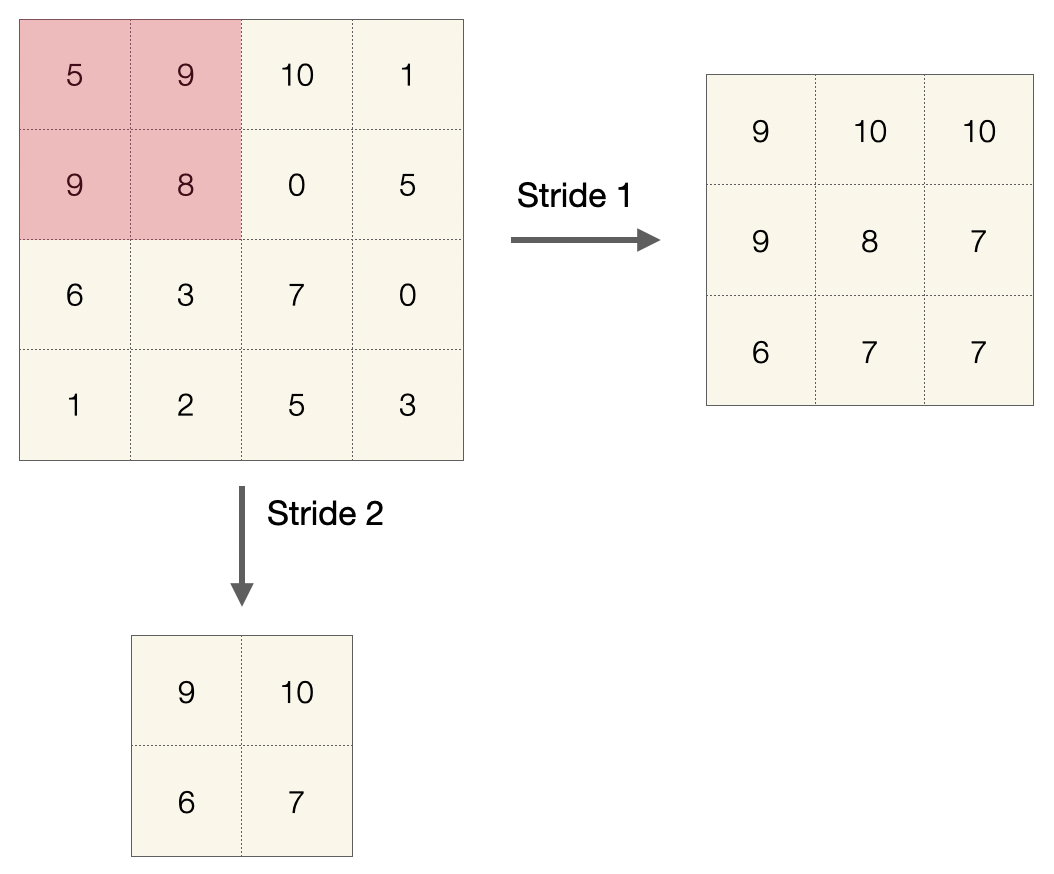
Auch hier gibt es eine Filtergröße \(f\) und einen Stride \(s\). Hier zwei Beispiele von Max Pooling mit einem 2x2-Filter (\(f=2\)) und einer Eingabe mit Dimensionen 4x4. Bei einem Stride von \(s=1\) wird die Eingabe auf 3x3 reduziert, bei Stride \(s=2\) auf nur 2x2.
Was passiert mit “Restpixeln” bei Konvolution und Pooling?
Was passiert bei einer Inputgröße von 4x4 (wie oben) bei einer Filtergröße von 3x3 (egal welcher Stride)? Der letzte Pixel “passt” nicht mehr. Die Antwort ist: Überzählige Pixel (Elemente) werden einfach ignoriert. In diesem Fall entsteht ein Output der Größe 1x1.
Sollte die Eingabe 3 Kanäle haben, wird einfach auf jedem Kanal Pooling angewandt, d.h. die Ausgabe hat wieder 3 Kanäle. Allgemein bleibt also \(n_c\) identisch.
Hier eine schematische Darstellung einer Pooling-Schicht:
10.4.4 Formale Definition der Konvolutionsschicht
Wir haben die Konvolution in der Formel (KV) definiert, aber noch ohne Kanäle und Anzahl der Filter. Schauen wir uns (KV) nochmal an:
Wenn wir uns an FNN erinnern, dann haben wir dort unterschieden zwischen Roheingabe \(z\) und Aktivierung \(a\). In (KV) haben wir folgende Entsprechungen:
\(I_{i+h, j+k}\) entspricht der Aktivierung \(a\) der vorgelagerten Schicht \(l-1\)
\(F_{h+1, k+1}\) entspricht den Gewichten \(w\) des Filters der vorgelagerten Schicht \(l-1\)
\(o_{i,j}\) entspricht der Roheingabe \(z\) der Schicht \(l\)
Daher können wir die Variablen wie folgt ersetzen:
Wir bezeichnen die Anzahl der Kanäle mit \(n_C\) und die Anzahl der Filter mit \(n_F\). Die Filter unterscheiden wir mit einem hochgestellten Index: \(W^{<1>}, \ldots, W^{<n_F>}\).
Unsere Formel bekommt einen Parameter \(m\) für den Filter \(W^{<m>}\). Daraus resultiert der Kanal des Outputs.
Jetzt nehmen wir noch die Kanäle hinzu (Summe über \(c\)) und wir addieren ein Bias-Gewicht\(b\) pro Filter, um den Rohinput für Schicht \(l\) zu definieren:
Wie schon bei den FNN entspricht die Eingabe \(x\) der Aktivierung der ersten Schicht \(a^{(1)}\) und die Aktivierung der letzten Schicht \(a^{(L)}\) entspricht der Ausgabe \(\hat{y}\) des Netzes.
10.5 Beispiele für Konvolutionsnetze
10.5.1 CNN mit zwei Konv-Schichten
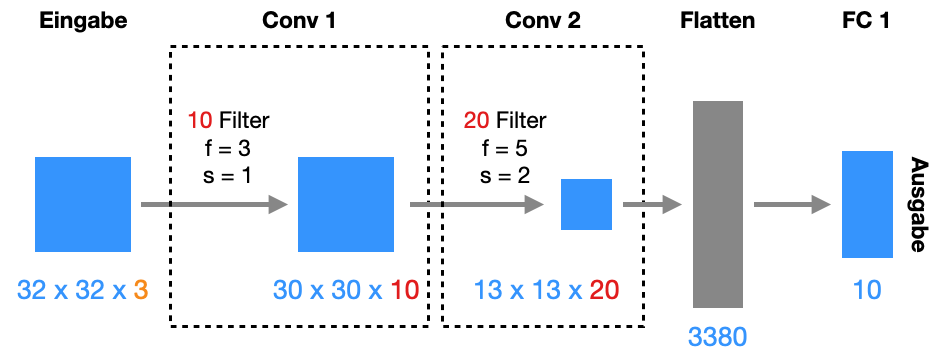
Hier ein einfaches CNN mit zwei Konvolutionsschichten:
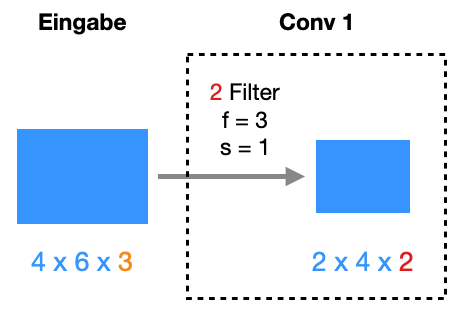
Die Eingabe besteht aus Bildern der Größe 32x32 mit 3 Farbkanälen (RGB).
Die erste Schicht Conv1 hat 10 3x3-Filter, genauer gesagt sind es 3x3x3-Filter. Der Stride ist 1 und es gibt kein Padding. Also wird die Bildgröße reduziert. Die Ausgabe hat die Größe 30x30x10. Die “10” kommt von der Anzahl der Filter. Die Bildgröße können Sie mit folgender Formel ausrechnen:
Die zweite Schicht Conv2 hat 20 5x5-Filter, genauer gesagt sind es 5x5x10-Filter. Der Stride ist 2 und es gibt kein Padding. Hier wird wieder die Größe reduziert auf 13x13 (siehe Formel oben). Durch die 20 Filter bekommen wir 13x13x20.
Die dritte Schicht Flatten linearisiert ledigleich unseren 13x13x20-Tensor zu einem Vektor der Länge 3380.
Die vierte Schicht FC 1 ist die Ausgabeschicht mit 10 Neuronen (für zehn mögliche Kategorien). Diese Schicht ist natürlich komplett verdrahtet mit der vorigen Schicht, also ist die Schicht vom Typ Fully Connected (oder in Keras: Dense).
10.5.2 Parameter
Wir können ausrechnen, wie viele Parameter das Netz hat. Wir rechnen die Anzahl der Filter mal der Filtergröße und addieren die Länge des Biasvektors (= Anzahl der Filter).
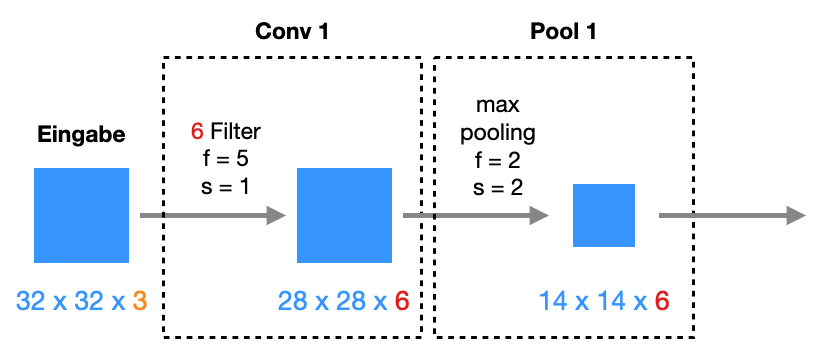
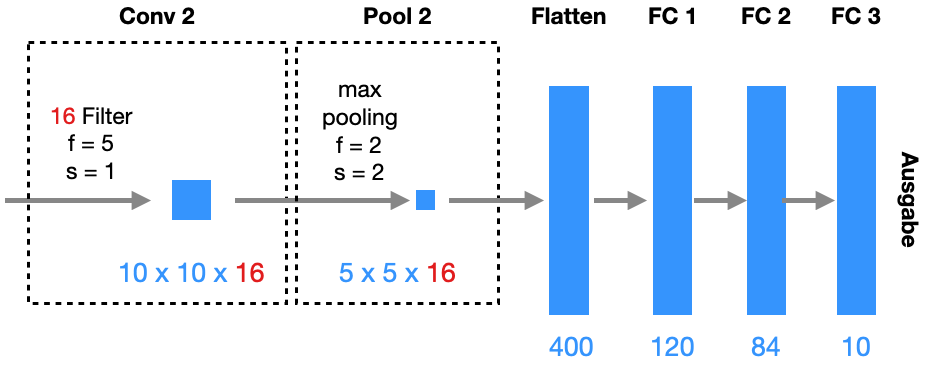
Wir schauen uns jetzt ein komplexeres CNN an, das ähnlich dem berühmten LeNet-5 ist:
Im Vergleich zum obigen Netz haben wir hier Pooling-Schichten mit jeweils Filtergröße 2x2 und Stride 2. Diese Operation halbiert jeweils die Anzahl der Zeilen und Spalten.
Parameter
Auch hier können wir rechnen. Die Pooling-Schichten und die Flatten-Schicht haben natürlich keine Parameter:
Unser Netz hat also 62006 Parameter und damit nur doppelt so viele wie das deutlich einfachere Netz oben. Das liegt natürlich hauptsächlich an den Pooling-Schichten, die unsere Tensoren deutlich reduzieren, bevor wir zu den “teuren” FC-Schichten kommen.
10.6 Backpropagation in einer Konv-Schicht (optional)
Wir haben gesehen, dass eine Konvolutionsschicht im Grunde eigene Filter “lernt”, indem es die Werte der Filter als Gewichte betrachtet, die angepasst werden. Hier versuchen wir, eine Intuition zu bekommen, wie diese Gewichte in den Filtern (und des Bias-Werts) gelernt werden.
Erinnern wir uns zunächst, wie in einem FNN mit FC-Schicht die Gewichte angepasst werden. Die Formel für das Delta eines Gewichts ist wie folgt:
(Siehe Formel W im Kapitel über Backpropagation, Abschnitte 8.4.6 und 8.4.6.)
Das Gewicht zeigt von einem Quellneuron \(j\) mit Aktivierung \(a_j\) auf ein Zielneuron \(i\) in der nächsten Schicht. Das Delta ist der Fehler \(\delta_i\) dieses Zielneurons \(i\). Das \(a_j\) ist die Aktivierung des Quellneurons \(j\).
Vergleichen wir das mit der Situation in einer Konvolutionsschicht. Wir haben bereits gesehen, dass ein einzelnes Gewicht mehrere Quell- und Zielneuronen verbindet, insofern kann die obige Formel nicht ohne weiteres gelten.
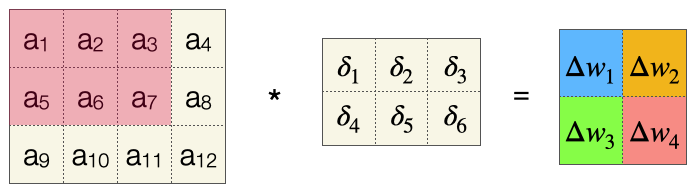
In einer Konvolutionsschicht liegen die Quellneuronen als Matrix vor. Das Ergebnis der Konvolution können wir als Ausgabe betrachten - dies ist wiederum eine Matrix. Wir sehen uns dazu folgendes Beispiel mit einem 4x4-Filter an (kein Padding, Stride 1).
Wenn wir die Konvolutionsoperation verfolgen, sehen wir, dass jedes Gewicht mehrfach zur Anwendung kommt. Wir betrachten exemplarisch Gewicht \(w_1\). Dieses Gewicht kommt sechs Mal zum Einsatz, bei den Aktivierungen \(a_1, a_2, a_3, a_5, a_6, a_7\). Hier ist das schematisch dargestellt:
Wenn wir das Delta von \(w_1\) berechnen wollen, benötigen wir die Ableitung des Fehlers hinsichtlich \(w_1\):
Zu beachten ist, dass \(z\) ein Vektor der Länge 6 ist.
Wir haben in unserer Herleitung von Backpropagation den Fehler \(\delta\) als \(\frac{\partial J}{\partial z}\) definiert (siehe Abschnitt 8.2.3). Das \(\delta\) ist ein Vektor der gleichen Länge wie \(z\), weil es ja die jeweiligen Fehler von \(z\) darstellt. Also können wir den Vektor \(\delta\) für \(z\) einsetzen, gleich mit Komponenten. Die Ableitungen \(\frac{\partial}{\partial w_1} z_i\) ergeben sich aus den Summen für den Rohinput (siehe Abb. oben), wo jeweils der Faktor von \(w_1\) übrig bleibt:
Wir sehen, dass die Formel praktisch identisch zu der herkömmlichen Backpropagation-Formel (*) ist, nur dass alle “Verbindungen” aufsummiert werden.
Interessant ist, dass diese Summe, also die Berechnung des \(\Delta w_i\), das Ergebnis einer Konvolution ist, die wie folgt formuliert werden kann:
Die obige Konvolution kommt also beim Backpropagation-Algorithmus zum Einsatz, um aus den Fehlerwerten \(\delta\) die entsprechenden Gewichtsänderungen zu berechnen.
Damit haben Sie hoffentlich eine Intuition dafür, wie Backpropagation in einer Konvolutionsschicht funktioniert. Wir werden den Algorithmus hier nicht weiter ausführen. Details können Sie aber in dem exzellenten Artikel Backpropagation In Convolutional Neural Networks von Jefkine Kafunah nachlesen.
10.7 Keras: Konvolutionsnetze und Early Stopping
Jetzt sehen wir uns an, wie wir Konvolutionsnetze in Keras realisieren. Im Grunde benötigen wir lediglich neue Schichten. In Keras gibt es zwei Typen von Schichten für CNNs - Conv2D und MaxPooling2D - und bei der Gelegenheit stellen wir auch die Schicht Flatten vor. Anschließend stellen wir noch die Methode des Early Stopping vor.
10.7.1 Conv2D
Die Con2D-Schicht ist eine Konvolutionsschicht für ein 2D-Inputbild mit mehreren Kanälen. Der erste Parameter filters gibt die Anzahl der Filter an (z.B. 10), der zweite Parameter kernal_size gibt die Größe \(f\) des Filters an, entweder als Skalar - z.B. 5 - oder als Tupel - z.B. (5, 5). Parameter strides gibt den Stride \(s\) als Skalar oder als Tupel (in Höhe und Breite) an und padding gibt an, ob man Padding benutzt (“same”) oder nicht (“valid”).
Es ist optional, eine Aktivierungsfunktion zu verwenden, ebenso ist es optional einen Bias-Term zu verwenden. Beides kann man in den Parametern spezifizieren.
Ist diese Schicht die erste Schicht, so kommt der Parameter input_shape hinzu, z.B. (28, 28, 3) für eine RGB-Bild. Die Tatsache, dass die Kanäle an dritter Stelle spezifiziert werden, ergibt sich aus dem standardmäßigen data_format von “channels_last”. Man kann dies umstellen auf “channels_first”.
Ein Beispiel für ein ConvLayer mit 10 Filtern mit \(f=5\), \(s=1\) und \(p=2\) (ergibt sich aus padding=‘same’):
model = models.Sequential()
model.add(Conv2D(10, 5, strides=1, padding='same', activation='relu'))
Das gleiche hätte man auch mit Tupeln schreiben können:
Dies ist eine Pooling-Schicht, die das Maximum nimmt. Man kann die Filtergröße \(f\) mit pool_size bestimmen und den Stride \(s\) mit strides. Beides geht als Skalar oder als Tupel. Hier als Tupel:
MaxPooling2D(
pool_size=(2, 2),
strides=(1, 1)
)
Hier mit Skalaren:
MaxPooling2D(
pool_size=2,
strides=1
)
Wenn “strides” nicht angegeben wird, ist es standardmäßig gleich der pool_size. Im folgenden Fall ist also \(s=2\):
Diese Schicht linearisiert einen multi-dimensionalen Eingabetensor zu einem einfachen Vektor. Zum Beispiel wird eine 10x10x3x20 Eingabe zu einem Vektor der Länge 6000. Entsprechend gibt es keine Parameter, es handelt sich um eine reine Umformungs-Schicht (Reshaping Layer).
Overfitting bedeutet, dass ein Modell sich zu stark auf den Trainingsdatensatz spezialisiert und daher nicht gut generalisiert. Dies kann man beim Training beobachten, wenn man einen Validierungs-Datensatz verwendet (siehe auch Abschnitt 2.4.2). In Keras funktioniert das mit Hilfe des Parameters validation_split bei der Methode fit.
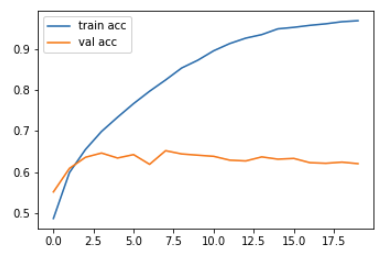
Häufig sieht man, dass die Performance auf den Validierungsdaten ab einem bestimmten Punkt sinkt. Die folgende Abbildung zeigt die Accuracy auf Trainings- und Validierungsdaten über die Trainingsepochen hinweg.
Wir möchten also das Netzwerk in dem Zustand als Modell wählen, in dem es war, als die Accuracy auf den Validierungsdaten am höchsten war, denn in diesem Zustand generalisiert es wahrscheinlich am besten. Wenn das so ist, muss man das Netz natürlich auch nicht so lange trainieren, sondern kann früher mit dem Training aufhören. Das nennt man auch Early Stopping und ist eine offensichtliche Methode gegen Overfitting.
In Keras funktioniert Early Stopping so, dass man der Trainingsmethode eine Callback-Funktion mitgibt, die das Training quasi überwacht und abbricht, sobald die Performance auf den Validierungsdaten sinkt.
Schritt 1 ist also, die Funktion (ein Objekt) zu defineren:
Parameter monitor gibt an, welchen Wert man beobachten möchte, und mit mode sagt man, ob dieser maximal oder minimal (z.B. für loss) sein soll. Mit patience spezifiziert man die Zahl der Epochen, die man “weitermacht”, obwohl der Wert in die falsche Richtung geht. Schließlich kann man mit restore_best_weights angeben, dass die Gewichte des Zeitpunkts genommen werden, wo der beobachtete Wert optimal war.
Schritt 2 ist dann, die Funktion der Methode fit mitzugeben, die ja das Training ausführt. Da man eine Reihe von Callback-Funktionen übergeben kann, spezifiziert man eine Liste:
history = model.fit(x_train, y_train,
epochs=20,
validation_split=0.1,
callbacks=[monitor])
Wie Sie sehen, gibt man dennoch die Zahl der Epochen an. Das ist in diesem Kontext die maximale Zahl der Epochen, die trainiert wird. Beachten Sie auch validation_split, wo wir 10% der Trainingsdaten als Validierungsdaten nehmen und nicht die Testdaten. Das ist bei Early Stopping besonders wichtig, da wir ja nicht auf den Testdaten optimieren dürfen und später die Performance auf den selben Daten messen können.
Wir probieren unser Wissen in Keras aus. Zunächste definieren wir die maximale Anzahl der Epochen:
epochs =20
Daten: CIFAR-10
Als Daten nehmen wir CIFAR-10, die wir bereits aus Abschnitt 9.3.2 kennen. Das Material besteht aus 60000 32x32-Bildern mit 3 Farbkanälen (RGB). Davon sind 50000 Trainingsdaten und 10000 Testdaten.
from tensorflow.keras.datasets import cifar10(x_train, y_train), (x_test, y_test) = cifar10.load_data()x_train.shape
(50000, 32, 32, 3)
Wir nutzen One-Hot-Encoding:
from tensorflow.keras.utils import to_categoricaly_train = to_categorical(y_train, 10)y_test = to_categorical(y_test, 10)
Wir normalisieren die Daten:
x_train = x_train/255.0x_test = x_test/255.0
Modell
Wir erzeugen zwei Konvolutionsschichten mit jeweils nachgelagerten Pooling-Schichten:
Konv-Schicht mit 10 Filtern, \(f=5, p=2\)
Max-Pooling-Schicht mit \(f=2\) und \(s=2\)
Konv-Schicht mit 20 Filtern, \(f=3, p=1\)
Max-Pooling-Schicht mit \(f=2\) und \(s=2\)
Bei den Konv-Schichten ist standardmäßig \(s=1\).
from tensorflow.keras.models import Sequentialfrom tensorflow.keras.layers import Dense, Flatten, Conv2D, MaxPool2Dmodel = Sequential()model.add(Conv2D(filters=10, kernel_size=5, activation='relu', padding='same', input_shape=x_train[0].shape))model.add(MaxPool2D(pool_size=2)) # stride ist somit 2model.add(Conv2D(filters=20, kernel_size=3, activation='relu', padding='same'))model.add(MaxPool2D(pool_size=2)) # stride ist somit 2model.add(Flatten())model.add(Dense(200, activation='relu'))model.add(Dense(10, activation='softmax'))model.summary()
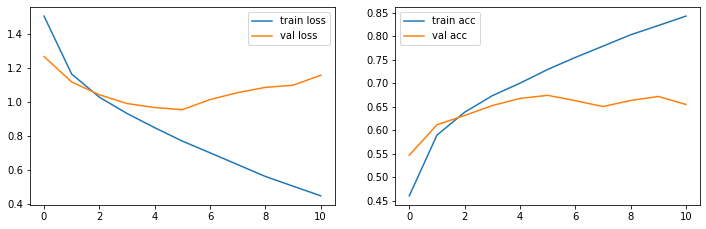
Das Netz hat das Training nach Epoche 11 abgebrochen.
Evaluation
import matplotlib.pyplot as pltplt.figure(figsize=(12, 8))plt.subplot(2, 2, 1)plt.plot(history.history['loss'], label='train loss')plt.plot(history.history['val_loss'], label='val loss')plt.legend()plt.subplot(2, 2, 2)plt.plot(history.history['acc'], label='train acc')plt.plot(history.history['val_acc'], label='val acc')plt.legend()loss, acc = model.evaluate(x_test, y_test, verbose=0)print(f"\n++++++++++++ Test data ++++++++++++\nloss={loss:.4f} acc={acc:.4f}")
++++++++++++ Test data ++++++++++++
loss=1.0052 acc=0.6636
Unser Modell erzielt 66% Accuracy auf den Testdaten von CIFAR-10. Wenn Sie die Übungsaufgabe gemacht haben, haben Sie einen Wert von ca. 45-55% mit einem FNN erzielt. Man sieht also, dass CNN wesentlich besser für Bilder geeignet sind.
Fukushima, Kunihiko. 1980. “Neocognitron: A Self-Organizing Neural Network Model for a Mechanism of Pattern Recognition Unaffected by Shift in Position.”Biological Cybernetics 36 (4): 193–202.
Fukushima, Kunihiko, Sei Miyake, and Takayuki Ito. 1983. “Neocognitron: A Neural Network Model for a Mechanism of Visual Pattern Recognition.”IEEE Transactions on Systems, Man, and Cybernetics SMC-13 (5): 826–34.
Khan, A., A. Sohail, U. Zahoora, and A. S. Qureshi. 2020. “A Survey of the Recent Architectures of Deep Convolutional Neural Networks.”Artificial Intelligence Review 53: 5455–5516. https://arxiv.org/abs/1901.06032.
Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. 2012. “ImageNet Classification with Deep Convolutional Neural Networks.”Communications of the ACM 60 (6): 84–90. https://dl.acm.org/doi/10.1145/3065386.
LeCun, Y., B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, and L. D. Jackel. 1989. “Backpropagation Applied to Handwritten Zip Code Recognition.”Neural Computation 1 (4): 541–51. https://doi.org/10.1162/neco.1989.1.4.541.
LeCun, Y., L. Bottou, Y. Bengio, and P. Haffner. 1998. “Gradient-Based Learning Applied to Document Recognition.”Proceedings of the IEEE 86 (11): 2278–2324. https://doi.org/10.1109/5.726791.
Schmidhuber, Jürgen. 2015. “Deep Learning in Neural Networks: An Overview.”Neural Networks 61: 85–117. https://arxiv.org/abs/1404.7828.


{kind=link}