sum = 0
# Laufe von 1 bis 3
for i in range(1, 4):
sum += i
sum6Dieses Kapitel dient der Vorbereitung für den eigentlichen Stoff. Wir benötigen einerseits bestimmte mathematische Grundlagen für die Theorie und andererseits Programmierkenntnisse für die praktischen Anteile.
Zu den mathematischen Grundlagen gehören mathematische Notation, Aspekte der Linearen Algebra (Vektoren und Matrizen) sowie der Analysis (einfache und partielle Ableitungen). Wir zeigen auch anhand der Python-Library NumPy, wie Vektor- und Matrizenrechnung programmiertechnisch gehandhabt werden kann.
Was die Programmierkenntnisse angeht, so verwenden wir die Sprache Python. Es wird vorausgesetzt, dass Sie Python können oder sich selbständig aneignen. Wenn Sie eine andere Programmiersprache wie Java können, sollte das kein Problem sein. Dieses Kapitel enthält keine Einführung in Python, sondern zeigt lediglich ein paar relevante Aspekte der Sprache.
Summenzeichen, Produktzeichen, Zeilenvektor, Spaltenvektor, Matrix/Matrizen, Matrixmultiplikation, Tensor, Ableitung, Lagrange- und Leibniznotation, partielle Ableitung, Gradient, Kettenregel, NumPy (Array, shape und reshape), Python Printausgabe, Python List und Dictionary Comprehension, Python-Klassen
Die Inhalte dieses Kapitels werden nicht in der Vorlesung selbst behandelt, sondern werden vorausgesetzt. Nutzen Sie das Kapitel, um entsprechende Inhalte selbständig aufzuarbeiten, sofern diese nicht bekannt sind.
Im ersten Teil des Kapitels klären wir mehrere relevante mathematische Konzepte und Begriffe. Besonders wichtig im Bereich Neuronaler Netze sind Matrizen und Matrixmultiplikation. Wenn Sie den Begriff “Matrix” nicht aus Schule oder Studium kennen, würde ich sehr empfehlen, sich die entsprechenden Operationen genau anzusehen und ein paar Beispiele von Hand zu berechnen.
Wenn Ihre Mathematrik etwas eingerostet ist, hier ein paar Quellen zum Auffrischen:
Um eine Summe abzukürzen, gibt es die sogenannte Sigma-Notation. Sigma ist ein griechischer Buchstabe, der Großbuchstabe wird so dargestellt: \(\Sigma\)
Die Sigma-Notation funktioniert ähnlich einer For-Schleife in der Programmierung. Es gibt eine Laufvariable, z.B. \(k\) mit einem Startwert und einem Endwert. Das Sigma produziert für jeden “Schleifendurchlauf” einen Summanden. In dem folgenden Beispiel gibt es die Laufvariable \(k\) mit Startwert \(1\) und Endwert \(3\). Hinter dem Summenzeichen steht, wie ein einzelner Summand aussehen soll. Hier ist es einfach die Laufvariable selbst:
\[ \sum_{k=1}^3 k = 1 + 2 + 3 \]
Man kann aber die Laufvariable auch in Ausdrücke einbauen:
\[ \sum_{k=1}^3 2\,k + 1 = (2\cdot1 + 1) + (2\cdot2 + 1) + (2\cdot3 + 1) = 15\]
Hier ein Beispiel, wo die Laufvariable als Potenz benutzt wird:
\[ \sum_{k=1}^3 2^k = 2^1 + 2^2 + 2^3 = 14 \]
Schließlich kann die Laufvariable auch verwendet werden, um einen Index anzusprechen. Gegeben seien vier Werte in vier indizierten Variablen \(a_1, a_2, a_3, a_4\). Dann können wir diese werden wie folgt addieren:
\[ \sum_{k=1}^4 a_k = a_1 + a_2 + a_3 + a_4 \]
So kann man z.B. sehr kompakt Polynome vierten Grades definieren. Man beachte, dass wir bei \(0\) starten müssen, um den ersten Term ohne \(x\) zu erhalten.
\[ \sum_{k=0}^4 a_k x^k = a_0 + a_1 x + a_2 x^2 + a_3 x^3 + a_4 x^4 \]
Oft wird auch der Endwert mit Hilfe einer Variablen definiert:
\[ \sum_{k=1}^n x_k = x_1 + x_2 + \ldots + x_n \]
Wenn aus dem Kontext klar ist, was Start- und Endwert sind, werden diese auch weggelassen:
\[ \sum_{k} x_k \]
Selbst die Laufvariable wird in solchen Fällen fallen gelassen:
\[ \sum x_k \]
Wir schauen uns an, wie wir eine Summe in Python nachbilden würden. Beachten Sie, dass bei der Funktion range der zweite Werte exklusiv ist, d.h. die Sequenz läuft bis zum Endwert minus eins.
\[ \sum_{k=1}^3 k = 1 + 2 + 3 = 6\]
sum = 0
# Laufe von 1 bis 3
for i in range(1, 4):
sum += i
sum6Jetzt realisieren wir die folgende Summe:
\[ \sum_{k=1}^3 2^k = 2^1 + 2^2 + 2^3 = 14 \]
Beachten Sie, dass in Python mit dem Operator ** potenziert wird.
sum = 0
# Laufe von 1 bis 3
for i in range(1, 4):
sum += 2**i
sum14Analog zum Summenzeichen gibt es für das Produkt mehrere Werte das große griechische Pi: \(\Pi\)
Auch hier haben wir eine Laufvariable mit Start- und Endwert.
Einige Beispiele:
\[ \prod_{k=1}^3 k = 1 \cdot 2 \cdot 3 = 6 \]
\[ \prod_{k=1}^3 x_k = x_1 \cdot x_2 \cdot x_3 \]
\[ \prod_{k=1}^n x_k = x_1 \cdot x_2 \cdot \ldots \cdot x_n \]
Wir gehen hier ganz kompakt über alle Konzepte, die Sie kennen sollten.
Boyd and Vandenberghe (2018) bieten ein empfehlenswertes Buch zur linearen Algebra zum kostenlosen Download an. Relevant wären Kapitel 1, 6 und 10.
Skalare sind einfach Zahlen, also z.B. \(3\) oder \(-1\).
In der Regel aus dem Raum der reellen Zahlen \(\mathbb{R}\).
Wir verwenden die amerikanische Schreibweise von Kommazahlen, d.h. wir trennen die Nachkommastellen mit einem Punkt:
\[ 1.5 \]
Ein Vektor ist eine geordnete Reihe von Zahlen. Die Anzahl der Zahlenwerte nennt man auch die Dimension oder die Länge des Vektors. Man kann einen Vektor als Zeilenvektor schreiben, dann werden die Zahlen durch Komma getrennt. Hier ein Beispiel für einen Zeilenvektor der Länge 3:
\[(13, 25, 8) \]
Manchmal werden die Kommas auch weggelassen:
\[(13 \quad 25 \quad 8) \]
Da der Begriff “Dimension” missverständlich ist, sprechen wir von der Länge eines Vektors. Siehe auch den Hinweis bei Matrix.
Jede einzelne Zahl nennt man Komponente oder Element des Vektors. Wenn die Komponenten reelle Zahlen sind, befinden sich die Vektoren im Raum \(\mathbb{R}^3\).
Man kann diesen Vektor auch als Spaltenvektor schreiben:
\[ \left( \begin{array}{c} 13 \\ 25 \\ 8 \end{array} \right) \]
Wenn wir Vektoren mit Variablen ausdrücken, verwenden wir kleine Buchstaben, z.B.
\[ a = \left( \begin{array}{c} 13 \\ 25 \\ 8 \end{array} \right) \]
Die einzelnen Elemente eines Vektors werden mit dem gleichen Buchstaben plus Index dargestellt:
\[ a = \left( \begin{array}{c} a_1 \\ a_2 \\ a_3 \end{array} \right) \]
Die Zählung der Indexwerte beginnt mit 1. In der Informatik beginnt man oft mit 0, z.B. für die Indizes bei einem Array. Wenn nichts anderes gesagt wird, ist ein Vektor immer ein Spaltenvektor.
Zwei Vektoren der gleichen Länge kann man komponentenweise addieren.
\[ \left( \begin{array}{c} 13 \\ 25 \\ 8 \end{array} \right) + \left( \begin{array}{c} 1 \\ -1 \\ 0 \end{array} \right) = \left( \begin{array}{c} 14 \\ 24 \\ 8 \end{array} \right) \]
Das Skalarprodukt ist eine Möglichkeit, zwei Vektoren zu multiplizieren. Beide Vektoren müssen die gleiche Länge haben. Dann werden jeweils die Komponenten mit gleichem Index mulitpliziert und die Ergebnisse addiert. Das Endergebnis der Multiplikation ist eine Zahl, also ein Skalar.
Man nennt das Skalarprodukt auch inneres Produkt, im Englischen dot product.
Hier ein Beispiel für das Skalarprodukt zweier Vektoren der Länge 3:
\[ \left( \begin{array}{c} 13 \\ 25 \\ 8 \end{array} \right) \cdot \left( \begin{array}{c} 1 \\ -1 \\ 0 \end{array} \right) = 13 \cdot 1 + 25 \cdot (-1) + 8 \cdot 0 = -12 \]
Die zweite Möglichkeit, zwei Vektoren zu multiplizieren, ist das Kreuzprodukt (auch äußeres Produkt), das aber hier nicht benötigt wird.
Man kann einen Vektor mit einem Skalar multiplizieren, indem man jede Komponente mit dem Skalar multipliziert:
\[ 2 \, \left( \begin{array}{c} 13 \\ 25 \\ 8 \end{array} \right) = \left( \begin{array}{c} 2 \cdot 13 \\ 2 \cdot 25 \\ 2 \cdot 8 \end{array} \right) = \left( \begin{array}{c} 26 \\ 50 \\ 16 \end{array} \right)\]
Diese Multiplikation wird manchmal wegen der Namensähnlichkeit mit dem “Skalarprodukt” (s.o.) verwechselt.
Die Operation des Transponierens verwandelt einen Zeilenvektor in einen Spaltenvektor und umgekehrt. Die Operation wird durch ein hochgestelltes \(T\) angezeigt.
Zum Beispiel:
\[ a = \left( \begin{array}{c} 13 \\ 25 \\ 8 \end{array} \right) \]
Dann gilt:
\[a^T = (13, 25, 8)\]
Zweites Beispiel:
\[b = (3, 2, 5)\]
Dann gilt:
\[ b^T = \left( \begin{array}{c} 3 \\ 2 \\ 5 \end{array} \right) \]
Das zweifache Anwendung der Transposition ergibt wieder den ursprünglichen Vektor:
\[ (a^T)^T = a \]
Gute Darstellungen sind auf Wikipedia unter Matrix und auf YouTube von Daniel Jung Aufbau Matrix/Matrizen, Koeffizienten, Zeile, Spalte, Addieren.
Eine Matrix - im Plural Matrizen - ist ein rechteckiges Raster von Skalaren. Einfacher gesagt, kann man sich eine Matrix wie in eine Tabelle mit Zeilen und Spalten vorstellen, z.B.
\[\begin{pmatrix} 5 & 3 \\ 21 & -1 \\ 9 & 33 \end{pmatrix} \]
Die Dimension oder Form einer Matrix ergibt sich aus der Anzahl der Zeilen und der Anzahl der Spalten.
Im Beispiel handelt es sich um eine 3x2-Matrix (gesprochen “drei mal zwei Matrix”), da die Matrix 3 Zeilen und 2 Spalten hat. Wichtig ist, dass Sie sich die Reihenfolge erst Zeilen, dann Spalten merken.
Bei der obigen Matrix sagt man auch die Matrix hat die Form, engl. Shape, 3x2. Der Begriff Dimension ist potenziell missverständlich. Warum eigentlich? Man kann Dimension einerseits so verwenden, dass man sagt: Ein Vektor ist eine 1-dimensionale Struktur und eine Matrix ist eine 2-dimensionale Struktur. Andererseits repräsentieren wir Punkte im 2-dimensionalen-Raum durch einen (1-dimensionalen) Vektor der Länge 2 und Punkte im 3D-Raum durch einen (1-dimensionalen) Vektor der Länge 3. Der Begriff Dimension hat also offensichtlich zwei unterschiedliche Lesarten und sorgt daher manchmal für Verwirrung.
Daher benutzen wir für Vektoren den Begriff Länge und für Matrizen den Begriff Form oder Shape. Ein Vorteil des englischen Begriffs shape ist, dass er auch bei der Python-Bibliothek NumPy verwendet wird, die wir für Vektor- und Matrixrechnung benutzen werden.
Wir verwenden große Buchstaben, um Matrizen zu bezeichnen:
\[A = \begin{pmatrix} 5 & 3 \\ 21 & -1 \\ 9 & 33 \end{pmatrix} \]
Die Werte der Matrix - man nennt diese Komponenten oder Elemente - werden wiederum mit kleinen Buchstaben bezeichnet, die mit zwei Indizes markiert sind, der erste Index steht für die Zeile, der zweite für die Spalte. Im Beispiel ist also \(a_{3, 2} = 33\).
Man kann auch die gesamte Matrix wie folgt schreiben:
\[A = \begin{pmatrix} a_{1, 1} & a_{1, 2} \\ a_{2, 1} & a_{2, 2} \\ a_{3, 1} & a_{3, 1} \end{pmatrix} \]
Etwas kompakter geschrieben:
\[ A = (a_{i,j})_{i=1,2,3, j=1,2} \]
Ein Skalar kann mit einer Matrix multipliziert werden, indem der Skalar mit jeder Komponente multipliziert wird.
\[ 2 \, \begin{pmatrix} 1 & 2 \\3 & 4 \end{pmatrix} = \begin{pmatrix} 2 & 4 \\ 6 & 8 \end{pmatrix} \]
Auch hier ist - wie schon bei den Vektoren - Vorsicht geboten, dass man nicht von “Skalarprodukt” spricht. Das Skalarprodukt entspricht bei Matrizen der Matrixmultiplikation (1.1.3.1).
Wenn \(A\) eine \(n\times m\) Matrix ist, dann ist die transponierte Matrix \(A^T\) eine \(m\times n\) Matrix.
Die formale Definition für die Transposition einer Matrix \(A = (a_{i, j})\) ist:
\[ A^T = (a_{j, i}) \]
Das heißt, die Elemente der transponierten Matrix erhält man, indem man die “Koordinaten” der orginalen Einträge vertauscht. Zum Beispiel steht \(a_{1,3}\) in der transponierten Matrix an Stelle \(3, 1\).
In unserem Beispiel haben wir eine \(3\times 2\) Matrix:
\[A = \begin{pmatrix} 5 & 3 \\ 21 & -1 \\ 9 & 33 \end{pmatrix} \]
Somit ist die transponierte Matrix eine \(2\times 3\) Matrix:
\[A^T = \begin{pmatrix} 5 & 21 & 9 \\ 3 & -1 & 33 \end{pmatrix} \]
Am besten stellt man sich vor, dass \(A\) aus 2 Spaltenvektoren besteht:
\[ \left( \begin{array}{c} 5 \\ 21 \\ 9 \end{array} \right) \quad \left( \begin{array}{c} 3 \\ -1 \\ 33 \end{array} \right) \]
Jetzt transponiert man jeden Spaltenvektor zu einem Zeilenvektor
\[ ( 5, 21, 9) \\ ( 3, -1, 33 ) \]
und setzt diese dann wieder zu einer Matrix zusammen
\[\begin{pmatrix} 5 & 21 & 9 \\ 3 & -1 & 33 \end{pmatrix} \]
Wie schon bei den Vektoren resultiert eine doppelte Anwendung der Transposition in der ursprünglichen Matrix
\[ (A^T)^T = A \]
Empfehlenswert auf Wikipedia: Matrizenmultiplikation
Die Matrixmultiplikation ist enorm wichtig für die Berechnungen innerhalb von neuronalen Netzen. Man kann sie als “Erweiterung” des Skalarprodukts auf Matrizen auffassen.
Eine wichtige Voraussetzung: Zwei Matrizen \(A\) und \(B\) können nur dann multipliziert werden (in der Reihenfolge \(A\, B\)), wenn die Anzahl der Spalten von \(A\) gleich der Anzahl der Zeilen von \(B\) ist. Formal ausgedrückt: Eine \(n \times k\)-Matrix \(A\) kann mit \(p \times m\)-Matrix \(B\) multipliziert werden, wenn \(k = p\).
Die resultierende Matrix \(C\) hat die Form \(n \times m\).
\[ C = A \, B\]
Die Berechnung des Produkts \(C\) ist wie folgt definiert:
\[ c_{ij} = \sum_{k = 1}^p a_{ik} \, b_{kj} \]
Als Beispiel multiplizieren wir eine \(2\times 3\) Matrix mit einer \(3\times 2\) Matrix. Daraus resultiert eine \(2\times 2\) Matrix:
\[\begin{pmatrix} a_{1,1} & a_{1,2} & a_{1,3} \\ a_{2,1} & a_{2,2} & a_{2,3} \end{pmatrix} \begin{pmatrix} b_{1,1} & b_{1,2} \\ b_{2,1} & b_{2,2} \\ b_{3,1} & b_{3,2} \end{pmatrix} = \begin{pmatrix} a_{1,1} b_{1,1} + a_{1,2} b_{2,1} + a_{1,3} b_{3,1} &a_{1,1} b_{1,2} + a_{1,2} b_{2,2} + a_{1,3} b_{3,2} \\ a_{2,1} b_{1,1} + a_{2,2} b_{2,1} + a_{2,3} b_{3,1} &a_{2,1} b_{1,2} + a_{2,2} b_{2,2} + a_{2,3} b_{3,2} \end{pmatrix}\]
Die Multiplikation mit Beispielwerten:
\[\begin{pmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \end{pmatrix} \begin{pmatrix} 1 & 2 \\ 1 & 2 \\ 1 & 2 \end{pmatrix} = \begin{pmatrix} 6 & 12 \\ 15 & 30 \end{pmatrix}\]
Bevor Sie zwei Matrizen multiplizieren, tun Sie immer erst Folgendes
Ein Vektor kann als Spezialfall einer Matrix aufgefasst werden.
Ein Spaltenvektor \(v\) der Länge 3 entspricht einer \(3 \times 1\) Matrix:
\[ v = \left( \begin{array}{c} v_1 \\ v_2 \\ v_3 \end{array} \right) \]
Ein Zeilenvektor \(w\) der Länge 3 entspricht einer \(1\times 3\) Matrix:
\[ w = (w_1, w_2, w_3) \]
Entsprechend kann man eine \(3\times 2\) Matrix \(A\) mit einem Spaltenvektor \(x\) der Länge 2 (also einer \(2\times 1\) Matrix) multiplizieren und erhält also eine \(3\times 1\) Matrix. Das entspricht wiederum einem Spaltenvektor der Länge 3:
\[ A = \begin{pmatrix} 5 & 3 \\ 21 & -1 \\ 9 & 33 \end{pmatrix} \]
\[ x = \left( \begin{array}{c} 2 \\ 1 \end{array} \right) \]
\[ A\, x = \begin{pmatrix} 5 & 3 \\ 21 & -1 \\ 9 & 33 \end{pmatrix} \left( \begin{array}{c} 2 \\ 1 \end{array} \right) = \left( \begin{array}{c} 5\cdot 2 + 3\cdot 1 \\ 21\cdot 2 + (-1)\cdot 1 \\ 9\cdot 2 + 33\cdot 1 \end{array} \right) = \left( \begin{array}{c} 13 \\ 41 \\ 51 \end{array} \right)\]
In dem Fall oben haben wir den Spaltenvektor von rechts multipliziert. Wenn wir einen Vektor von links an \(A\) multiplizieren wollten, bräuchten wir einen Zeilenvektor der Länge 3 (entspricht einer \(1\times 3\) Matrix).
Es gilt folgende Regel für Multiplikation und Transposition:
\[ (A \, B)^T = B^T \, A^T \]
Diese Regel gilt natürlich auch für Vektor-Matrix-Multiplikation (\(A, B\) seien Matrizen, \(v, w\) Vektoren):
\[\begin{align*} (v \, A)^T &= A^T \, v^T\\[2mm] (B \, w)^T &= w^T \, B^T \end{align*}\]
In Python gibt es die wichtige Bibliothek Numeric Python, kurz NumPy. In der Bibliothek gibt es eine sehr flexible und praktische Form des Arrays, mit der man elegant und effizient Vektoren, Matrizen und ganz allgemein Daten verarbeiten kann. Wir lernen hier auch Tensoren als Verallgemeinerung von Vektoren und Matrizen kennen.
Im NumPy zu verwenden, müssen wir es importieren:
import numpy as npIn Python benutzen wir den NumPy-Array, um Vektoren abzubilden. Wir unterscheiden aber zwischen Zeilen- und Spaltenvektoren. Im Folgenden wird auch klar, warum der Begriff “Dimension” manchmal missverständlich ist.
Ein 1-dimensionaler NumPy-Array repräsentiert einen Zeilenvektor:
a = np.array([13, 25, 8])
aarray([13, 25, 8])Das Array ist vom Typ ndarray (für n-dimensional array):
type(a)numpy.ndarrayZum Vergleich: eine normale Python-Liste (die auch manchmal als Array bezeichnet wird) ist vom Typ list.
ls = [5, 6, 10]
type(ls)listMit der Eigenschaft shape kann man die Größe eine NumPy-Arrays entlang seiner Dimensionen erhalten. Wir haben hier einen 1-dimensionalen Array der Länge 3. Schauen wir, was shape uns zurückmeldet:
a.shape(3,)Wir sehen hier eine Zahl, also hat der Array eine Dimension. Die “3” sagt uns, dass es drei Einträge in der ersten Dimension gibt. Eine Dimension nennt man in NumPy auch Achse bzw. englisch axis. Die erste Dimension ist die Achse \(0\).
Warum steht oben “(3,)” steht und nicht “3” oder “(3)”?
Das liegt daran, dass eine Shape immer als n-Tupel, also als Liste von Zahlen ausgegeben wird. Eine “3” wird aber nicht als Tupel erkannt und eine “(3)” wird auch als einfache Zahl mit Klammern interpretiert. Deshalb “(3,)”, weil das hintere Komma zweifelsfrei anzeigt, dass es sich um ein 1-Tupel, also um eine Liste der Länge 1, handelt.
Ein Spaltenvektor wie
\[\left( \begin{array}{c} 13 \\ 25 \\ 8 \end{array} \right)\]
wird mit Hilfe eines 2-dimensionalen Arrays ausgedrückt:
a2 = np.array([[13], [25], [8]])
a2array([[13],
[25],
[ 8]])Hier ist die Shape schon interessanter:
a2.shape(3, 1)Die zwei Zahlen besagen, dass es sich um einen 2-dimensionalen Array handelt mit 3 Zeilen und 1 Spalte. Man kann auch sagen, dass dieser Array zwei Achsen der Länge 3 und 1 hat.
Bevor wir weitergehen, noch eine interessante Operation. Mit np.where können Sie einen Numpy-Array filtern nach dem folgenden Schema:
np.where(BEDINGUNG, WERT FÜR TRUE, WERT FÜR FALSE)Dazu muss man ein paar Beispiele sehen. Wir erzeugen einen einfachen Array:
w = np.arange(10)
warray([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])Wenn wir alle Werte, die kleiner als 5 sind, durch 0 ersetzen wollen (und alle anderen beim ursprünglichen Wert belassen wollen), können wir das so formulieren:
np.where(w >= 5, w, 0)array([0, 0, 0, 0, 0, 5, 6, 7, 8, 9])Der ursprüngliche Array bleibt unberührt:
warray([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])Wenn man nur eine Bedingung eingibt, werden Stellen, die nicht der Bedingung entsprechen, einfach entfernt:
np.where(w >= 5)(array([5, 6, 7, 8, 9]),)Auch so etwas ist möglich:
np.where(w >= 5, 10*w, -w)array([ 0, -1, -2, -3, -4, 50, 60, 70, 80, 90])Ein verwandtes Konzept für normale Python-Listen ist List Comprehension (siehe Abschnitt 1.3.2).
Bei NumPy-Arrays gibt es ein Feature namens Broadcasting, das es erlaubt, elementweise Operationen mit ganz einfacher und intuitiver Syntax anzuwenden.
Bei der Addition zweier NumPy-Arrays wollen wir jedes Element des einen Arrays mit dem korrespondierenden Element des zweiten Arrays addieren, so wie hier:
\[ \left( \begin{array}{c} 13 \\ 25 \\ 8 \end{array} \right) + \left( \begin{array}{c} 1 \\ -1 \\ 0 \end{array} \right) = \left( \begin{array}{c} 14 \\ 24 \\ 8 \end{array} \right) \]
Das wird ganz intutiv mit dem Plus-Operator erreicht, dann wird komponentenweise addiert:
b = np.array([1, -1, 0])
a + barray([14, 24, 8])Dabei ist es egal, ob es Zeilenvektoren oder Spaltenvektoren sind:
b2 = np.array([[1], [-1], [0]])
a2 + b2array([[14],
[24],
[ 8]])Das Skalarprodukt zweier Vektoren \(a\) und \(b\) ist wie folgt definiert:
\[ a \cdot b = a_1 b_1 + a_2 b_2 + a_3 b_3 \]
Mit der Summennotation:
\[ \sum_{i=1}^3 a_i b_i \]
Im Englischen nennt man das Skalarprodukt dot product, deshalb heißt die entsprechende Funktion in NumPy dot.
Sie können die Funktion so anwenden:
np.dot(a, b)-12Oder als Methode eines der Vektoren:
a.dot(b)-12In beiden Fällen werden die Vektoren selbst nicht verändert.
Eine dritte Möglichkeit ist der folgende Operator, der die Numpy-Funktion matmul realisiert:
a @ b-12Wir sehen diesen Operator bei der Matrixmultiplikation noch einmal.
Auch hier haben wir einen Fall von Broadcasting. Im Gegensatz zur Addition zweier Vektoren haben wir hier einerseits einen Array und andererseits ein Skalar. Beim Broadcasting wird das so interpretiert, dass das Skalar mit der angegebenen Operation (hier: Multiplikation) auf jedes Element des Arrays angewandt wird.
Daher können wir die Multiplikation mit einem Skalar ganz intuitv so ausdrücken:
2 * aarray([26, 50, 16])Geht auch mit dem Spaltenvektor:
2 * a2array([[26],
[50],
[16]])Transponieren funktioniert mit dem Operator T, allerdings nur, wenn der Zeilenvektor in dieser Form vorliegt:
a3 = np.array([[13, 25, 8]])
a3.Tarray([[13],
[25],
[ 8]])Transposition funktioniert aber sehr gut bei Spaltenvektoren:
a2.Tarray([[13, 25, 8]])In Python wird eine Matrix als verschachtelter NumPy-Array abbgebildet. Jede Zeile ist ein Array und die Matrix ist ein Array von Zeilen. Nehmen wir eine Beispielmatrix \(A\):
\[A = \begin{pmatrix} 5 & 3 \\ 21 & -1 \\ 9 & 33 \end{pmatrix} \]
Hier die Matrix als 2-dimensionaler NumPy-Array:
A = np.array([[5, 3], [21, -1], [9, 33]])
Aarray([[ 5, 3],
[21, -1],
[ 9, 33]])Es gibt in NumPy auch eine Datenstruktur np.mat, die eigens für Matrizen gemacht ist. Allerdings wird dies in der Praxis eher selten verwendet, daher empfehle ich, immer np.array zu verwenden.
Zwei Matrizen gleicher Dimension kann man komponentenweise addieren:
\[\begin{pmatrix} 1 & 2 \\3 & 4 \end{pmatrix} + \begin{pmatrix} 10 & 20 \\ 20 & 10 \end{pmatrix} = \begin{pmatrix} 11 & 22 \\23 & 14 \end{pmatrix}\]
In Python kann man dank Broadcasting das Pluszeichen verwenden:
A1 = np.array([[1, 2], [3, 4]])
A2 = np.array([[10, 20], [20, 10]])
A1 + A2array([[11, 22],
[23, 14]])Man kann eine Matrix einfach mit einem Skalar multiplizieren (wieder Broadcasting). Dies wird auf jede Komponente angewandt.
2 * A1array([[2, 4],
[6, 8]])Das Transponieren funktioniert wie bei Vektoren mit dem Operator T.
A.Tarray([[ 5, 21, 9],
[ 3, -1, 33]])Matrizenmultiplikation funktioniert mit dem Operator dot.
Warum wird auch hier dot (Skalarprodukt von Vektoren) angewandt? Der Grund ist, dass bei der Matrizenmultiplikation die Berechnung eines einzelnen Elements der Ergebnismatrix das Skalarprodukt einer Zeile mit einer Spalte ist.
M1 = np.array([[1, 2, 3], [4, 5, 6]])
M2 = np.array([[1, 2], [1, 2], [1, 2]])
np.dot(M1, M2)array([[ 6, 12],
[15, 30]])Man kann auch die Array-Methode des Arrays M1 verwenden:
M1.dot(M2)array([[ 6, 12],
[15, 30]])In NumPy gibt es die Funktion matmul für die Multiplikation von Matrizen:
np.matmul(M1, M2)array([[ 6, 12],
[15, 30]])Eine elegante “Abkürzung” für matmul ist der Operator @, den man wie ein Rechenzeichen verwenden kann und der auch für das Skalarprodukt von zwei Vektoren taugt (s. oben):
M1 @ M2array([[ 6, 12],
[15, 30]])Vektor-Matrix-Multiplikation ist einfach ein Spezialfall der Matrizenmultiplikation. Auch hier benutzen wir entweder die Numpy-Methode np.dot…
x = np.array([[2], [1]])
np.dot(A, x)array([[13],
[41],
[51]])…oder alternativ die Array-Methode dot von A…
A.dot(x)array([[13],
[41],
[51]])…oder den Operator für matmul:
A @ xarray([[13],
[41],
[51]])Tatsächlich ist Python sehr flexibel, was den Unterschied Zeilen- und Spaltenvektor angeht. Python (bzw. NumPy) deutet den Vektor so, wie es benötigt wird.
Sehen wir uns Beispiele an:
x2 = np.arange(2)
x3 = np.arange(3)
print(A)
print(x2)
print(x3)[[ 5 3]
[21 -1]
[ 9 33]]
[0 1]
[0 1 2]Matrix A hat die Form 3x2.
Wir können von rechts einen Vektor der Länge 2 multiplizieren. Python deutet ihn als 2x1-Matrix.
A @ x2array([ 3, -1, 33])Wir können von links einen Vektor der Länge 3 multiplizieren. Dieser wird offenbar als 1x3-Matrix interpretiert.
x3 @ Aarray([39, 65])Der Begriff Shape bezieht sich auf Arrays. Er gibt sowohl an, wie viele Dimensionen der Array hat als auch die Größe/Länge jeder Dimension. Die Dimensionen bezeichnet man auch als Achsen.
Sehen wir uns das an einem Beispiel an. Ein Graustufenbild besteht aus Pixeln mit jeweils einem Grauwert zwischen 0 (schwarz) und 255 (weiß). Ein einzelnes Graustufenbild kann als 2-dimensionale Struktur dargestellt werden. Wir nehmen hier ein Bild mit 3x3 Pixeln:
image1 = np.array([[255, 0, 255],
[0, 0, 0],
[255, 0, 255]])
image1array([[255, 0, 255],
[ 0, 0, 0],
[255, 0, 255]])Der Array hat also zwei Dimensionen und jede Dimension hat die “Länge” drei.
Wir können uns die shape anschauen:
image1.shape(3, 3)Eine Shape von (3, 3) besagt, dass der Array zwei Dimensionen (oder Achsen) hat, da die Shape zwei Werte beinhaltet. Es gibt 3 Elementen entlang der ersten Achse (Zeilen) und 3 Elementen entlang der zweiten Achse (Spalten).
Jetzt definieren wir ein zweites Bild:
image2 = np.array([[255, 255, 255],
[0, 0, 0],
[255, 255, 255]])
image2array([[255, 255, 255],
[ 0, 0, 0],
[255, 255, 255]])Wenn wir Modelle zur Bilderkennung trainieren, benötigen wir viele Bilder. Wir speichern jetzt beide Bilder in einem Array und schauen, wie die Struktur aussieht:
images = np.array([image1, image2])
imagesarray([[[255, 0, 255],
[ 0, 0, 0],
[255, 0, 255]],
[[255, 255, 255],
[ 0, 0, 0],
[255, 255, 255]]])Wie sieht die shape aus?
images.shape(2, 3, 3)Wir sehen, dass wir es hier mit einem 3-dimensionalen Array zu tun haben.
Jetzt möchten wir Farbbilder kodieren. Statt eines 2-dimensionalen Arrays benötigen wir jetzt einen 3-dimensionalen Array für ein einziges Bild:
col1 = np.array([[[50, 0, 255], [0, 0, 40], [25, 0, 0]],
[[255, 40, 255], [30, 0, 0], [55, 0, 25]],
[[20, 0, 255], [0, 100, 0], [255, 80, 55]]])
col1array([[[ 50, 0, 255],
[ 0, 0, 40],
[ 25, 0, 0]],
[[255, 40, 255],
[ 30, 0, 0],
[ 55, 0, 25]],
[[ 20, 0, 255],
[ 0, 100, 0],
[255, 80, 55]]])Und wieder definieren wir ein zweites Bild.
col2 = np.array([[[0, 100, 5], [0, 0, 0], [25, 0, 0]],
[[5, 40, 50], [30, 0, 0], [50, 10, 20]],
[[0, 80, 20], [0, 100, 0], [100, 80, 150]]])
col2array([[[ 0, 100, 5],
[ 0, 0, 0],
[ 25, 0, 0]],
[[ 5, 40, 50],
[ 30, 0, 0],
[ 50, 10, 20]],
[[ 0, 80, 20],
[ 0, 100, 0],
[100, 80, 150]]])Jetzt packen wir wieder beide Bilder in einen Array.
colimages = np.array([col1, col2])
colimagesarray([[[[ 50, 0, 255],
[ 0, 0, 40],
[ 25, 0, 0]],
[[255, 40, 255],
[ 30, 0, 0],
[ 55, 0, 25]],
[[ 20, 0, 255],
[ 0, 100, 0],
[255, 80, 55]]],
[[[ 0, 100, 5],
[ 0, 0, 0],
[ 25, 0, 0]],
[[ 5, 40, 50],
[ 30, 0, 0],
[ 50, 10, 20]],
[[ 0, 80, 20],
[ 0, 100, 0],
[100, 80, 150]]]])Und schauen uns an, was für eine Shape dieser Array hat.
colimages.shape(2, 3, 3, 3)Wie Sie sehen, haben wir es hier mit einer 4-dimensionalen Struktur zu tun.
Eine 4- (oder höher-) dimensionale Matrix nennt man auch Tensor. Genauer gesagt ist “Tensor” der Oberbegriff, d.h. ein 1-dimensionaler Array ist ebenfalls ein Tensor.
Siehe auch Wikipedia.
NumPy erlaubt es, Ihre Arrays sehr einfach umzuformen. Tatsächlich werden intern gar keine Daten verschoben, sondern lediglich die Formatinformation geändert. Intern werden NumPy-Arrays nämlich linearisiert abgelegt (also einfach in einer langen Reihe). Erst durch die Shape-Angabe wird daraus eine mehrdimensionale Struktur.
Sie haben einen einfachen Array mit 12 Zahlen. Diese Zahlen könnte man als 2-dimensionalen 2x6-Array oder 2-dimensionalen 3x4-Array oder 3-dimensionalen 2x3x2-Array darstellen. Tatsächlich speichert NumPy speichert die Zahlen intern immer als einfachen 1-dimensionalen Array und merkt sich zusätzlich die Shape, die man jederzeit ändern kann.
Nehmen Sie unser kleines 3x3-Bild:
image1array([[255, 0, 255],
[ 0, 0, 0],
[255, 0, 255]])Wir möchten dieses Array zu linearisieren, d.h. alle 9 Werte sollen in einem Array sein. Also rufen wir reshape auf mit der Dimension “(9)”, d.h. ein 1-dimensionales Array mit 9 Elementen:
image1.reshape(9)array([255, 0, 255, 0, 0, 0, 255, 0, 255])Der Aufruf gibt ein neues Array zurück und ist ansonsten nicht-destruktiv, d.h. unser alter Array ist noch da:
image1array([[255, 0, 255],
[ 0, 0, 0],
[255, 0, 255]])Schauen wir uns unseren 3-dimensionalen Array mit 2 Bildern an:
imagesarray([[[255, 0, 255],
[ 0, 0, 0],
[255, 0, 255]],
[[255, 255, 255],
[ 0, 0, 0],
[255, 255, 255]]])Die Shape besagt (2, 3, 3).
images.shape(2, 3, 3)Jetzt möchten wir die Pixel der zwei Bilder jeweils “flach” haben, d.h. wieder als Array mit 9 Elementen. Wir wenden jetzt wieder reshape an und könnten (2, 9) angeben. Wir können aber auch sagen, dass uns die Anzahl der Bilder (2) nicht interessiert und geben an dieser Stelle eine -1 an:
images.reshape(-1, 9)array([[255, 0, 255, 0, 0, 0, 255, 0, 255],
[255, 255, 255, 0, 0, 0, 255, 255, 255]])Sie sehen, es funktioniert.
Ableitungen sind der Schlüssel zum Lernen bei Neuronalen Netzen. Daher ist es wichtig, dass einem bewusst ist, was eine Ableitung bedeutet.
Eine gute Übersicht über Ableitungsregeln finden Sie bei mathe-online.at oder bei matheguru. Zum Thema “Analysis” haben Parr and Howard (2018) einen Artikel speziell für den Kontext Deep Learning geschrieben, der vielleicht hilfreich ist.
Eine Funktion \(f\) mit einer Variablen wird oft wie folgt dargestellt:
\[ f(x) = 3 x^2 + 5 \]
Die Ableitung \(f'\) der Funktion \(f\) an der Stelle \(x\) gibt an, welche Steigung \(f\) an dieser Stelle hat.
Die Ableitung lässt sich anhand der bekannten Regeln berechnen, in unserem Beispiel:
\[ f'(x) = 6 x \]
Die Schreibweise \(f'\) - gesprochen “f Strich” - wird Lagrange-Schreibweise genannt.
Lassen Sie uns kurz überlegen, was eine Ableitung ist und warum dieses Konzept so erstaunlich ist. Wenn Sie eine Wanderung oder Radtour planen, sehen Sie manchmal ein Höhenprofil Ihrer Route, so wie hier:

Jetzt ist es ja interessant, an einem bestimmten Punkt zu wissen, ob es bergauf oder bergab geht. Außerdem, insbesondere wenn es bergauf geht, wollen Sie vielleicht wissen, wie steil es bergauf geht. Um das herauszufinden, muss man in diesem Fall in einer Datenbank nachsehen, wie denn die Höhe an diesem Punkt ist, und wie die Höhe an den benachbarten Punkten ist. Das heißt also, man muss Daten, die man vorher gemessen hat, in einer großen Tabelle nachschlagen.
Jetzt stelle man sich vor, das gesamte Höhenprofil wäre das Ergebnis einer Funktion. Dann könnten wir die aufwändige Tabelle mit Höhendaten einfach ersetzen durch eine Funktion und das gesamte Profil berechnen. Ein einfaches Beispiel wäre:
\[ f(x) = x^5 - 5 x^3 + 8x \]
Diese Funktion sie so aus (im Bereich \([-2, 2.2]\)):
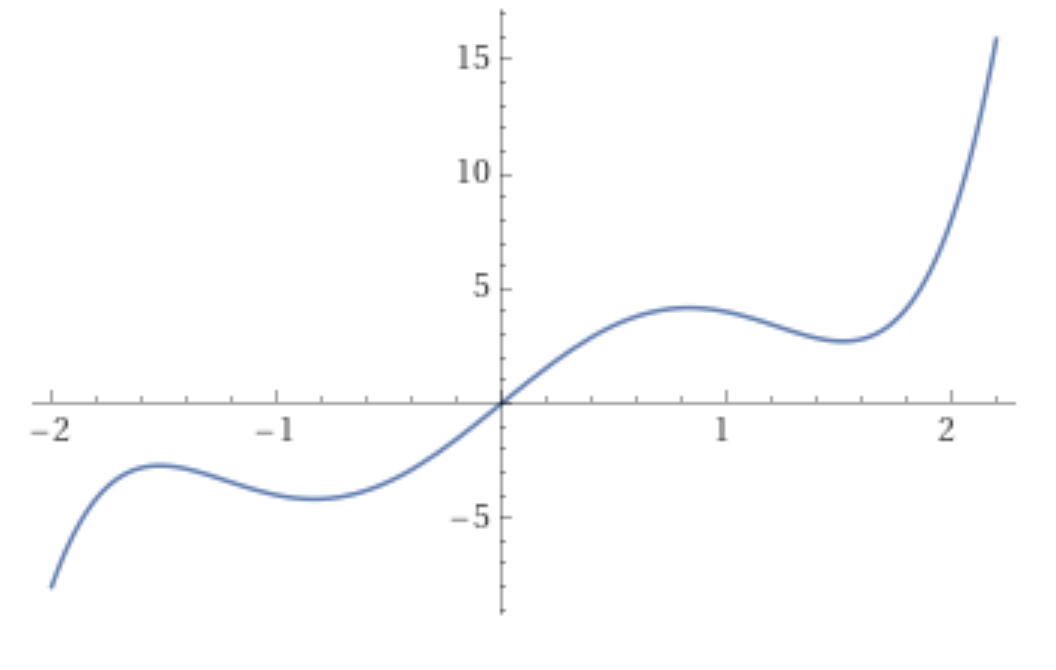
Jetzt können wir mit unserem Schulwissen die Ableitung bilden:
\[ f'(x) = 5x^4 - 15 x^2 + 8 \]
Und mit dieser Ableitung können wir die Steigung an jeder beliebigen Stelle einfach ausrechnen. An der Stelle \(x=0\) geht es relativ diagonal nach oben: \(f'(0) = 8\) (beachten Sie, dass die Achsen unterschiedliche Skalierung haben). An der Stelle \(x=0.8\) haben wir einen “Gipfel”, was man an der geringen Steigung von \(f'(0.8)= 0.448\) ablesen kann.
Eine andere Schreibweise für die Ableitung von \(f\) ist die Leibniz-Notation
\[ \frac{df(x)}{dx} \]
Alternativ:
\[ \frac{d}{dx} f(x) \]
Dies wird gesprochen: “d f von x nach dx”.
Ein Vorteil dieser Schreibweise ist, dass explizit ist, dass hinsichtlich der Variablen \(x\) abgeleitet wird (es kann noch weitere Variablen in der Formel geben). Das ist bei mehreren Variablen und auch bei Anwendung der Kettenregel wichtig (siehe unten).
Ein zweiter Vorteil ist, dass man \(\frac{d}{dx}\) als Operator auffassen und innerhalb des Ausdrucks verschieben kann.
Ein Rechenbeispiel:
\[ \begin{align*} f(x) & = x^5 - 5 x^3 + 8x \\[3mm] \frac{d}{dx} f & = \frac{d}{dx} \left( x^5 - 5 x^3 + 8x \right) \\[2mm] &= \frac{d}{dx} x^5 - \frac{d}{dx} 5 x^3 + \frac{d}{dx} 8x \\[2mm] &= 5x^4 - 15 x^2 + 8 \end{align*} \]
Für Interessierte erklärt der Online-Artikel Earliest Uses of Symbols of Calculus die Herkunft verschiedener Schreibweisen.
Wenn Sie Ableitungen nachschlagen wollen, können Sie die Webseite Wolframalpha verwenden. Für die Ableitung
\[ \frac{d}{dx} x^2 \]
Geben Sie ins Suchfeld ein (Leibniz-Schreibweise): d/dx (x^2)
Alternativ können Sie die Lagrange-Schreibweise verwenden: (x^2)’
Ein weiterer Ableitungsrechner ist https://www.derivative-calculator.net
Eine Funktion kann von mehreren Veränderlichen abhängen, dann spricht man von einer multivariaten Funktion, z.B.
\[ f(x, y) = 5x^2y \]
Funktion \(f\) kann man entweder nach \(x\) oder nach \(y\) ableiten. Hier ist es offensichtlich wichtig, die Leibniz-Schreibweise zu verwenden, die wir allerdings gleich noch leicht anpassen müssen:
\[ \frac{d}{dx} 5x^2y \]
\[ \frac{d}{dy} 5x^2y \]
Für partielle Ableitungen benutzt man nicht das normale “d”, sondern das Symbol \(\partial\), um eben anzuzeigen, dass es sich um eine partielle (und keine “normale”) Ableitung handelt. Man kann das Symbol “del” sprechen, meistens sagt man aber einfach “d”.
Um zu verdeutlichen, dass die jeweils “andere” Variable als ganz normale Konstante behandelt wird, verwenden wir den Operatormechanismus. Wir ziehen den Operator bis dahin, wo die Variable, nach der abgeleitet wird, steht, und holen alle anderen Werte nach vorn.
Für \(f\) gibt es zwei partielle Ableitungen…
…einmal \(f\) abgeleitet nach \(x\):
\[ \frac{\partial f}{\partial x} = \frac{\partial}{\partial x} 5x^2y = 5y \frac{\partial}{\partial x} x^2 = 5y2x = 10xy\]
…einmal \(f\) abgeleitet nach \(y\):
\[ \frac{\partial f}{\partial y} = \frac{\partial}{\partial y} 5x^2y = 5x^2 \frac{\partial}{\partial y} y = 5x^2 \]
Bei einer Funktion \(f\) mit zwei Veränderlichen könnten wir die zwei partiellen Ableitungen als 2-dimensionalen Vektor auffassen:
\[ \left( \begin{array}{c} \frac{\partial f}{\partial x} \\ \frac{\partial f}{\partial y} \end{array} \right) \]
Diesen Vektor nennt man auch den Gradienten von \(f\) und schreibt:
\[ \nabla f = \left( \begin{array}{c} \frac{\partial f}{\partial x} \\ \frac{\partial f}{\partial y} \end{array} \right) = \left( \begin{array}{c} 10xy \\ 5x^2 \end{array} \right)\]
Man kann sich den Gradienten als Vektor in einer mehrdimensionalen Landschaft vorstellen, der an einem spezifischen Punkt “bergauf” zeigt. Das ist ganz analog zum traditionellen Fall einer Ableitung, die ja die Steigung einer Kurve an einem bestimmten x-Punkt angibt. Will man sich “bergab” bewegen, muss man also den negierten Gradienten nehmen.
Das Symbol \(\nabla\) nennt man den Nabla-Operator.
In der obigen Formel kann man “Nabla f” oder “Gradient von f” sagen.
Die Kettenregel ist beim Lernen in Neuronalen Netzen von entscheidender Bedeutung. Für die Ausführungen nutzen wir praktisch immer die Leibniz-Schreibweise, da diese in unserem Kontext präziser und intuitiver ist.
Bei Ableitungen verschachtelter Funktionen \(f(g(x))\) gilt die Regel Äußere Ableitung multipliziert mit innerer Ableitung.
In der aus der Schule bekannten Lagrange-Schreibweise schreibt man:
\[ \left[ f(g(x)) \right]' = f'(g(x)) \cdot g'(x) \]
Wir schauen uns jetzt an, wie man mit der Leibniz-Schreibweise die Kettenregel behandelt. Betrachten wir folgendes Beispiel
\[ f(x) = sin(x^2) \]
Das \(x^2\) ist hier die innere Funktion, die wir in der Lagrange-Schreibweise \(g\) nennen würden. Wir ersetzen diese innere Funktion jetzt aber durch eine neue Variable \(u\):
\[ u := x^2 \]
Jetzt können wir die äußere Funktion \(f\) als Funktion auf \(u\) schreiben:
\[ f(u) = sin(u) \]
Wir wollen insgesamt die Funktion nach \(x\) ableiten.
Jetzt können wir in Leibniz-Schreibweise schreiben:
\[ \frac{df}{dx} = \frac{df}{du} \frac{du}{dx} \]
Das spiegelt die Kettenregel “Äußere Ableitung multipliziert mit innerer Ableitung” ganz natürlich wider. Gleichzeitig sieht man bei beiden Ableitungen, welche Funktion nach welcher Variablen abgeleitet wird: zunächst Funktion \(f\) nach Variable \(u\), dann Funktion \(u\) nach Variable \(x\).
Die innere Ableitung ist
\[ \frac{du}{dx} = \frac{d}{dx} x^2 = 2x \]
Die äußere Ableitung ist
\[ \frac{df}{du} = cos(u) \]
Also ist die Ableitung von \(f\) nach \(x\):
\[ \frac{df}{dx} = \frac{df}{du} \frac{du}{dx} = 2x\, cos(x^2) \]
Auch das können Sie bei wolframalpha.com nachschlagen: d/dx sin(x^2)
Falls Sie Python noch gar nicht kennen oder Ihr Wissen auffrischen müssen, empfehle ich The Python Tutorial. Wenn Sie bereits eine Programmiersprache wie Java oder C# kennen, sollte es kein Problem sein, sich Python anzueignen. Neben den Basics ist ein sicherer Umgang mit Python-Listen wichtig, insbesondere weil Listen in Python etwas anders funktionieren als Arrays oder Listen in Java. Hier ist für uns auch besonders das Slicing wichtig. Außerdem wichtig - und vielleicht etwas ungewöhnlich - sind die Techniken der List comprehension und der Dictionary comprehension. Beides wird hier kurz dargestellt (Abschnitte 1.3.2 und 1.3.3).
Ansonsten sind die Library NumPy und insbesondere die NumPy-Arrays sehr relevant für die Verarbeitung der Daten im Deep Learning, ebenso wie die Libary Pandas für die Verarbeitung von Daten in Tabellenform. Zu NumPy finden Sie in diesem Kapitel eine kurze Einführung in Abschnitt 1.1.4.
Wenn man viel in Python rechnet, ist es gut, wenn man schnell Zahlen formatiert ausgeben kann. Dazu gibt es die formatierte Ausgabe mit print. In Python 3 wird die Ausgabe mit f-string empfohlen - die ist kurz und elegant. Hier finden Sie eine gute Dokumentation als PDF von Jacqueline Masloff: A Guide to f-string Formatting in Python.
Früher war es üblich, eine an C++ angelehnte Notation zu nehmen (Stichwort “printf”):
x = 1.5
y = -3003.345098039530458
print("Ergebnisse: x=%.3f y=%.3f" % (x, y))Der nächste Schritt war die Verwendung der String-Methode format, die natürlich immer noch gültig ist:
print("Ergebnisse: x={:.3f} y={:.3f}".format(x, y))Eine Kurzversion der obigen Methoden ist der Python f-string. Hier kann man die Variablen direkt in den String hineinschreiben (beachten Sie das kleine f vor den Anführungszeichen):
print(f"Ergebnisse: x={x:.3f} y={y:.3f}")Als kurze Erläuterung: Der Kleinbuchstabe f steht hier für “float”. Es gibt noch die Buchstaben s (String), d (decimal number), n (number, äquivalent zu d) und e (Exponentialschreibweise). Innerhalb der geschweiften Klammern steht vor dem Doppelpunkt die Variable, die Sie einsetzen möchten (kann auch ein Ausdruck wie \(10*x\) oder eine Funktionsaufruf mit Rückgabewert sein). Hinter dem Doppelpunkt stehen (optional) die Formatierungsanweisungen.
Welche Methodik Sie wählen, ist egal, aber machen Sie sich mit einer Art der formatierten Ausgabe vertraut.
In Python verwendet man in der Regel Listen, um mehrere Daten in einer Variablen zu speichern. List comprehension ist ein Werkzeug, um Listen zu transformieren oder zu filtern. Die allgemeine Syntax ist
[AUSDRUCK SCHLEIFENKOPF BEDINGUNGEN]Dabei sind die BEDIGUNGEN optional. Der SCHLEIFENKOPF hat die Form
for LAUFVARIABLE in LISTEZusammengenommen kann man das so ausdrücken:
[AUSDRUCK for LAUFVARIABLE in LISTE BEDINGUNGEN]Beispiel (ohne Bedingungen):
[el*2 for el in ls]Hier nur zwei kleine Beispiele für List comprehension. Ich empfehle, im Internet noch weitere Beispiele und Erklärungen aufzusuchen.
Wir definieren eine Pythonliste:
ls = [5, 8, 10, 11, 20]Wir können jetzt jedes Element mit 2 multiplizieren und daraus eine neue Liste erhalten (die originale Liste wird dabei nicht verändert):
ls2 = [el*2 for el in ls]
ls2Mit einer Bedingung können wir die Liste filtern. Die Bedingung prüft mit Hilfe der Laufvariablen eine bestimmte Eigenschaft und nur, wenn diese wahr ist, wird das Element in die Ergebnisliste aufgenommen.
In dem folgenden Beispiel werden nur die geraden Elemente in die neue Liste aufgenommen. Wir binden die neue Liste hier nicht an eine eigene Variable, sondern sehen uns einfach die resultierende Liste direkt an:
[el for el in ls if el%2 == 0]Man kann List Comprehension auch nutzen, um schnell neue Listen herzustellen:
[x*10 for x in range(10)]Ganz ähnlich wie bei List Comprehensions können wir Dictionaries (auch bekannt als assoziative Listen oder Hashtabellen) manipulieren.
Hier die allgemeine Syntax, man beachte die geschweiften Klammern:
{AUSDRUCK SCHLEIFENKOPF BEDINGUNGEN}wobei
SCHLEIFENKOPF := for (KEY: VALUE) in DICT_ITEMSZur Demonstration definieren wir ein Dictionary:
d = {'harry': 123, 'sally': 456}
dWir probieren zunächst die Syntax aus, indem wir das identische Dictionary erzeugen.
d2 = {k: v for (k, v) in d.items()}
d2{'harry': 123, 'sally': 456}Jetzt manipulieren wir Schlüssel und Werte:
d3 = {k+' miller': v*10 for (k, v) in d.items()}
d3{'harry miller': 1230, 'sally miller': 4560}Auch hier können wir Bedingungen zum Filtern einsetzen:
d4 = {k+' miller': v*10 for (k, v) in d.items() if v > 200}
d4{'sally miller': 4560}Da es verschiedene Interpretationen von OOP gibt, hier ein paar Konzepte, die ich für wichtig halte.
Hier definieren wir eine Klasse MultMachine mit einem Konstruktor, der immer __init__ heißt. Die zwei Unterscores vor und nach dem Methodennamen zeigen, dass es sich um besondere Methoden handelt. Bei __repr__ handelt es sich um eine Methode, die die Ausgabe des Objekt nach Maßgabe der Programmiererin steuert.
Attribute der Klasse (aka Instanzvariablen) werden wie in __init__ gezeigt behandelt, indem man sie dort initialisiert. Man beachte, dass bei allen Methoden ein Pointer self auf das Objekt mitgeführt wird.
In Python gibt es keine Zugriffmodifikatoren wie “private” oder “protected”. Es gibt aber die Konvention, dass Instanzvariablen und Methoden, die nur innerhalb der Klasse verwendet werden, mit einem führenden Underscore gekennzeichnet werden. Daher _name statt name, denn diese Variable soll nicht “von außen” manipuliert werden (außer beim Initialisieren).
class MultMachine:
# Konstruktor
def __init__(self, factor, name = "machine"):
self.factor = factor
self._name = name # "private" Instanzvariable
# Ausgabe
def __repr__(self):
return f'<Machine "{self._name}" factor={self.factor}>'
# Funktionaler Aufruf
def __call__(self, n):
return n * self.factorWir erzeugen zwei Objekte (aka Instanzen) von MultMachine.
m1 = MultMachine(25)
m2 = MultMachine(42, "Dotty")m1<Machine "machine" factor=25>m2<Machine "Dotty" factor=42>Die Methode __call__ erlaubt es, ein Objekt als Funktion zu verstehen.
Bei Neuronalen Netzen wird dieser Mechanismus benutzt, um Neuronen, Schichten und Netze elegant als Funktionen zu definieren (sowohl in TensorFlow als auch in PyTorch).
Hier das Beispiel unserer zwei Objekte:
m1(100)2500m2(10)420