import tensorflow
import math
from math import exp
import matplotlib.pyplot as plt
import numpy as np
import time5 Einführung in Keras
Im praktischen Teil werden wir hauptsächlich mit Keras - innerhalb von TensorFlow - arbeiten. Wir lernen, wie man Feedforward-Netze in Keras erstellt, trainiert und evaluiert. Wir starten mit den Iris-Daten und einem sehr einfachen Netz. Dann lernen wir die MNIST-Daten zur Erkennung von handgeschriebenen Ziffern kennen und erstellen und trainieren ein FFN mit mehreren Schichten.
Lernziele, um Ihren Lernfortschritt zu prüfen
Nach Abschluss des Kapitels können Sie
- die Begriffe und Unterschiede von TensorFlow, Keras und PyTorch erklären
- Feedforwardnetze in Python mit Hilfe der Keras-Bibliothek erstellen, mit Daten aus Keras trainieren und den Trainingsverlauf visualisieren
- den MNIST-Datensatz beschreiben und das Training in Keras verwenden
- verschiedene Hyperparameter (Lernrate, Batchgröße etc.) benennen und ihre Bedeutung in konkreten Trainingssituationen beurteilen
Datensatz
| Name | Daten | Anz. Klassen | Klassen | Trainings-/Testdaten | Ort |
|---|---|---|---|---|---|
| Iris | Blütenblatt-Maße | 3 | Blumenklassen | 150 | |
| MNIST | s/w-Bilder (28x28) | 10 | handgeschriebene Ziffern 0…9 | 60000/10000 | 5.4 |
Importe
5.1 Hintergrund
5.1.1 TensorFlow
TensorFlow ist eine Open-Source-Bibliothek für Python (mit Bestandteilen in C++) für den Themenbereich des Maschinellen Lernens, inklusive Neuronaler Netze. TensorFlow wurde ursprünglich vom Google Brain Team für Google-eigenen Projekte entwickelt, wurde aber 2015 unter einer Open-Source-Lizenz (Apache License 2.0) für die Allgemeinheit frei gegeben. Mittlerweile dürfte TensorFlow das mit Abstand das wichtigste Framework im Bereich Maschinelles Lernen sein.
Noch ein paar Worte zum Entwicklungsteam hinter TensorFlow: Google Brain begann 2011 als ein sogenanntes “Google X”-Projekt als Kooperation zwischen Google-Fellow Jeff Dean und Stanford-Professor Andrew Ng. Seit 2013 ist Deep-Learning-Pioneer Geoffrey Hinton als leitender Wissenschaftler im Team. Weitere bekannte Wissenschaftler bei Google Brain sind Alex Krizhevsky und Ilya Sutskever (Autoren von AlexNet), Christopher Olah (bekannt durch seinen Blog) und Chris Lattner (Erfinder von Apple’s Programmiersprache Swift).
5.1.2 Keras
Keras ist ebenfalls eine Open-Source-Bibliothek für Python von François Chollet, die erstmals 2015 als Python-API für verschiedene “Backends” (u.a. TensorFlow) veröffentlicht wurde. Es ist ein objektorientiertes Framework für das Erstellen, Trainieren und Evaluieren Neuronaler Netze. Das Buch Deep Learning with Python (Chollet 2021) ist vom Erfinder von Keras und daher von besonderer Relevanz (einschränkend muss man sagen, dass die Theorie in dem Buch ein wenig zu kurz kommt). Eine Idee von Keras ist, dass es auch als Interface für verschiedene Backends in anderen Kontexten (z.B. Robotik oder mobile) genutzt werden kann. Daher liegt ein Fokus von Keras auf einer intuitiven, modularen und erweiterbaren Systematik.
Keras wurde unabhängig von TensorFlow entwickelt, wurde dann aber 2017 in TensorFlow 1.4 als Teil der TensorFlow Core API aufgenommen, d.h. alle Konzepte und Daten von Keras stehen in TensorFlow zur Verfügung. François Chollet arbeitet seit 2015 für Google und hat dort auch die Einbindung in TensorFlow unterstützt.
5.1.3 PyTorch
PyTorch ist - wie TensorFlow - eine Open-Source-Bibliothek für Maschinelles Lernen in Python. PyTorch wurde ursprünglich von der KI-Gruppe bei Facebook, genannt FAIR - Facebook AI Research (oder oft nur “Facebook AI”) - entwickelt. PyTorch ist in letzter Zeit immer populärer geworden, weil es an manchen Stellen einen direkteren Eingriff in die Abläufe zulässt. In diesem Buch wird hauptsächlich Keras verwendet, aber PyTorch wird in den Anhängen E und F zumindest angerissen.
5.2 Einfaches Neuronales Netz
Wir beginnen mit dem einfachsten möglichen Neuronales Netz und lernen, wie wir es erzeugen und trainieren (wir verzichten auf Testdaten).
In Keras heißt die Basisklasse für Neuronale Netze Sequential. Der Name weist darauf hin, dass ein Sequential-Objekt eine geordnete Reihe (Sequenz) von Schichten enthält.
Wir erstellen zunächst ein Neuronales Netz mit einer Schicht. Also stellen wir eine Instanz von Sequential her, dies wäre unser Modell.
from tensorflow.keras.models import Sequential
model = Sequential()5.2.1 Schichten Input und Dense
Jetzt kann man Schichten als Objekte dem Modell hinzufügen. Es gibt verschiedene Arten von Schichten.
Als erstes fügen wir die Neuronen für die Eingabe als Objekt der Klasse Input hinzu. Diese “Schicht” hat keine Parameter, die zu lernen sind, und wird daher nicht als Schicht gezählt.
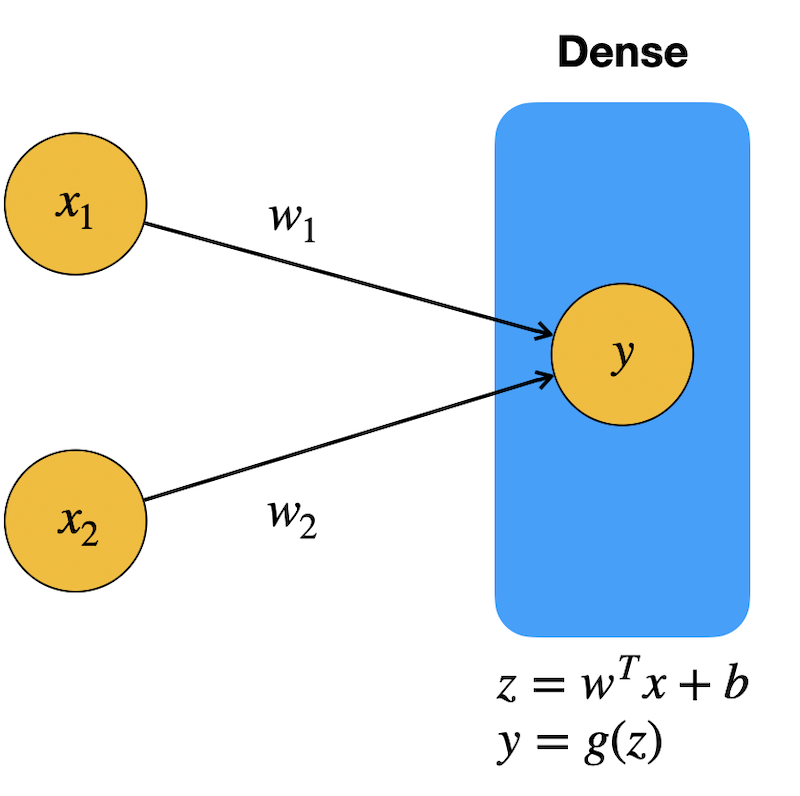
Unsere erste “richtige” Schicht ist ein Objekt vom Typ Dense. Diese Schicht verbindet sich mit allen Neuronen der Vorgängerschicht. In anderen Kontexten nennt man solche Schichten auch fully connected layer oder FC layer. Unsere Dense-Schicht ist gleichzeitig auch die Ausgabeschicht und hat daher nur ein Neuron (der erste Parameter).
Mit activation kann man die Aktivierungsfunktion spezifizieren. Wir wählen die Funktion sigmoid, also die logistische Funktion:
\[ g(z) = \frac{1}{1-e^{-z}} \]
Dies ist die typische Aktivierung für das Ausgabeneuron bei binärer Klassifikation.
from tensorflow.keras import Input
from tensorflow.keras.layers import Dense
model = Sequential()
model.add(Input(shape=(2,))) # Zwei Eingabeneuronen
model.add(Dense(1, # Ein (Ausgabe-)Neuron in dieser Schicht
activation='sigmoid')) # Aktivierungsfunktion am AusgabeneuronUnser Netz sieht derzeit so aus (das Bias-Neuron ist nicht grafisch repräsentiert):
Mit der Methode summary geben wir uns eine Zusammenfassung unserer Netzwerk-Architektur aus, was später bei komplexeren Netzen hilfreich ist.
model.summary()Model: "sequential_1"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ dense (Dense) │ (None, 1) │ 3 │ └─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 3 (12.00 B)
Trainable params: 3 (12.00 B)
Non-trainable params: 0 (0.00 B)
Wir haben drei Parameter: \(w_1\), \(w_2\) und \(b\).
5.2.2 Parameter
Man kann das Netzwerkobjekt auch programmatisch untersuchen. Die Eigenschaft layers enthält alle Schichtenobjekte in iterierbarer Form. Hier wenden wir die Methode get_config auf jede Schicht an, die uns ein Dictionary zurückgibt, das wir hier ausgeben.
for l in model.layers:
for key in l.get_config():
print(f'{key}: {l.get_config()[key]}')name: dense
trainable: True
dtype: {'module': 'keras', 'class_name': 'DTypePolicy', 'config': {'name': 'float32'}, 'registered_name': None}
units: 1
activation: sigmoid
use_bias: True
kernel_initializer: {'module': 'keras.initializers', 'class_name': 'GlorotUniform', 'config': {'seed': None}, 'registered_name': None}
bias_initializer: {'module': 'keras.initializers', 'class_name': 'Zeros', 'config': {}, 'registered_name': None}
kernel_regularizer: None
bias_regularizer: None
kernel_constraint: None
bias_constraint: NoneBesonders interessant sind natürlich die Gewichte, zumindest bei kleineren Netzen (später werden die Gewichte nicht mehr handhabbar).
Mit der Methode get_weights kann man sich die Gewichte und Bias-Gewichte aller Schichten ausgeben lassen.
w, b = model.get_weights()
print(f'WEIGHTS {w[0]} {w[1]} BIAS {b}')WEIGHTS [0.83977664] [0.9147173] BIAS [0.]Man sieht, dass die Gewichte auf Zufallswerte in einer bestimmten Wertespanne gesetzt werden. Unter Layer weight initializers finden Sie Infos zu den unterschiedlichen Methoden zur zufälligen Initialisierung der Gewichte.
5.2.3 Iris-Datensatz
Wenn Sie nicht genau wissen, was ein “Tensor” ist oder wie man mit Vektoren, Matrizen und Tensoren in Python/NumPy umgeht, sehen Sie sich Abschnitt 1.1.4 an.
Wir möchten jetzt noch das Experiment mit den Iris-Daten aus Kapitel 3 mit einem Keras-Netz wiederholen. Wir bereiten die Daten wieder für eine binäre Klassifikation vor, dass wir nur zwei Features haben und nur zwei Klassen; wie im Abschnitt 3.4.1.
Wir arbeiten hier nur mit Trainingsdaten und verzichten auf eine Trennung ist Test- und Trainingsdaten.
from sklearn import datasets
iris = datasets.load_iris()Wir reduzieren die Features auf zwei Features.
Wir zeigen hier einen alternativen Weg, die Spalten 0 und 2 auszuwählen (und die anderen zu ignorieren). Der Doppelpunkt bei
iris.data[:, [0, 2]]bedeutet, dass alle Zeilen ausgewählt werden.
x_iris = iris.data[:, [0, 2]]
x_iris[:5] # Testausgabearray([[5.1, 1.4],
[4.9, 1.4],
[4.7, 1.3],
[4.6, 1.5],
[5. , 1.4]])Wir reduzieren die Daten auf zwei Klassen, indem wir nur die vorderen 100 von den 150 Beispielen nehmen:
x_iris = x_iris[:100] # nur die ersten 100 Elemente (also zwei Klassen)
y_iris = iris.target[:100]
y_irisarray([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1])Jetzt schauen wir uns die Daten nochmal an:
plt.scatter(x_iris[:50, 0], x_iris[:50, 1], color='red', marker='o', label='setosa')
plt.scatter(x_iris[50:, 0], x_iris[50:, 1], color='blue', marker='x', label='versicolor')
plt.xlabel('sepal length')
plt.ylabel('petal length')
plt.legend(loc='upper left')
plt.show()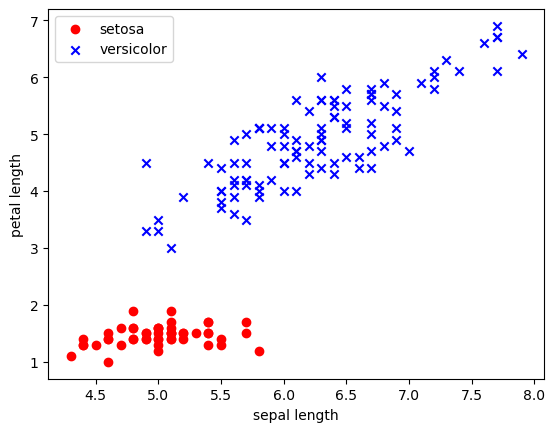
5.2.4 Training
Wir trainieren das Netzwerk mit Backpropagation in 10 Epochen. Wir haben keine Testdaten, sondern lediglich einen Trainingsdatensatz mit 100 Beispielen. Damit man ein Keras-Netzwerk trainieren kann, muss es zunächst mit der Methode compile konfiguriert werden.
Konfiguration mit Compile
Mit compile legen wir Hyperparameter wie die Lernrate und die Optimierungsmethode fest, aber auch Metriken wie die Art der Zielfunktion und die Evaluationsmaße.
Wir verwenden hier stochastic gradient descent (SGD) als Optimierungsmethode, mit einer Lernrate von 0.1. Als Zielfunktion wählen wir MSE (gemittelte Fehlerquadrate) und als Evaluationsmaß Accuracy (dazu mehr im nächsten Kapitel, Abschnitt 6.2.9).
from tensorflow.keras.optimizers import SGD
sgd = SGD(learning_rate=0.1)
model.compile(optimizer=sgd,
loss='binary_crossentropy',
metrics=['acc'])
# Alternative:
# Hier benötigt man das Objekt in sgd nicht, kann allerdings auch
# nicht die Lernrate einstellen
#
# model_and.compile(optimizer='sgd', loss='binary_crossentropy', metrics=['acc'])
Hinweis
Wie wir später noch sehen, muss man nicht unbedingt ein Objekt für den Optimizer herstellen, sondern kann auch einfach in der Methode compile optimizer=‘sgd’ angeben. Das Vorgehen hier benötigt man nur, wenn man den Optimizer konfigurieren will (wie hier mit der Lernrate).
Training mit Lernrate 0.1
Das eigentliche Training, also die Updates der Paramter mit Hilfe der Trainingsdaten, findet in der Methode fit statt. Hier geben wir die Featurevektoren an, die Zielwerte und die Anzahl der Epochen, also die Trainingsdauer.
history = model.fit(x_iris,
y_iris,
epochs=10)Epoch 1/10
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - acc: 0.4906 - loss: 2.3029
Epoch 2/10
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step - acc: 0.7497 - loss: 0.4519
Epoch 3/10
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step - acc: 0.9845 - loss: 0.3698
Epoch 4/10
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step - acc: 0.9845 - loss: 0.3572
Epoch 5/10
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step - acc: 1.0000 - loss: 0.3031
Epoch 6/10
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step - acc: 1.0000 - loss: 0.2828
Epoch 7/10
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - acc: 1.0000 - loss: 0.2526
Epoch 8/10
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - acc: 1.0000 - loss: 0.2409
Epoch 9/10
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - acc: 1.0000 - loss: 0.2187
Epoch 10/10
4/4 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - acc: 1.0000 - loss: 0.2202Ergebnis
Wir sehen uns die Entwicklung von Loss und Accuracy an.
Dazu definieren wir eine Hilfsfunktion:
def plot_loss_acc(history):
epochs = range(len(history.history['acc']))
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(10,4))
ax[0].plot(epochs, history.history['loss'], 'r', label='Loss')
ax[0].set_xlabel('Epochen')
ax[0].set_ylabel('Loss')
ax[0].set_title('Loss')
ax[1].plot(epochs, history.history['acc'], 'b', label='Accuracy')
ax[1].set_xlabel('Epochen')
ax[1].set_ylabel('Accuracy')
ax[1].set_title('Accuracy')
plt.show()plot_loss_acc(history)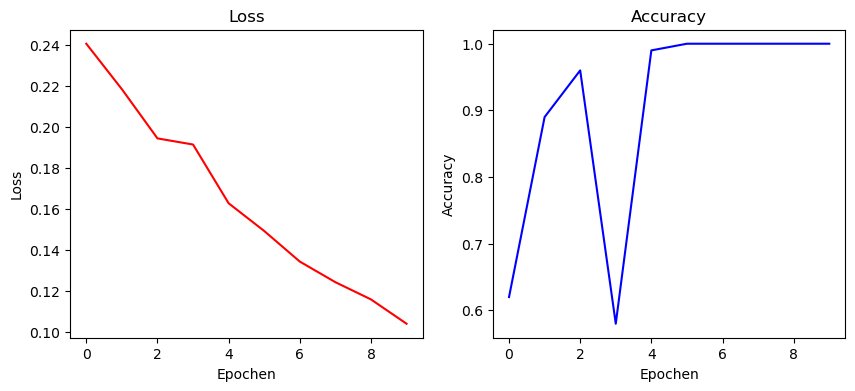
Man sieht hier, dass das Netz mit Lernrate 0.1 bereits nach 5 Epochen 100% Accuracy erreicht.
Wir können uns noch die Gewichte ausgeben:
w, b = model.get_weights()
print(f'WEIGHTS {w[0]} {w[1]} BIAS {b}')WEIGHTS [-0.6417845] [1.3464999] BIAS [-0.35998327]5.2.5 Vorhersage
Man kann mit predict auch Vorhersagen mit dem trainierten Netz berechnen. Hier für 10 Werte aus der ersten Hälfte der 100 Datenpunkte (Klasse 0):
pred = model.predict(x_iris[:10])
pred1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 15ms/steparray([[0.1483016 ],
[0.16525623],
[0.16438995],
[0.21543977],
[0.15659218],
[0.1770345 ],
[0.19355221],
[0.17520823],
[0.21437797],
[0.18467678]], dtype=float32)Da wir kontinuierliche Werte bekommen, legen wir eine Schwellwertfunktion an, um die Ausgabe auf die Werte {0, 1} zu zwingen.
[(1 if x>=0.5 else 0) for x in pred][0, 0, 0, 0, 0, 0, 0, 0, 0, 0]Hier für Werte aus der “Mitte” der Daten (40 bis 59), wo die eine Hälfte noch zu Klasse 0 gehört, die andere zu Klasse 1.
pred = model.predict(x_iris[40:60])
[(1 if x>=0.5 else 0) for x in pred]1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 14ms/step[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]5.3 Feedforward-Netze
Unser erstes Netz hatte lediglich eine parametrisierte Schicht und ein Ausgabeneuron.
Jetzt sehen wir uns an, wie man FNN mit Zwischenschichten erstellt, das für die Klassifikation von 10 Klassen geeignet ist.
5.3.1 Verlustfunktion in Keras
Bevor man ein Modell in Keras mit fit trainiert, legt man mit compile die Verlustfunktion fest (siehe dazu auch Abschnitt 4.2.1), z.B. so:
model.compile(loss='categorical_crossenropy', optimizer='sgd')Die Loss-Funktion ist in der Regel eine von diesen (die Begiffe sind mit der Keras-Dokumentation verlinkt):
Hier nochmal eine kurze Erklärung, wann Sie welche nehmen:
Sie verwenden binary_crossentropy für binäre Klassifikation, wo Ihre Labels als Liste mit Nullen und Einsen vorliegen.
Auf categorical_crossentropy greifen Sie bei der Klassifikation mit multiplen Klassen zurück (Beispiel MNIST mit Klassen 0 bis 9). Hier müssen die Labels in One-Hot-Encoding vorliegen.
Die sparse_categorical_crossentropy verwenden Sie ebenfalls bei der Klassifikation mit multiplen Klassen, aber hier liegen die Labels als Integer-Werte vor, also z.B. [1, 5, 3, 0] etc.
Bislang haben wir die Labels immer in One-Hot-Encoding umgewandelt und dann categorical_crossentropy benutzt.
5.4 MNIST-Datensatz
MNIST kurz gefasst
Im MNIST-Datensatz geht es Erkennung von handgeschriebenen Ziffern von 0 bis 9. Es gibt zehn Klassen, die es vorherzusagen gilt: 0, 1, 2, … 9. Die Bilder haben die Auflösung 28x28 und liegen in Graustufen vor. Der Datensatz enthält 60000 Trainingsbeispiele und 10000 Testbeispiele.
Wir ziehen den Datensatz MNIST hinzu. MNIST steht für Modified National Institute of Standards and Technology (dataset). Siehe auch den Wikipedia-Artikel zu MNIST und die Keras-Doku zu MNIST.
Eine Einführung in die MNIST-Daten in Keras finden Sie im folgenden Video.
5.4.1 Daten einlesen
Die Daten kommen bereits separiert in Trainings- und Testdaten.
from tensorflow.keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()Wir sehen uns die Struktur an. Die Bilder sind als 28x28-Matrizen hinterlegt.
print('x_train: ', x_train.shape)
print('y_train: ', y_train.shape)
print('x_test: ', x_test.shape)
print('y_test: ', y_test.shape)x_train: (60000, 28, 28)
y_train: (60000,)
x_test: (10000, 28, 28)
y_test: (10000,)5.4.2 Daten visualisieren
Die Funktion imshow (image show) erlaubt uns das schnelle Betrachten der Bilder. Wir wählen als color map (cmap) Graustufen.
Erstes Trainingsbild:
plt.imshow(x_train[0], cmap='gray')<matplotlib.image.AxesImage at 0x16ebce090>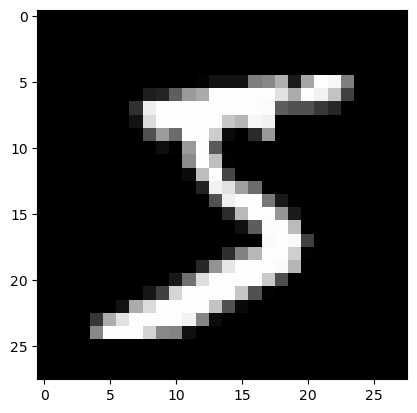
Zehntes Trainingsbild:
plt.imshow(x_train[9], cmap='gray')<matplotlib.image.AxesImage at 0x177c48790>
Hier geben wir von jeder Kategorie das erste Trainingsbeispiel aus:
fig, ax = plt.subplots(nrows=2, ncols=5, sharex=True, sharey=True,)
ax = ax.flatten()
for i in range(10):
img = x_train[y_train == i][0]
ax[i].imshow(img, cmap='gray')
ax[0].set_xticks([]) # keine Achsenmarkierungen
ax[0].set_yticks([])
plt.tight_layout()
plt.show()
5.4.3 Daten vorverarbeiten
Für unsere Zwecke möchten wir die Bildmatrizen linearisieren zu Vektoren der Länge 784 (= 28*28). Dazu verwenden wir reshape.
Außerdem möchten wir die Pixelwerte (0..255) auf das Interval [0, 1] normalisieren. Das erreichen wir, indem wir alle Werte durch 255.0 teilen.
x_train = x_train.reshape(60000, 784)/255.0
x_test = x_test.reshape(10000, 784)/255.0Kleiner Check, ob die Linearisierung geklappt hat:
print('x_train: ', x_train.shape)
print('x_test: ', x_test.shape)x_train: (60000, 784)
x_test: (10000, 784)5.4.4 One-Hot Encoding
Um die zehn Ziffern 0, , 9 in der Ausgabe zu kodieren, benutzen wir One-Hot Encoding, d.h. jede Ziffer wird durch einen Vektor der Länge 10 repräsentiert:
\[ \left( \begin{array}{c} 1 \\0 \\ \vdots \\ 0\end{array} \right) \quad \left( \begin{array}{c} 0 \\1 \\ \vdots \\ 0\end{array} \right) \quad \ldots\quad \left( \begin{array}{c} 0 \\0 \\ \vdots \\ 1\end{array} \right) \]
In Keras gibt es dafür die Funktion to_categorical. Wir schreiben das Ergebnis in neue Variablen.
from tensorflow.keras.utils import to_categorical
y_train_1hot = to_categorical(y_train, 10)
y_test_1hot = to_categorical(y_test, 10)Wir prüfen, ob die Label-Daten die richtige Form haben.
print("y_train: ", y_train_1hot.shape)
print("y_test: ", y_test_1hot.shape)y_train: (60000, 10)
y_test: (10000, 10)Das passt: Es sind Vektoren der Länge 10.
5.5 Netz mit zwei Schichten
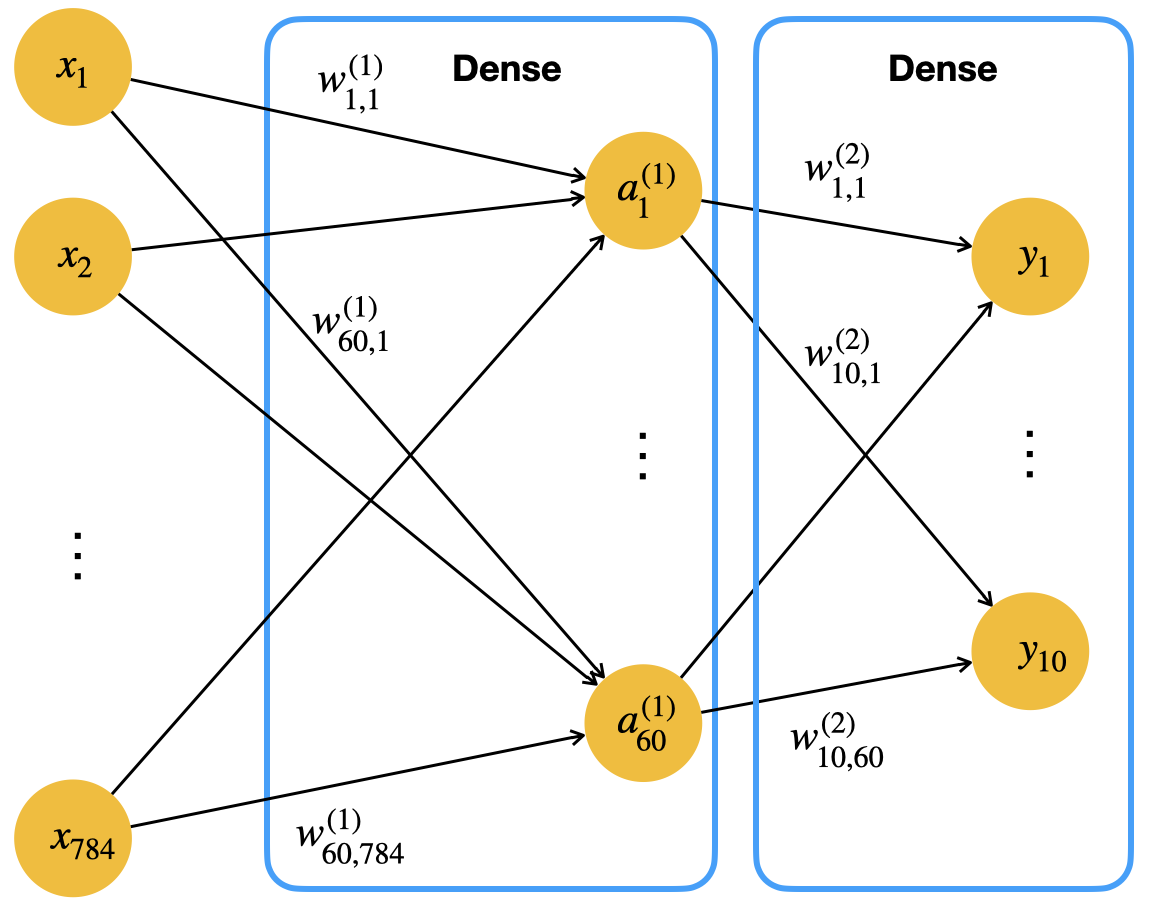
Wir bauen jetzt ein Neuronales Netz mit einer “versteckten” Schicht (hidden layer) mit 60 Neuronen.
Das Netz benötigt für die MNIST-Daten eine Eingabeschicht mit 784 Neuronen und hat zwei parametrisierte Schichten:
- Versteckte Schicht mit 60 Neuronen
- Ausgabeschicht mit 10 Neuronen
Schematisch sieht das so aus (ohne Bias-Neuronen):
5.5.1 Modell
In Keras erstellen wir das Netz als Instanz der Klasse Sequential.
Neben der Eingabe fügen dem Objekt zwei parametrisierte Schichten vom Typ Dense (fully connected) hinzu. Wir wählen die Sigmoid-Funktion für die Aktivierung der versteckten Schicht. Bei der Ausgabeschicht geben wir an, dass wir die Softmax-Funktion anwenden möchten. Denken Sie daran, dass Sie bei Klassifikation mit drei und mehr Klassen immer Softmax an der Ausgabe verwenden müssen.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Input, Dense
model = Sequential()
model.add(Input(shape=(784,)))
model.add(Dense(60,
activation='sigmoid'))
model.add(Dense(10,
activation='softmax'))5.5.2 Anzahl der Parameter
Wie viele Parameter hat das Netz? Die Gewichtsmatrix \(W^{(1)}\) von Input- zu versteckter Schicht hat 784x60 Einträge:
784*6047040Es kommen 60 Gewichte für das Bias-Neuron dazu. Insgesamt also 47100 Parameter. Die Gewichtsmatrix \(W^{(2)}\) von versteckter zu Ausgabeschicht enthält 10x60 = 600 Einträge plus den 10 Gewichten für das Bias-Neuron zur Ausgabe, macht 610 Parameter. Alles in allem also 47710 Parameter.
Wir schauen uns das Netz in der Kurzübersicht mit Hilfe der Methode summary an. Dort steht auch nochmal die Anzahl der Parameter:
model.summary()Model: "sequential_2"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ dense_1 (Dense) │ (None, 60) │ 47,100 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_2 (Dense) │ (None, 10) │ 610 │ └─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 47,710 (186.37 KB)
Trainable params: 47,710 (186.37 KB)
Non-trainable params: 0 (0.00 B)
Einen etwas technischeren Blick auf Ihr Modell mit allen Schichten erhalten Sie mit get_config. Hier sehen Sie zum Beispiel verschiedene Einstellungen in den Schichten, z.B. zur Initialisierung der Gewichte.
model.get_config(){'name': 'sequential_2',
'trainable': True,
'dtype': {'module': 'keras',
'class_name': 'DTypePolicy',
'config': {'name': 'float32'},
'registered_name': None},
'layers': [{'module': 'keras.layers',
'class_name': 'InputLayer',
'config': {'batch_shape': (None, 784),
'dtype': 'float32',
'sparse': False,
'ragged': False,
'name': 'input_layer_1'},
'registered_name': None},
{'module': 'keras.layers',
'class_name': 'Dense',
'config': {'name': 'dense_1',
'trainable': True,
'dtype': {'module': 'keras',
'class_name': 'DTypePolicy',
'config': {'name': 'float32'},
'registered_name': None},
'units': 60,
'activation': 'sigmoid',
'use_bias': True,
'kernel_initializer': {'module': 'keras.initializers',
'class_name': 'GlorotUniform',
'config': {'seed': None},
'registered_name': None},
'bias_initializer': {'module': 'keras.initializers',
'class_name': 'Zeros',
'config': {},
'registered_name': None},
'kernel_regularizer': None,
'bias_regularizer': None,
'kernel_constraint': None,
'bias_constraint': None},
'registered_name': None,
'build_config': {'input_shape': (None, 784)}},
{'module': 'keras.layers',
'class_name': 'Dense',
'config': {'name': 'dense_2',
'trainable': True,
'dtype': {'module': 'keras',
'class_name': 'DTypePolicy',
'config': {'name': 'float32'},
'registered_name': None},
'units': 10,
'activation': 'softmax',
'use_bias': True,
'kernel_initializer': {'module': 'keras.initializers',
'class_name': 'GlorotUniform',
'config': {'seed': None},
'registered_name': None},
'bias_initializer': {'module': 'keras.initializers',
'class_name': 'Zeros',
'config': {},
'registered_name': None},
'kernel_regularizer': None,
'bias_regularizer': None,
'kernel_constraint': None,
'bias_constraint': None},
'registered_name': None,
'build_config': {'input_shape': (None, 60)}}],
'build_input_shape': (None, 784)}5.5.3 Gewichtsmatrizen und Biasvektoren
Mit get_weights können wir auf die Parameter des Netzwerks zugreifen. Für jede Schicht gibt es jeweils
- eine Gewichtsmatrix und
- einen Bias-Vektor.
Wir lassen uns hier in einer Schleife jeweils die Dimensionen der Gewichtsmatrix und des Bias-Vektor für unsere zwei Schichten (Hidden + Output) ausgeben:
weights = model.get_weights()
for w in weights:
print(w.shape)(784, 60)
(60,)
(60, 10)
(10,)Wir sehen hier, dass die Gewichtsmatrix \(W^{(1)}\) von der Eingabeschicht zur versteckten Schicht die Dimensionen 784x60 hat. In unserer theoretischen Behandlung haben wir eine 60x784-Matrix verwendet, also die transponierte Version. Beide Varianten sind möglich und üblich.
Der Bias-Vektor von Input zu Hidden hat eine Länge von 60. Auch das ist plausibel, wenn Sie sich in der Abbildung oben ein Bias-Neuron in der Inputschicht vorstellen, dass mit allen 60 versteckten Neuronen verbunden ist. Dies muss offensichtlich 60 Gewichte haben.
5.5.4 Training
Beim Training wollen wir die ursprüngliche Variante des Backpropagation verwenden, wo alle Trainingsbeispiele vor einem Update durchlaufen werden. Wir nennen diese Variante Batchtraining (nicht zu verwechseln mit “Minibatch”, siehe unten).
In Keras spezifizieren wir dazu Stochastic Gradient Descent, kurz SGD, als Optimierungsmethode und geben als Batchgröße die Anzahl der Trainingsdaten an. Als Zielfunktion wählen wir wie im Theorieteil die Cross-Entropy-Funktion.
Lernrate
Damit wir die Lernrate einstellen können, erstellen wir für die Optimierungsmethode ein eigenes SGD-Objekt (stochastic gradient descent). Wir sehen uns mit get_config die Voreinstellungen an.
from tensorflow.keras.optimizers import SGD
opt = SGD()
opt.get_config(){'name': 'SGD',
'learning_rate': 0.009999999776482582,
'weight_decay': None,
'clipnorm': None,
'global_clipnorm': None,
'clipvalue': None,
'use_ema': False,
'ema_momentum': 0.99,
'ema_overwrite_frequency': None,
'loss_scale_factor': None,
'gradient_accumulation_steps': None,
'momentum': 0.0,
'nesterov': False}Die Standardeinstellung für die Lernrate ist also 0.01. Wir erstellen ein neues Objekt mit unserer gewünschten Lernrate:
opt = SGD(learning_rate = 0.1)
opt.get_config(){'name': 'SGD',
'learning_rate': 0.10000000149011612,
'weight_decay': None,
'clipnorm': None,
'global_clipnorm': None,
'clipvalue': None,
'use_ema': False,
'ema_momentum': 0.99,
'ema_overwrite_frequency': None,
'loss_scale_factor': None,
'gradient_accumulation_steps': None,
'momentum': 0.0,
'nesterov': False}5.5.5 Compile
Mit compile konfigurieren wir das Training zunächst nur und übergeben zum Beispiel die Optimiermethode als Objekt. Alternativ kann man als Parameter für optimizer den String sgd übergeben, dann werden für Lernrate etc. die Standardeinstellungen gewählt. Als Metrik für unsere Messungen wählen wir Accuracy, kurz acc.
model.compile(optimizer=opt,
loss='categorical_crossentropy',
metrics=['acc'])5.5.6 Fit
Das eigentliche Training wird mit fit durchgeführt. Wichtig ist, dass fit den Verlauf der Metriken pro Epoche in einem History-Objekt zurückgibt. Will man die Fehler- und Performance-Entwicklung später visualisieren, muss man dieses Objekt speichern.
Die Methode hat außer den Daten und Epochen noch ein paar Parameter:
- mit batch_size können Sie die Größe der Minibatches angeben (Standardmäßig 32)
- mit validation_data übergibt man Daten, auf denen nach jeder Epoche das Modell evaluiert wird; wir benutzen hier die echten Testdaten und keine speziellen Validierungsdaten
- mit verbose kann man die Ausgabe steuern (z.B. mit verbose=0 ausschalten).
Um Batchtraining zu realisieren, wählen wir eine Batchgröße von 60000, und bilden damit das originale Backpropagation nach, wo in einer Epoche alle Trainingsbeispiele verarbeitet werden, bevor ein Update der Gewichte durchgeführt wird (siehe auch Abschnitt 3.6).
Wir unterdrücken die Ausgabe (verbose=0), messen aber die Trainingsdauer mit Hilfe der Funktion time aus dem gleichnamigen Paket (gibt die Sekunden seit 1.1.1970 0:00 Uhr zurück).
start_time = time.time() # Wir merken uns die Startzeit
history1 = model.fit(x_train, y_train_1hot,
epochs=20,
batch_size=60000,
verbose=1,
validation_data = (x_test, y_test_1hot))
duration = time.time() - start_time # Wir berechnen die Dauer in Sek.
print(f'TRAININGSDAUER: {duration:.2f} Sek.')Epoch 1/20
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 345ms/step - acc: 0.0914 - loss: 2.5887 - val_acc: 0.0923 - val_loss: 2.4889
Epoch 2/20
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 158ms/step - acc: 0.0941 - loss: 2.4946 - val_acc: 0.0957 - val_loss: 2.4215
Epoch 3/20
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 119ms/step - acc: 0.0989 - loss: 2.4262 - val_acc: 0.1011 - val_loss: 2.3701
Epoch 4/20
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 127ms/step - acc: 0.1075 - loss: 2.3740 - val_acc: 0.1080 - val_loss: 2.3299
Epoch 5/20
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 128ms/step - acc: 0.1151 - loss: 2.3330 - val_acc: 0.1125 - val_loss: 2.2977
Epoch 6/20
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 114ms/step - acc: 0.1204 - loss: 2.3002 - val_acc: 0.1247 - val_loss: 2.2716
Epoch 7/20
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 125ms/step - acc: 0.1318 - loss: 2.2736 - val_acc: 0.1549 - val_loss: 2.2500
Epoch 8/20
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 115ms/step - acc: 0.1590 - loss: 2.2516 - val_acc: 0.1961 - val_loss: 2.2317
Epoch 9/20
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 125ms/step - acc: 0.1992 - loss: 2.2329 - val_acc: 0.2405 - val_loss: 2.2158
Epoch 10/20
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 114ms/step - acc: 0.2379 - loss: 2.2167 - val_acc: 0.2730 - val_loss: 2.2015
Epoch 11/20
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 136ms/step - acc: 0.2736 - loss: 2.2023 - val_acc: 0.3095 - val_loss: 2.1885
Epoch 12/20
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 157ms/step - acc: 0.3054 - loss: 2.1892 - val_acc: 0.3388 - val_loss: 2.1762
Epoch 13/20
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 124ms/step - acc: 0.3325 - loss: 2.1769 - val_acc: 0.3595 - val_loss: 2.1645
Epoch 14/20
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 125ms/step - acc: 0.3548 - loss: 2.1652 - val_acc: 0.3793 - val_loss: 2.1533
Epoch 15/20
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 115ms/step - acc: 0.3742 - loss: 2.1539 - val_acc: 0.3966 - val_loss: 2.1422
Epoch 16/20
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 114ms/step - acc: 0.3924 - loss: 2.1430 - val_acc: 0.4156 - val_loss: 2.1314
Epoch 17/20
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 124ms/step - acc: 0.4073 - loss: 2.1322 - val_acc: 0.4282 - val_loss: 2.1207
Epoch 18/20
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 106ms/step - acc: 0.4226 - loss: 2.1216 - val_acc: 0.4421 - val_loss: 2.1101
Epoch 19/20
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 104ms/step - acc: 0.4371 - loss: 2.1112 - val_acc: 0.4563 - val_loss: 2.0996
Epoch 20/20
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 106ms/step - acc: 0.4505 - loss: 2.1008 - val_acc: 0.4700 - val_loss: 2.0892
TRAININGSDAUER: 2.93 Sek.Die Trainingsdauer im Batchtraining ist mit 3 Sekunden für 20 Epochen extrem kurz.
5.5.7 Evaluation
Wir sehen uns die Entwicklung von Zielfunktion (Loss) und Accuracy an.
Dazu definieren wir vorab eine Hilfsfunktion.
def set_subplot(ax, y_label, traindata, testdata, ylim):
e_range = range(1, len(traindata) + 1)
ax.plot(e_range, traindata, 'b', label='Training')
ax.plot(e_range, testdata, 'g', label='Test')
ax.set_xlabel('Epochen')
ax.set_ylabel(y_label)
ax.legend()
ax.grid()
ax.set_ylim(ylim)
ax.set_title(y_label)Achten Sie bei den Plots immer auf die Grenzen der y-Achse (im Code set_ylim). Diese werden immer so gewählt, dass man die Kurve möglichst gut sieht. Hier haben wir das Interval 0 bis 0.6 für die Accuracy. Weiter unten haben wir ein anderes Interval. Dies muss man beim Vergleich der Kurven natürlich beachten.
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(15,4))
set_subplot(ax[0], 'Loss', history1.history['loss'],
history1.history['val_loss'], [0, 3])
set_subplot(ax[1], 'Accuracy', history1.history['acc'],
history1.history['val_acc'], [0, 0.6])
plt.show()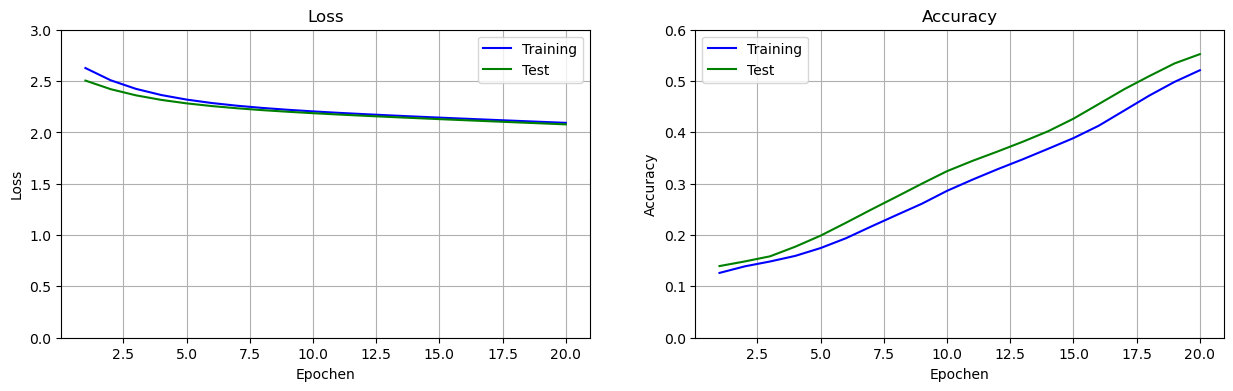
Mit evaluate können wir die Performanz unseres Modells auf den Testdaten messen. Wir bekommen ein Tupel mit Fehler und Accuracy zurück.
loss, acc = model.evaluate(x_test, y_test_1hot)
print(f"Evaluation auf den Testdaten:\n\nLoss = {loss:.3f}\nAccuracy = {acc:.3f}")313/313 ━━━━━━━━━━━━━━━━━━━━ 0s 383us/step - acc: 0.4524 - loss: 2.1002
Evaluation auf den Testdaten:
Loss = 2.089
Accuracy = 0.470Mit Batchtraining erhalten wir nach 20 Epochen Training eine enttäuschende Accuracy von 47% auf den Testdaten.
5.6 Einfluss der Batchgröße
Mit Batchtraining (Batchgröße = 60000) haben wir ein enttäuschendes Ergebnis erzielt. Wir sehen uns jetzt das reine SGD und eine Variante von Minibatch-Training an. Beides wurde in Abschnitt 3.6 eingeführt.
5.6.1 Reines SGD (Batchgröße = 1)
Wenn wir die Batchgröße auf 1 setzen, erreichen wir “reines” Stochastic Gradient Descent, wo die Gewichte nach jedem Trainingsbeispiel angepasst werden.
Wir erzeugen eine neue Instanz des Netzwerks mit den gleichen Eigenschaften (20 versteckte Neuronen, gleiche Aktivierungsfunktionen). Anschließend trainieren wir es unter gleichen Bedingungen. Der einzige Unterschied ist die Batchgröße, die wir hier auf 1 setzen.
model = Sequential()
model.add(Input(shape=(784,)))
model.add(Dense(60,
activation='sigmoid'))
model.add(Dense(10, activation='softmax'))
opt = SGD(learning_rate = 0.1)
model.compile(optimizer=opt,
loss='categorical_crossentropy',
metrics=['acc'])
start_time = time.time()
history2 = model.fit(x_train, y_train_1hot,
epochs=20,
batch_size=1,
verbose=1,
validation_data = (x_test, y_test_1hot))
duration = time.time() - start_time
print(f'TRAININGSDAUER: {duration:.2f} Sek.')Epoch 1/20
60000/60000 ━━━━━━━━━━━━━━━━━━━━ 26s 436us/step - acc: 0.8855 - loss: 0.3685 - val_acc: 0.9541 - val_loss: 0.1431
Epoch 2/20
60000/60000 ━━━━━━━━━━━━━━━━━━━━ 24s 406us/step - acc: 0.9590 - loss: 0.1313 - val_acc: 0.9581 - val_loss: 0.1357
Epoch 3/20
60000/60000 ━━━━━━━━━━━━━━━━━━━━ 25s 413us/step - acc: 0.9672 - loss: 0.1048 - val_acc: 0.9609 - val_loss: 0.1255
Epoch 4/20
60000/60000 ━━━━━━━━━━━━━━━━━━━━ 24s 394us/step - acc: 0.9736 - loss: 0.0862 - val_acc: 0.9620 - val_loss: 0.1320
Epoch 5/20
60000/60000 ━━━━━━━━━━━━━━━━━━━━ 23s 387us/step - acc: 0.9754 - loss: 0.0783 - val_acc: 0.9653 - val_loss: 0.1185
Epoch 6/20
60000/60000 ━━━━━━━━━━━━━━━━━━━━ 24s 394us/step - acc: 0.9780 - loss: 0.0703 - val_acc: 0.9642 - val_loss: 0.1297
Epoch 7/20
60000/60000 ━━━━━━━━━━━━━━━━━━━━ 23s 387us/step - acc: 0.9795 - loss: 0.0649 - val_acc: 0.9691 - val_loss: 0.1145
Epoch 8/20
60000/60000 ━━━━━━━━━━━━━━━━━━━━ 23s 389us/step - acc: 0.9817 - loss: 0.0546 - val_acc: 0.9677 - val_loss: 0.1142
Epoch 9/20
60000/60000 ━━━━━━━━━━━━━━━━━━━━ 23s 389us/step - acc: 0.9833 - loss: 0.0509 - val_acc: 0.9696 - val_loss: 0.1168
Epoch 10/20
60000/60000 ━━━━━━━━━━━━━━━━━━━━ 24s 393us/step - acc: 0.9853 - loss: 0.0433 - val_acc: 0.9661 - val_loss: 0.1324
Epoch 11/20
60000/60000 ━━━━━━━━━━━━━━━━━━━━ 24s 398us/step - acc: 0.9851 - loss: 0.0447 - val_acc: 0.9686 - val_loss: 0.1226
Epoch 12/20
60000/60000 ━━━━━━━━━━━━━━━━━━━━ 24s 394us/step - acc: 0.9879 - loss: 0.0372 - val_acc: 0.9665 - val_loss: 0.1270
Epoch 13/20
60000/60000 ━━━━━━━━━━━━━━━━━━━━ 24s 394us/step - acc: 0.9884 - loss: 0.0353 - val_acc: 0.9689 - val_loss: 0.1275
Epoch 14/20
60000/60000 ━━━━━━━━━━━━━━━━━━━━ 24s 394us/step - acc: 0.9891 - loss: 0.0340 - val_acc: 0.9692 - val_loss: 0.1270
Epoch 15/20
60000/60000 ━━━━━━━━━━━━━━━━━━━━ 24s 398us/step - acc: 0.9912 - loss: 0.0275 - val_acc: 0.9704 - val_loss: 0.1211
Epoch 16/20
60000/60000 ━━━━━━━━━━━━━━━━━━━━ 24s 396us/step - acc: 0.9908 - loss: 0.0276 - val_acc: 0.9627 - val_loss: 0.1444
Epoch 17/20
60000/60000 ━━━━━━━━━━━━━━━━━━━━ 140s 2ms/step - acc: 0.9906 - loss: 0.0276 - val_acc: 0.9695 - val_loss: 0.1358
Epoch 18/20
60000/60000 ━━━━━━━━━━━━━━━━━━━━ 24s 404us/step - acc: 0.9914 - loss: 0.0254 - val_acc: 0.9688 - val_loss: 0.1314
Epoch 19/20
60000/60000 ━━━━━━━━━━━━━━━━━━━━ 58s 970us/step - acc: 0.9929 - loss: 0.0204 - val_acc: 0.9694 - val_loss: 0.1348
Epoch 20/20
60000/60000 ━━━━━━━━━━━━━━━━━━━━ 24s 404us/step - acc: 0.9950 - loss: 0.0159 - val_acc: 0.9700 - val_loss: 0.1368
TRAININGSDAUER: 628.40 Sek.Wir sehen, dass das Training mit reinem SGD mit ca. 10 Minuten deutlich länger dauert als beim Batchtraining mit seinen 2 Sekunden - in beiden Fällen für 20 Epochen.
Das liegt daran, dass hier in jeder Epoche 60000 Mal sämtliche Gewichte angepasst werden, wohingegen vorher nur ein einziges Update pro Epoche stattfand.
Jetzt schauen wir uns die Performance an. Achten Sie auf den Wertebereich, der bei der Accuracy-Kurve zwischhen 0.9 und 1.0 liegt.
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(15,4))
set_subplot(ax[0], 'Loss', history2.history['loss'],
history2.history['val_loss'], [0, .5])
set_subplot(ax[1], 'Accuracy', history2.history['acc'],
history2.history['val_acc'], [0.9, 1])
plt.show()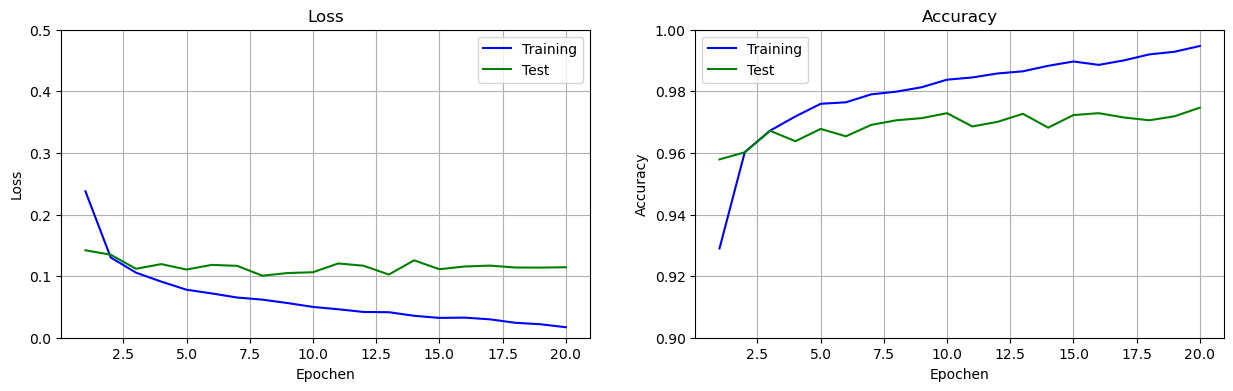
Wir sehen einen typischen Verlauf der Accuracy: Auf den Trainingsdaten steigt die Kurve immer weiter an, aber auf den Testdaten bleibt die Kurve in einem bestimmten Bereich. Sobald die Kurve auf den Testdaten sich einpendelt, kann man das Training beenden, weil das Training anschließend Overfitting betreibt.
Wir schauen uns jetzt noch einmal den finalen Accuracy-Wert auf den Testdaten an:
loss, acc = model.evaluate(x_test, y_test_1hot)
print(f"Evaluation auf den Testdaten:\n\nLoss = {loss:.3f}\nAccuracy = {acc:.3f}")313/313 ━━━━━━━━━━━━━━━━━━━━ 0s 421us/step - acc: 0.9655 - loss: 0.1594
Evaluation auf den Testdaten:
Loss = 0.137
Accuracy = 0.970Mit 97% Accuracy auf den Testdaten erreicht das mit reinem SGD trainierte Netz einen deutlich besseren Wert als das vorigen Netz, dass wir mit Batchtraining trainiert haben.
5.6.2 Minibatch (Batchgröße = 32)
Nachdem wir Batchtraining (alle Trainingsbeispiele pro Update) und reines SGD (Batchgröße = 1) ausprobiert haben, setzen wir jetzt die eigentliche Idee von Minibatch um, dass eine bestimmte Anzahl von (zufällig ausgewählten) Trainingsdaten durchlaufen wird, bevor dann ein Update durchgeführt wird. Es handelt sich also um einen Kompromiss zwischen Batchtraining und reinem SGD.
Im Keras ist bei der Methode SGD eine Batchgröße von 32 standardmäßig eingestellt. Diese probieren wir jetzt aus. Den Parameter batch_size lassen wir weg, damit die Standardgröße von 32 genommen wird. Alles andere bleibt wie in den beiden anderen Versuchen gleich.
model = Sequential()
model.add(Input(shape=(784,)))
model.add(Dense(60,
activation='sigmoid'))
model.add(Dense(10, activation='softmax'))
opt = SGD(learning_rate = 0.1)
model.compile(optimizer=opt,
loss='categorical_crossentropy',
metrics=['acc'])
start_time = time.time()
history3 = model.fit(x_train, y_train_1hot,
epochs=20,
verbose=1,
validation_data = (x_test, y_test_1hot))
duration = time.time() - start_time
print(f'TRAININGSDAUER: {duration:.2f} Sek.')Epoch 1/20
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 1s 648us/step - acc: 0.7685 - loss: 0.9333 - val_acc: 0.9115 - val_loss: 0.3115
Epoch 2/20
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 1s 545us/step - acc: 0.9117 - loss: 0.3071 - val_acc: 0.9248 - val_loss: 0.2558
Epoch 3/20
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 1s 538us/step - acc: 0.9274 - loss: 0.2505 - val_acc: 0.9351 - val_loss: 0.2238
Epoch 4/20
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 1s 651us/step - acc: 0.9374 - loss: 0.2189 - val_acc: 0.9427 - val_loss: 0.1956
Epoch 5/20
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 1s 725us/step - acc: 0.9449 - loss: 0.1961 - val_acc: 0.9482 - val_loss: 0.1803
Epoch 6/20
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 1s 650us/step - acc: 0.9501 - loss: 0.1736 - val_acc: 0.9518 - val_loss: 0.1643
Epoch 7/20
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 1s 539us/step - acc: 0.9539 - loss: 0.1632 - val_acc: 0.9539 - val_loss: 0.1557
Epoch 8/20
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 1s 521us/step - acc: 0.9586 - loss: 0.1460 - val_acc: 0.9570 - val_loss: 0.1453
Epoch 9/20
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 1s 526us/step - acc: 0.9607 - loss: 0.1375 - val_acc: 0.9602 - val_loss: 0.1365
Epoch 10/20
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 1s 588us/step - acc: 0.9624 - loss: 0.1296 - val_acc: 0.9610 - val_loss: 0.1309
Epoch 11/20
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 1s 543us/step - acc: 0.9659 - loss: 0.1199 - val_acc: 0.9634 - val_loss: 0.1255
Epoch 12/20
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 1s 542us/step - acc: 0.9676 - loss: 0.1149 - val_acc: 0.9640 - val_loss: 0.1235
Epoch 13/20
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 1s 605us/step - acc: 0.9689 - loss: 0.1086 - val_acc: 0.9641 - val_loss: 0.1166
Epoch 14/20
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 1s 525us/step - acc: 0.9717 - loss: 0.1016 - val_acc: 0.9665 - val_loss: 0.1123
Epoch 15/20
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 1s 512us/step - acc: 0.9727 - loss: 0.0975 - val_acc: 0.9662 - val_loss: 0.1095
Epoch 16/20
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 1s 509us/step - acc: 0.9746 - loss: 0.0940 - val_acc: 0.9660 - val_loss: 0.1073
Epoch 17/20
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 1s 540us/step - acc: 0.9755 - loss: 0.0880 - val_acc: 0.9666 - val_loss: 0.1049
Epoch 18/20
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 1s 552us/step - acc: 0.9768 - loss: 0.0837 - val_acc: 0.9680 - val_loss: 0.1021
Epoch 19/20
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 1s 540us/step - acc: 0.9773 - loss: 0.0805 - val_acc: 0.9688 - val_loss: 0.1019
Epoch 20/20
1875/1875 ━━━━━━━━━━━━━━━━━━━━ 1s 500us/step - acc: 0.9780 - loss: 0.0776 - val_acc: 0.9692 - val_loss: 0.0972
TRAININGSDAUER: 21.76 Sek.Minibatch liegt mit einer Dauer von ca. 22 Sekunden zwischen Batch-Training (3 Sek.) und reinem SGD (8 Min.). Interessant ist, dass es doch erheblich schneller ist als reines SGD.
Wir sehen uns wieder die Performance an:
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(15,4))
set_subplot(ax[0], 'Loss', history3.history['loss'],
history3.history['val_loss'], [0, 1])
set_subplot(ax[1], 'Accuracy', history3.history['acc'],
history3.history['val_acc'], [0.8, 1])
plt.show()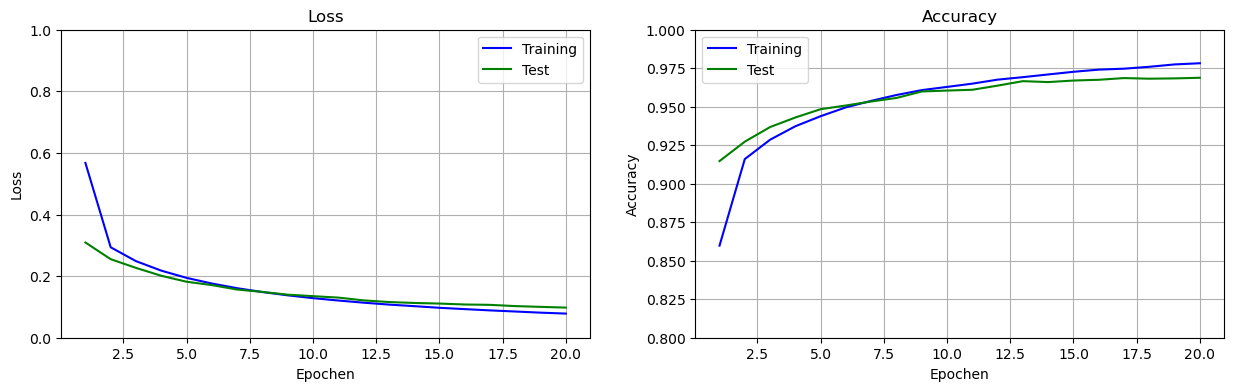
loss, acc = model.evaluate(x_test, y_test_1hot)
print(f"Evaluation auf den Testdaten:\n\nLoss = {loss:.3f}\nAccuracy = {acc:.3f}")313/313 ━━━━━━━━━━━━━━━━━━━━ 0s 368us/step - acc: 0.9639 - loss: 0.1109
Evaluation auf den Testdaten:
Loss = 0.097
Accuracy = 0.969Die Performance für unser Minibatch-Training mit Batchgröße 32 ist mit einer 97% Accuracy auf den Testdaten praktisch gleich zur Performance mit reinem SGD.
5.6.3 Fazit
Schauen wir uns die Resultate nochmal im Vergleich an (unten sieht man auch die jeweilige Accuracy als Kurve über die Epochen).
| Trainingsdauer | Accuracy (Test) | |
|---|---|---|
| Batchtraining | 3 Sek | 27% |
| Reines SGD | 10 Min | 97% |
| Minibatch (32) | 22 Sek | 97% |
Es scheint - zumindest bei diesen Daten - so zu sein, dass man mit Minibatch-Training mit der voreingestellten Batchgröße am besten fährt, da man eine hohe Accuracy bei tolerierbarer Trainingsdauer erzielt.
Wir sehen uns nochmal die Kurven der drei Ansätze nebeneinander an.
fig, ax = plt.subplots(nrows=1, ncols=3, figsize=(15,4))
set_subplot(ax[0], 'Batchgröße 60000 / Accuracy', history1.history['acc'], history1.history['val_acc'], [0, 1])
set_subplot(ax[1], 'Batchgröße 1 / Accuracy', history2.history['acc'], history2.history['val_acc'], [0.85, 1])
set_subplot(ax[2], 'Batchgröße 32 / Accuracy', history3.history['acc'], history3.history['val_acc'], [0.85, 1])
plt.show()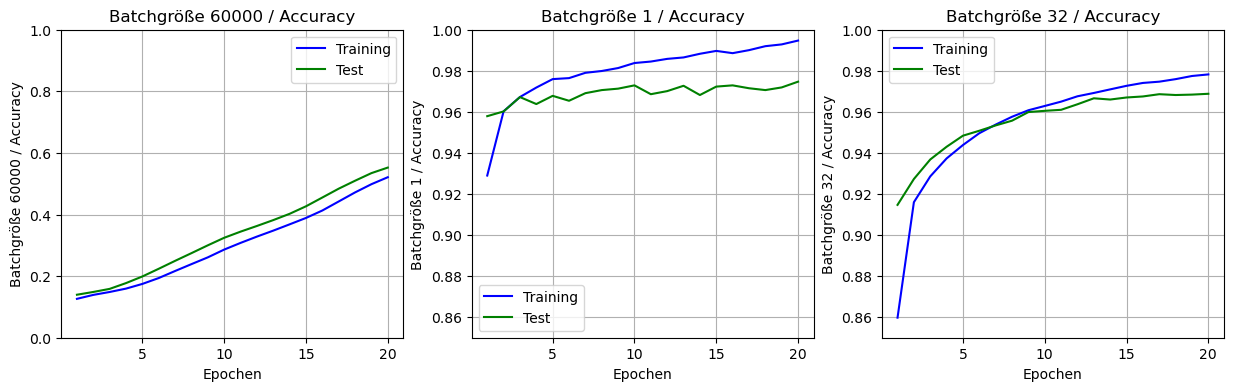
Wichtig ist immer, sich die Rahmenbedingungen des obigen “Experiments” vor Augen zu führen. Wir haben die Optimierungsmethode Stochastic Gradient Descent mit einer Lernrate von 0.1 verwendet und für 20 Epochen trainiert. Wir hatten ein FNN mit einer versteckten Schicht mit 60 Neuronen und haben auf den MNIST-Daten gearbeitet. Sollte sich einer dieser Umstände ändern, kann das die Ergebnisse verändern.
Zudem müsste man jede der drei Variante mehrfach testen (z.B. 10x) und dann den Mittelwert von Dauer und Accuracy nehmen, um statistische Glaubwürdigkeit zu erreichen. In unserem Beispiel sind die Unterschiede allerdings so deutlich, dass wir uns das ersparen.