import keras_tuner
from kerastuner import HyperModelAnhang C: Keras - Suche nach Hyperparametern
In diesem Kapitel lernen wir, wie man in Keras die Suche nach guten Hyperparametern automatisieren kann. Zur Erinnerung: Hyperparameter sind solche Parameter, die man vor dem Training festlegt, die aber während des Trainings fix bleiben. Beispiele sind die Anzahl der Schichten, der Neuronen pro Schicht oder die Lernrate. Man nennt das automatisierte Suchen nach guten Hyperparametern auch Hyperparameter Tuning. Diese Methode erfordert viel Rechenpower und Zeit, da im Grunde verschiedene Konfigurationen durchgetestet werden.
C.1 Motivation
Wenn man ein Neuronales Netz erstellt und später trainiert, muss man verschiedene Entscheidungen treffen:
- Anzahl der Schichten
- Typ einer Schicht (z.B. Dense vs. Conv2D)
- Anzahl der Neuronen pro Schicht
- Einfügen einer Dropout-Schicht (oder nicht)
- Optimierungsmethode (SGD, Adam etc.)
- Lernrate (zu Trainingsbeginn)
Diese Aspekte fallen alle unter den Begriff Hyperparameter, weil dies Parameter sind, die sich während des Trainings nicht ändern.
Wie trifft man als Mensch diese Entscheidungen? In der Regel orientiert man sich an Netzen, die man schon einmal gesehen hat oder die in wissenschaftlichen Publikationen dargestellt sind, und anschließend “probiert” man mehr oder weniger systematisch, an den Hyperparametern zu drehen (und protokolliert hoffentlich die jeweiligen Outcomes). Natürlich kommt man schnell auf die Idee, diesen Prozess zu automatisieren. Das nennt man auch Hyperparameter Tuning oder Hyperparameter Optimization.
Wir spielen hier alle Schritte anhand eines einfachen Versuchs durch, wo wir in einem Netz lediglich die Größe der versteckten Schicht ändern und mit der Strategie “Random Search” in 6 Versuchen unterschiedliche Werte für diesen einen Hyperparameter testen.
Siehe auch den Artikel Getting started with KerasTuner vom Keras-Team.
C.2 Einrichtung
C.2.1 Keras-Tuner
In Keras gibt es dazu das Paket keras-tuner, das extra installiert werden muss. Die Installation selbst behandeln wir hier nicht im Detail.
Ist der Keras-Tuner installiert, benötigen wir die folgenden Importe:
C.2.2 Hyperparameter konfigurieren
Wir erstellen ein Objekt vom Typ HyperParameters, das später Werte für unsere Hyperparameter erzeugt und uns erlaubt zu spezifizieren, aus welchem Wertebereich die Hyperparameter genommen werden sollen.
hp = keras_tuner.HyperParameters()Das Objekt hp vom Typ HyperParameters hat mehrere Funktionen, um Werte von einem bestimmten Typ zu generieren, zum Beispiel Int, Float oder Boolean. Ähnlich wie bei einer Schleife gibt man die Wertegrenzen in Form von Minimum und Maximum an sowie eine Schritteweite. Beim Funktionsaufruf wird auch ein Bezeichner (z.B. “units”) spezifiziert, damit das Objekt die verschiedenen Werte unterscheiden kann (z.B. Neuronenanzahl für Schicht 2 und Schicht 3), zum Beispiel:
print(hp.Int("units_2", min_value=32, max_value=512, step=32))32Bei der Funktion Choice wird eine Liste von möglichen Werten definiert. Zum Beispiel:
hp.Choice("activation", ["relu", "tanh"])'relu'Die komplette Liste von Funktionen und ihrer Parameter finden Sie in der Keras-API HyperParameters.
C.2.3 Daten
Für unser Beispiel nehmen wir die CIFAR-10-Daten (siehe Abschnitt 9.3.2). CIFAR-10 enthält 60000 Farbbilder (32x32x3) mit Abbildungen aus 10 Kategorien wie “ship” oder “dog”.
import numpy as np
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.datasets import cifar10
(train_x, train_y), (test_x, test_y) = cifar10.load_data()
train_x = train_x/255.0
test_x = test_x/255.0
train_y = to_categorical(train_y, 10)
test_y = to_categorical(test_y, 10)
print(train_x.shape, test_x.shape)
print(test_y.shape)(50000, 32, 32, 3) (10000, 32, 32, 3)
(10000, 10)train_x[0].shape(32, 32, 3)C.2.4 Modell-Erzeugungsfunktion
Wir definieren eine Funktion, die ein Modell mit Hilfe eine HyperParameter-Objekts baut. Das Objekt trifft die Entscheidung über die Hyperparameter des generierten Modells.
Wir spezifizieren den Input hier explizit, weil wir sonst die Funktion summary nicht aufrufen können.
from tensorflow.keras import Input
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
def build_model(hp):
model = Sequential()
model.add(Input(shape=train_x[0].shape))
model.add(Flatten())
model.add(Dense(hp.Int("num_hidden", min_value=50, max_value=1000, step=50),
activation="relu"))
model.add(Dense(10,
activation="softmax"))
model.compile(optimizer="adam", loss="categorical_crossentropy", metrics=["acc"])
return modelSanity check: Wird ein Modell erzeugt und wie sieht es aus?
model = build_model(hp)
model.summary()Metal device set to: Apple M1 Max
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 3072) 0
dense (Dense) (None, 50) 153650
dense_1 (Dense) (None, 10) 510
=================================================================
Total params: 154,160
Trainable params: 154,160
Non-trainable params: 0
_________________________________________________________________2022-06-21 18:08:26.965512: I tensorflow/core/common_runtime/pluggable_device/pluggable_device_factory.cc:305] Could not identify NUMA node of platform GPU ID 0, defaulting to 0. Your kernel may not have been built with NUMA support.
2022-06-21 18:08:26.965646: I tensorflow/core/common_runtime/pluggable_device/pluggable_device_factory.cc:271] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 0 MB memory) -> physical PluggableDevice (device: 0, name: METAL, pci bus id: <undefined>)C.3 Tuning
Im eigentlichen Tuning wird die Modell-Erzeugungsfunktion einer Tuning-Funktion übergeben, die dann systematisch Modelle erzeugt, testet und speichert.
C.3.1 Suchmethode wählen
Keras bietet verschiedene Suchmethoden an, um den Raum der Hyperparameter zu durchlaufen:
Bei der einfachsten Methode RandomSearch wird eine Anzahl von Versuchen festgelegt und bei jedem Versuch werden die Hyperparameter zufällig gewählt. Man gibt für jeden Hyperparameter an, innerhalb welcher Grenzen gewählt werden soll. Im Gegensatz dazu wird bei GridSearch wirklich jede mögliche Kombination von Hyperparametern durchlaufen (auch hier legt man natürlich Wertebereiche fest).
RandomSearch
Wir wählen die Methode RandomSearch. Zunächst wird ein Objekt vom Typ RandomSearch mit Konfigurationsdaten erstellt. Ein “Versuch” (trial) bezieht sich auf ein spezifisches Modell mit festgelegten Hyperparametern.
- objective: Metrik, anhand der die Modelle bewertet werden sollen
- max_trials: Maximale Anzahl der Versuche
- executions_per_trial: Für jeden Versuche kann man mehrere Läufe anstellen
- overwrite: Wenn man eine Suche fortsetzen möchte, kann man hier False angeben
- directory: Hier werden Log-Informationen hineingeschrieben
tuner = keras_tuner.RandomSearch(
hypermodel=build_model,
objective="val_acc",
max_trials=6,
executions_per_trial=1,
overwrite=True,
directory="hyperparameter_tuning",
project_name="simple",
)Wir legen hier 6 Versuche fest. Bei jedem Versuch wird nur 1x trainiert. Wie viele Epochen pro Versuch durchlaufen werden, wird später festgelegt.
Suchraum
Man kann sich jetzt den Suchraum anzeigen lassen. Hier sieht man im Grunde, an welchen Stellen man einen Hyperparameter von Keras wählen lässt.
Wir sehen, dass es nur einen Hyperparameter gibt, der variiert wird.
tuner.search_space_summary()Search space summary
Default search space size: 1
num_hidden (Int)
{'default': None, 'conditions': [], 'min_value': 50, 'max_value': 1000, 'step': 50, 'sampling': None}C.3.2 Suche durchführen
Jetzt können wir die Suche starten. Für die Anzahl der Epochen nimmt man einen relativ niedrigen Wert, z.B. 4 oder 10, damit man auch viele Durchläufe in realistischer Zeit schafft. Wir haben wir nur wenige Durchläufe (6 Versuche). In einem realistischen Beispiel würde man die Anzahl der Versuche erhöhen. Eine Epochenzahl von 4-10 ist auch bei größeren Versuchen realistisch.
Während der Suche wird immer der bislang beste Wert angezeigt. Die Suche dauert natürlich etwas.
tuner.search(train_x, train_y,
epochs=4,
validation_data=(test_x, test_y))Trial 6 Complete [00h 00m 48s]
val_acc: 0.44450002908706665
Best val_acc So Far: 0.4547000229358673
Total elapsed time: 00h 04m 39s
INFO:tensorflow:Oracle triggered exitWir sehen, dass 6 Versuche in 4 Minuten unternommen wurden und die beste Performance 45% betrug.
C.4 Auswertung
C.4.1 Beste Modelle
Alle Modelle aus den 6 Versuchen werden gespeichert. Wir sehen uns die besten zwei an.
models = tuner.get_best_models(num_models=2)
models[<keras.engine.sequential.Sequential at 0x316508c10>,
<keras.engine.sequential.Sequential at 0x316508280>]models[0].summary()Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 3072) 0
dense (Dense) (None, 950) 2919350
dense_1 (Dense) (None, 10) 9510
=================================================================
Total params: 2,928,860
Trainable params: 2,928,860
Non-trainable params: 0
_________________________________________________________________models[1].summary()Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 3072) 0
dense (Dense) (None, 900) 2765700
dense_1 (Dense) (None, 10) 9010
=================================================================
Total params: 2,774,710
Trainable params: 2,774,710
Non-trainable params: 0
_________________________________________________________________Was wurde probiert?
Mit der Funktion results_summary können Sie ausgeben, welche Versuche unternommen wurden, wie die jeweiligen Parameter gewählt wurden (hier nur “num_hidden”) und welche Performance erzielt wurde.
tuner.results_summary()Results summary
Results in hyperparameter_tuning/simple
Showing 10 best trials
<keras_tuner.engine.objective.Objective object at 0x314e09820>
Trial summary
Hyperparameters:
num_hidden: 950
Score: 0.4547000229358673
Trial summary
Hyperparameters:
num_hidden: 900
Score: 0.44450002908706665
Trial summary
Hyperparameters:
num_hidden: 250
Score: 0.44050002098083496
Trial summary
Hyperparameters:
num_hidden: 450
Score: 0.42970001697540283
Trial summary
Hyperparameters:
num_hidden: 200
Score: 0.4097000062465668
Trial summary
Hyperparameters:
num_hidden: 100
Score: 0.3987000286579132C.4.2 Bestes Modell trainieren und evaluieren
Jetzt haben wir ja in der Suche nur für eine reduzierte Anzahl von Epochen trainiert.
Wir können jetzt das beste Modell wählen und es mit einer Epochenzahl, die uns angemessen erscheint, trainieren.
best_hps = tuner.get_best_hyperparameters(3)
best_hps[<keras_tuner.engine.hyperparameters.HyperParameters at 0x31636ed30>,
<keras_tuner.engine.hyperparameters.HyperParameters at 0x3165031c0>,
<keras_tuner.engine.hyperparameters.HyperParameters at 0x314e134f0>]model = build_model(best_hps[0])
model.summary()Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_1 (Flatten) (None, 3072) 0
dense_2 (Dense) (None, 950) 2919350
dense_3 (Dense) (None, 10) 9510
=================================================================
Total params: 2,928,860
Trainable params: 2,928,860
Non-trainable params: 0
_________________________________________________________________Training
Wir trainieren das gewählte Modell über 20 Epochen.
history = model.fit(train_x, train_y,
epochs=20,
validation_data=(test_x, test_y))Epoch 1/20
17/1563 [..............................] - ETA: 10s - loss: 4.7808 - acc: 0.11952022-06-21 18:13:07.739950: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:112] Plugin optimizer for device_type GPU is enabled.1557/1563 [============================>.] - ETA: 0s - loss: 1.8898 - acc: 0.32992022-06-21 18:13:18.659267: I tensorflow/core/grappler/optimizers/custom_graph_optimizer_registry.cc:112] Plugin optimizer for device_type GPU is enabled.1563/1563 [==============================] - 13s 8ms/step - loss: 1.8898 - acc: 0.3301 - val_loss: 1.7331 - val_acc: 0.3798
Epoch 2/20
1563/1563 [==============================] - 12s 8ms/step - loss: 1.6864 - acc: 0.3961 - val_loss: 1.6275 - val_acc: 0.4234
Epoch 3/20
1563/1563 [==============================] - 12s 8ms/step - loss: 1.6193 - acc: 0.4248 - val_loss: 1.5797 - val_acc: 0.4350
Epoch 4/20
1563/1563 [==============================] - 12s 7ms/step - loss: 1.5763 - acc: 0.4397 - val_loss: 1.5650 - val_acc: 0.4419
Epoch 5/20
1563/1563 [==============================] - 12s 7ms/step - loss: 1.5497 - acc: 0.4474 - val_loss: 1.5508 - val_acc: 0.4528
Epoch 6/20
1563/1563 [==============================] - 12s 8ms/step - loss: 1.5273 - acc: 0.4575 - val_loss: 1.5335 - val_acc: 0.4501
Epoch 7/20
1563/1563 [==============================] - 12s 8ms/step - loss: 1.5064 - acc: 0.4664 - val_loss: 1.5794 - val_acc: 0.4388
Epoch 8/20
1563/1563 [==============================] - 12s 8ms/step - loss: 1.4854 - acc: 0.4728 - val_loss: 1.5184 - val_acc: 0.4626
Epoch 9/20
1563/1563 [==============================] - 12s 8ms/step - loss: 1.4703 - acc: 0.4776 - val_loss: 1.5376 - val_acc: 0.4590
Epoch 10/20
1563/1563 [==============================] - 12s 8ms/step - loss: 1.4584 - acc: 0.4841 - val_loss: 1.5514 - val_acc: 0.4569
Epoch 11/20
1563/1563 [==============================] - 12s 7ms/step - loss: 1.4416 - acc: 0.4875 - val_loss: 1.4930 - val_acc: 0.4751
Epoch 12/20
1563/1563 [==============================] - 12s 8ms/step - loss: 1.4325 - acc: 0.4898 - val_loss: 1.4912 - val_acc: 0.4717
Epoch 13/20
1563/1563 [==============================] - 12s 7ms/step - loss: 1.4229 - acc: 0.4952 - val_loss: 1.4855 - val_acc: 0.4759
Epoch 14/20
1563/1563 [==============================] - 12s 8ms/step - loss: 1.4129 - acc: 0.4969 - val_loss: 1.4816 - val_acc: 0.4794
Epoch 15/20
1563/1563 [==============================] - 12s 8ms/step - loss: 1.4076 - acc: 0.4974 - val_loss: 1.4736 - val_acc: 0.4832
Epoch 16/20
1563/1563 [==============================] - 12s 7ms/step - loss: 1.3984 - acc: 0.5030 - val_loss: 1.4813 - val_acc: 0.4827
Epoch 17/20
1563/1563 [==============================] - 12s 8ms/step - loss: 1.3901 - acc: 0.5057 - val_loss: 1.5041 - val_acc: 0.4756
Epoch 18/20
1563/1563 [==============================] - 12s 8ms/step - loss: 1.3801 - acc: 0.5083 - val_loss: 1.5288 - val_acc: 0.4658
Epoch 19/20
1563/1563 [==============================] - 12s 8ms/step - loss: 1.3723 - acc: 0.5114 - val_loss: 1.5389 - val_acc: 0.4637
Epoch 20/20
1563/1563 [==============================] - 12s 8ms/step - loss: 1.3672 - acc: 0.5136 - val_loss: 1.4764 - val_acc: 0.4809Visualisierung
import matplotlib.pyplot as plt
def show_loss_acc(h):
plt.figure(figsize=(12, 8))
plt.subplot(2, 2, 1)
plt.plot(h['loss'], label='train loss')
plt.plot(h['val_loss'], label='val loss')
plt.legend()
plt.subplot(2, 2, 2)
plt.plot(h['acc'], label='train acc')
plt.plot(h['val_acc'], label='val acc')
plt.legend()
plt.show()Jetzt können wir uns noch die Trainingskurven ansehen.
show_loss_acc(history.history)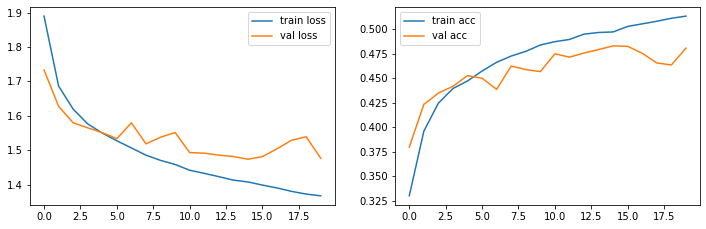
C.5 Fazit
Wir haben also herausgefunden, dass ein Netz mit 950 Neuronen besser performt als ein Netz mit weniger Neuronen. Weil wir die Suche auf 6 Trials beschränkt hatten, wurde ein Netz mit 1000 Neuronen gar nicht ausprobiert. Und natürlich gibt es eine Reihe von anderen Möglichkeiten, die Netzarchitektur oder das Training zu ändern, etwa mehrere Schichten oder eine andere Lernrate.
Mit dem gefundenen Netz haben wir ca. 48% auf den Testdaten erzielt.
Ganz allgemein können Sie mit Hyperparameter-Tuning praktisch alle Hyperparameter addressieren, sowohl für Feedforward-Netze als auch für Konvolutionsnetze.
Zu den wichtigsten Hyperparametern gehören sicherlich:
- Anzahl der Schichten
- Typ und Reihenfolge der Schichten (insbes. bei CNN: ConvLayer, Dense, Pooling)
- Anzahl der Neuronen einer Schicht (bei Konv-Schichten auch Filtergröße und Filteranzahl, bei Pooling-Schichten Filtergröße und Stride)
- Lernrate
Weitere Hyperparameter, die evtl. untersuchenswert sind:
- Optimierungsmethode (Adam, RMSprop etc.)
- Batchgröße
- Momentum