Stand: 17.03.2024
2.1 Geschichte des World Wide Web
In diesem Teil der Vorlesung beschäftigen wir uns mit der Entwicklung von Webseiten und bewegen uns somit auf der Ebene des World Wide Web (WWW). Das WWW ist nur ein Teil des Internets, wie auch in der Definition von Wikipedia (Abruf: 03/2019) klar wird:
Umgangssprachlich wird das World Wide Web oft mit dem Internet gleichgesetzt, es ist jedoch jünger und stellt nur eine von mehreren möglichen Nutzungen des Internets dar. [...] Zum Aufrufen von Inhalten aus dem World Wide Web wird ein Webbrowser benötigt, der z. B. auf einem PC oder einem Smartphone läuft. Mit ihm kann der Benutzer die auf einem beliebigen, von ihm ausgewählten Webserver bereitgestellten Daten herunterladen und auf einem geeigneten Ausgabegerät wie einem Bildschirm oder einer Braillezeile anzeigen lassen. Der Benutzer kann dann den Hyperlinks auf der angezeigten Webseite folgen, die auf andere Webseiten verweisen, gleichgültig ob diese auf demselben Webserver oder einem anderen gespeichert sind. So ergibt sich ein weltweites Netz aus Webseiten. Das Verfolgen der Hyperlinks wird auch als „Surfen im Internet“ bezeichnet.
Schauen wir uns eine Auswahl wichtiger Meilensteine aus der Geschichte des WWW an.
1960: Hypertext
Ted Nelson erfindet das Konzept des Hypertexts mit seinem Xanadu-Projekt:
- erlaubt die Verlinkung von Dokumenten zum parallelen Lesen und Verfolgen von Quellen zu ihren Ursprüngen
- damals fehlte allerdings die technische Expertise, um diese Ideen auf nutzbare Weise umzusetzen
- das Projekt wurde dann überholt von anderen Entwicklungen
1989: World Wide Web, HTML und HTTP
Tim Berners-Lee erfindet am CERN (Physik-Forschungsinstitut mit Teilchenbeschleunigern) in der Schweiz das World Wide Web, um interessante Forschungsinformationen mit Kollegen auszutauschen
- Statische Seiten werden über die Markup-Sprache HTML definiert: Ein Client (Browser des Benutzers) stellt ein angefragtes Dokument des Servers(z. B. Zeitung) dar
- Kommunikation über das Protokoll HTTP mit dem Request-Response-Prinzip
- Vorläufer der URL entwickelt
1990er: Dynamische Webseiten, Webanwendungen
Es entstehen zunehmend dynamische Webseiten für z. B. für das Online-Shopping; der Client zeigt Sicht auf das Kundenkonto (auf dem Server), welches ständig aktualisiert wird. Man spricht von Webanwendungen oder Web-Apps, wo der Browser die grafische Schnittstelle wird, wohingegen auf dem Server die eigentliche Programmlogik liegt. Dem User werden individuelle Webseiten zugespielt.
1998: XML
Einführung von XML (Extensible Markup Language) als "Meta-Sprache", das die Strukturierung und Austausch von Daten im Web standardisiert und die Grundlage für zahlreiche Webtechnologien bildet.
2000er: Web 2.0
Neue Webanwendungen, in denen User selbst Inhalte einstellen können, werden unter dem Begriff Web 2.0 zusammengefasst:
- Benutzer ohne technisches Vorwissen generieren Inhalte über Webinterfaces (z. B. Kommentare, Bewertungen, Blogs)
- Backend für "Autoren" und Frontend für die Öffentlichkeit
- Online-Communities (z. B. Foren)
- Kollaboration (z. B. Wikis)
Definition von Web 2.0 bei Wikipedia (Abruf 03/2019):
Web 2.0 ist ein Schlagwort, das für eine Reihe interaktiver und kollaborativer Elemente des Internets, speziell des World Wide Webs, verwendet wird.
2004: Soziale Medien
Der Begriff Soziale Medien ersetzt nach und nach den Begriff des Web 2.0. Das erste erfolgreiche soziale Netzwerk ist Facebook (weitere aktuelle Beispiele sind X, Instagram und TikTok). Facebook verkündete 2010, dass die Plattform 500 Millionen User erreicht hat. 2011 war Facebook die am zweit-häufigsten besuchte Website weltweit nach Google.
Definition von Social Media bei Wikipedia (Abruf 03/2019):
Social Media (auch soziale Medien) sind digitale Medien und Methoden, die es Nutzern ermöglichen, sich im Internet zu vernetzen, sich also untereinander auszutauschen und mediale Inhalte einzeln oder in einer definierten Gemeinschaft oder offen in der Gesellschaft zu erstellen und weiterzugeben.
2011-14: HTML5 und CSS3
Einführung von HTML5, welches verschiedene "Verzweigungen" von HTML vereinheitlicht (HTML 4.01, XHTML) und neue, insbesondere auch semantische Elemente einführt. Parallel wurde auch die "Styling-Sprache" CSS (cascading style sheets) vereinheitlicht und erweitert und läuft unter dem Begriff CSS3.
2015: HTTP/2
Einführung von HTTP/2, dem Nachfolger des HTTP-Protokolls (davor HTTP/1.1), das eine schnellere und effizientere Übertragung von Webinhalten ermöglicht.
2015: Progressive Web Apps
Mit der steigenden Zahl an Smartphone-Nutzer*innen stieg der Entwicklungsaufwand für die Softwareentwickler*innen, um sowohl Webseiten als auch Apps für die verschiedenen Geräte und Systeme anzubieten. Progressive Web Apps (PWAs) sind Webseiten, die in ihren Funktionen nativen Apps ähneln. Progressive Web Apps werden wie normale Webseiten mit Hilfe von HTML, CSS und JavaScript erstellt. Durch zusätzliche Anpassungen, wie dem Hinzufügen eines sogenannten Service Workers, können native App-Funktionen (z. B. Offline-Verwendbarkeit) ergänzt werden.
2022: HTTP/3
Einführung von HTTP/3, das nun statt TCP das Protokoll QUIC (basierend auf UDP) verwendet.
2.2 Grundbegriffe im Internet
Wir schauen uns hier ein paar grundlegende Mechanismen sowohl des Internets aber insbesondere des WWW an.
Das Internet ist zunächst eine Ansammlung von Rechnern (Ihr Laptop, Ihr Smartphone/Tablet, die Server von Universitäten, Regierungseinrichtungen und Firmen und viele mehr), die alle miteinander kommunizieren. Heutzutage kommen zum Beispiel Autos, Haushaltsgeräte und Armbanduhren dazu.
2.2.1 Kommunikation
Die Kommunikation findet über Kabel (sogenannte Ethernetkabel) oder drahtlos (WLAN) statt.
Eine Form der Kommunikation ist es, Nachrichten von einem Absender zu einem Adressaten zu schicken. Eine Nachricht besteht aus mindestens dem Adressaten (wer soll die Nachricht bekommen) und natürlich dem Inhalt (Text, Bild, Dokument etc.).
Wenn Nachrichten verschickt werden, werden diese in kleinere Pakete zerlegt. Diese Pakete werden dann über mehrere Rechner hinweg an den Adressaten geschickt und dort wieder zur ursprünglichen Nachricht zusammengesetzt. Damit dies möglichst ohne Fehler und möglichst ohne Verlust von Daten funktioniert, gibt es Protokolle, die den grundlegenden Ablauf festlegen und Fehler und Verluste beheben bzw. verhindern (oder minimieren). Für Webentwickler ist das HTTP am relevantesten, weil über dieses Protokoll Webseiten verschickt werden.
Das HTTP-Protokoll setzt auf zwei anderen Protokollen auf, nämlich IP und TCP, die häufig in Kombination "TCP/IP" genannt werden.
2.2.2 IP-Adresse und Domain
Wie erwähnt benötigt jede Nachricht einen Adressaten. Wie werden Rechner im Internet "angesprochen"? Jeder Rechner hat eine eindeutige IP-Adresse (IP bezieht sich auf das Protokoll). Diese ändert sich bei einem "normalen" User bei jeder neuen Einwahl ins Internet, man nennt das auch dynamische Adressvergabe. Sie können Ihre aktuelle IP-Adresse z. B. ansehen bei http://www.wieistmeineip.de.
Wichtige Server haben eine statische IP-Adresse. Unsere Hochschule, die TH Augsburg, hat die statische IP-Adresse
141.82.11.30Da IP-Adressen aus Zahlen bestehen, fällt es Menschen schwer, sich diese zu merken, um sie z. B. in den Browser einzugeben. Daher gibt es menschenlesbare Domain-Namen, wie z. B.
www.tha.deEine Domain besteht aus drei Teilen:
<subdomain>.<domain>.<top-level domain>Wie funktioniert die Zuordnung von Domänen zu IP-Adressen? Dazu gibt es spezielle Server, sogenannte DNS-Server. Diese Server sind die "Telefonbücher" des Internets. DNS steht für Domain Name System.
Anmerkung: Die obige IP-Adresse folgt dem alten Standard IPv4 (Version 4). Da in diesem Standard die Anzahl der möglichen Adressen knapp wurde (und aus vielen anderen Gründen), gibt es einen aktuelleren Standard IPv6 (Version 6).
2.2.3 Dienste und Ports
Im Internet werden Daten zu sehr unterschiedlichen Zwecken verschickt. Es werden Dokumente und Fotos runtergeladen, es werden Mails verschickt und Webseiten transportiert. Man spricht hier von verschiedenen Diensten.
Die meisten Dienste haben ein eigenes Kommunikationsprotokoll:
- Transport von Webseiten: HTTP
- Sicherer Transport von Webseiten: HTTPS
- Transport von Daten (Dateien): FTP
- Datenbankanfragen: mySQL
- Versand von e-Mails: SMTP
Jeder Rechner hat, sobald er mit dem Internet verbunden ist, eine eindeutige IP-Adresse. Damit verschiedene Dienste (z. B. e-Mail, Webseiten, Datei-Download) gleichzeitig mit diesem Rechner kommunizieren können, gibt es verschiedene "Andockstellen" eines Rechners, genannt Ports.
Hier einige übliche Ports für die oben genannten Dienste:
- Transport von Webseiten (HTTP): Port 80
- Sicherer Transport von Webseiten (HTTP): Port 443
- Transport von Daten (FTP): Port 21
- Datenbankanfragen (mySQL): Port 3306
- Versand von e-Mails (SMTP): Port 25
2.2.4 URL - mehr als eine Adresse
Mit Hilfe der IP-Adresse können Sie einen spezifischen Rechner im Internet ansprechen. Wenn Sie jetzt eine spezifische Webseite aufrufen möchten, brauchen Sie ein Format, in dem Sie diese angeben können. Dies nennt sich URL (Uniform Resource Locator) und wurde in einer ersten Form bereits von Tim Berners-Lee entwickelt.
In einem Browser haben Sie einen Eingabereich, wo Sie z. B. folgende Textzeile eingeben können:
www.tha.deDies ist allerdings nur ein Teil der URL. Im Browser funktioniert die Anfrage aber trotzdem, da Ihr Browser fehlende Teile einfach ergänzt. Eine vollständige URL sieht z. B. so aus:
https://www.tha.de:443/Rechenzentrum.htmlDabei ist
- "https" ist das Protokoll, allgemein sagt man Schema
- "www.tha.de" ist die IP-Adresse des adressierten Rechners, diesen nennt man auch Host
- "443" ist der Port
- "Rechenzentrum.html" ist ein Dateipfad auf dem Host, der auch Unterverzeichnisse beinhalten kann
Im Browser wird die Port-Angabe ":443" normalerweise weggelassen, da diese Angabe immer gleich ist. Auch das "http://" bzw. "https://" wird oft weggelassen oder in grau automatisch vorangestellt.
URLs gibt es nicht nur für Webseiten, sondern auch für andere Dienste wie Filezugriff und Mails (sichtbar am Schema). Für uns relevant ist aber hier nur das Schema für HTTP.
Für HTTP sieht die URL allgemein so aus (Teile in eckigen Klammern sind optional):
scheme://host:port/pfad/.../[?Query][#Fragment]Die zwei optionalen Teile sind
- Query: mit Fragezeichen abgetrennt können Parameter direkt in der URL kodiert werden; das sieht man oft bei Suchanfragen, deshalb auch der Begriff "query" (engl. für fragen, abfragen); mehrere Parameter werden mit dem Zeichen
&getrennt - Fragment: mit einem Hash kann ein spezieller Einstiegspunkt (auch Anker genannt) innerhalb der Webseite (z. B. ein bestimmter Abschnitt in einem längeren Text) angegeben werden, zu dem gesprungen werden soll
Beispiel für eine URL mit Query:
https://www.youtube.com/watch?v=U7ILbfPxAIwBeispiel für eine URL mit Fragment:
https://de.wikipedia.org/wiki/Edward_Snowden#Leben2.3 Grundprinzipien des WWW
2.3.1 Client-Server
Zwei wichtige Begriffe, die immer wieder auftauchen werden, sind Client und Server.
Das Internet ist wie gesagt eine Ansammlung von Rechnern. Ein "Rechner" kann in diesem Zusammenhang nicht nur ein Laptop oder ein Smartphone, sondern auch ein Auto, eine Heizungsanlage oder eine Glühbirne sein.
Wenn zwei Rechner miteinander kommunizieren, gibt es zwei mögliche Rollen in der Kommunikation: ein Rechner ist der Client, der andere Rechner ist der Server.

Ein typischer Client ist ein einzelner User mit einem Laptop, auf dem ein Browser läuft. Ein typischer Server ist ein großer Rechner in einem Rechenzentrum, der eine Website bereitstellt, z. B. die Webseiten einer Hochschule.
Rollenverteilung
Was bedeuten diese Rollen? Der Server bietet einen Dienst an (z. B. eine Webseite auszuliefern) und der Client kann diesen Dienst anfordern. Der Server wartet also passiv auf mögliche Anfragen. Der Client muss aktiv die Verbindung aufnehmen, indem er eine erste Anfrage stellt (in Form einer Nachricht). Der Transport von Nachrichten erfolgt im Internet in der Regel über mehrere Rechner und wird über die entsprechenden Internetprotokolle so gehandhabt, dass sichergestellt ist, dass die Nachricht beim richtigen Rechner und ohne Verluste ankommt.

Wir abstrahieren vom Transport durchs Internet und stellen in der Regel nur Client und Server und ihre Kommunikation dar. Natürlich kann auch der Server Nachrichten zurück an den Client schicken (z. B. um die Webseite auszuliefern).
Viele Clients, ein Server, jederzeit
Ein Server kann mit vielen Clients gleichzeitig kommunizieren und das ist auch der "Normalfall", d. h. ein Server muss sich mit dem Problem herumschlagen, wie er die Verwaltung der vielen Clients managt.
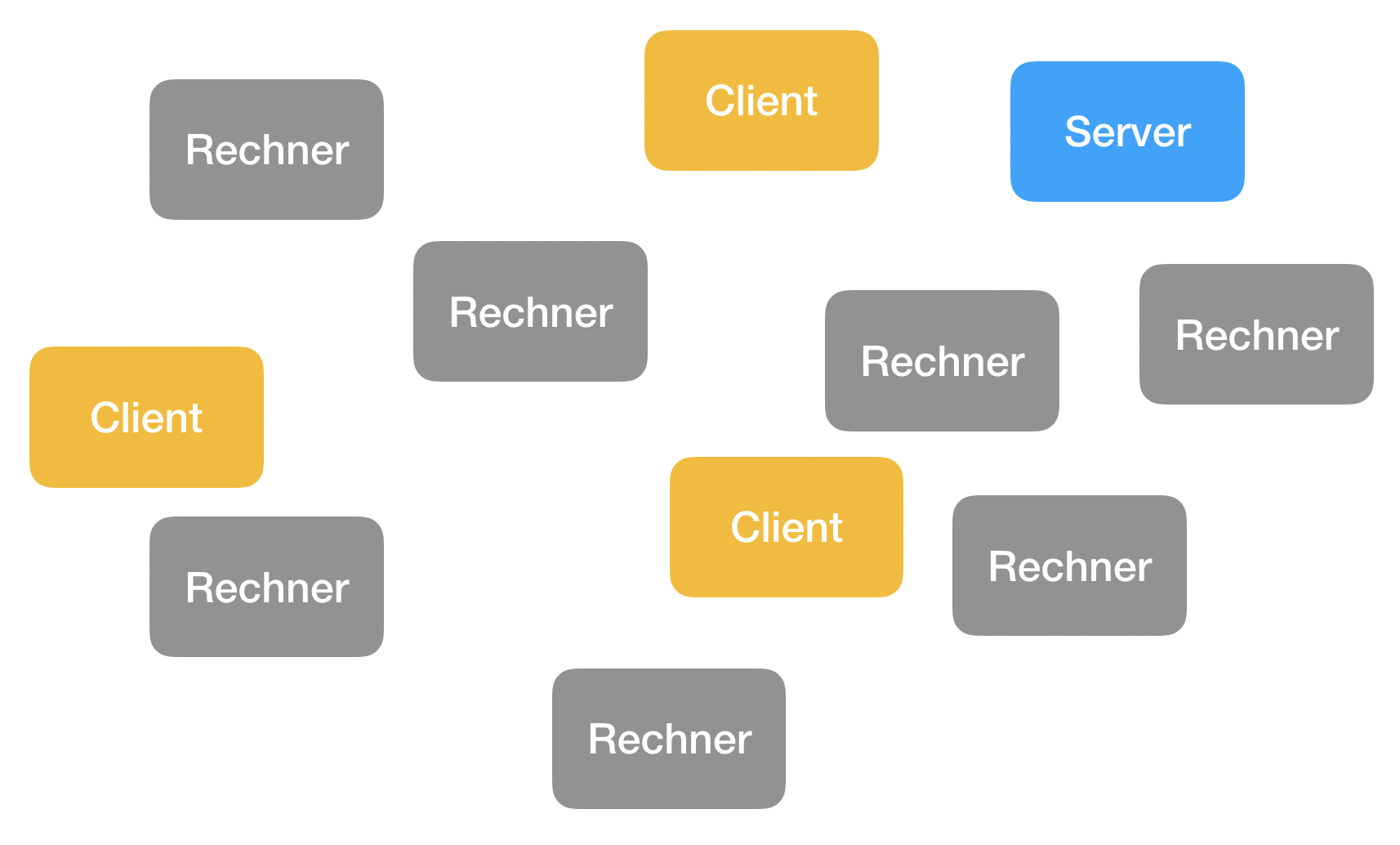
Zudem ist ein Server in der Regel zu jeder Zeit aktiv und ans Internet angeschlossen, wohingegen die meisten Clients nur phasenweise aktiv sind.
Zum Begriff Server
Der Begriff "Server" ist manchmal verwirrend, weil viele sich darunter große Hallen mit Serverschränken bei einem Unternehmen wie Google oder Amazon vorstellen. Das ist auch korrekt, weil man mit "Server" auch die Hardware meint. Ein Server aber ist gleichzeitig aber auch eine ganz spezielle Software, die die Kommunikation mit potentiell mehreren Clients managt.
Eine Server-Software muss nicht unbedingt bei einer großen Organisation (Hochschule, Suchmaschine, Shop) verortet sein, Sie können auf Ihrem Laptop einen Server installieren und werden dies spätestens im Kapitel zu PHP tun (Software XAMPP).
Einen eigenen Server installiert man häufig auf dem eigenen Laptop, um bestimmte Web-Mechanismen zu testen. Sie haben dann die Situation, dass Ihr Laptop sowohl Client als auch Server ist:
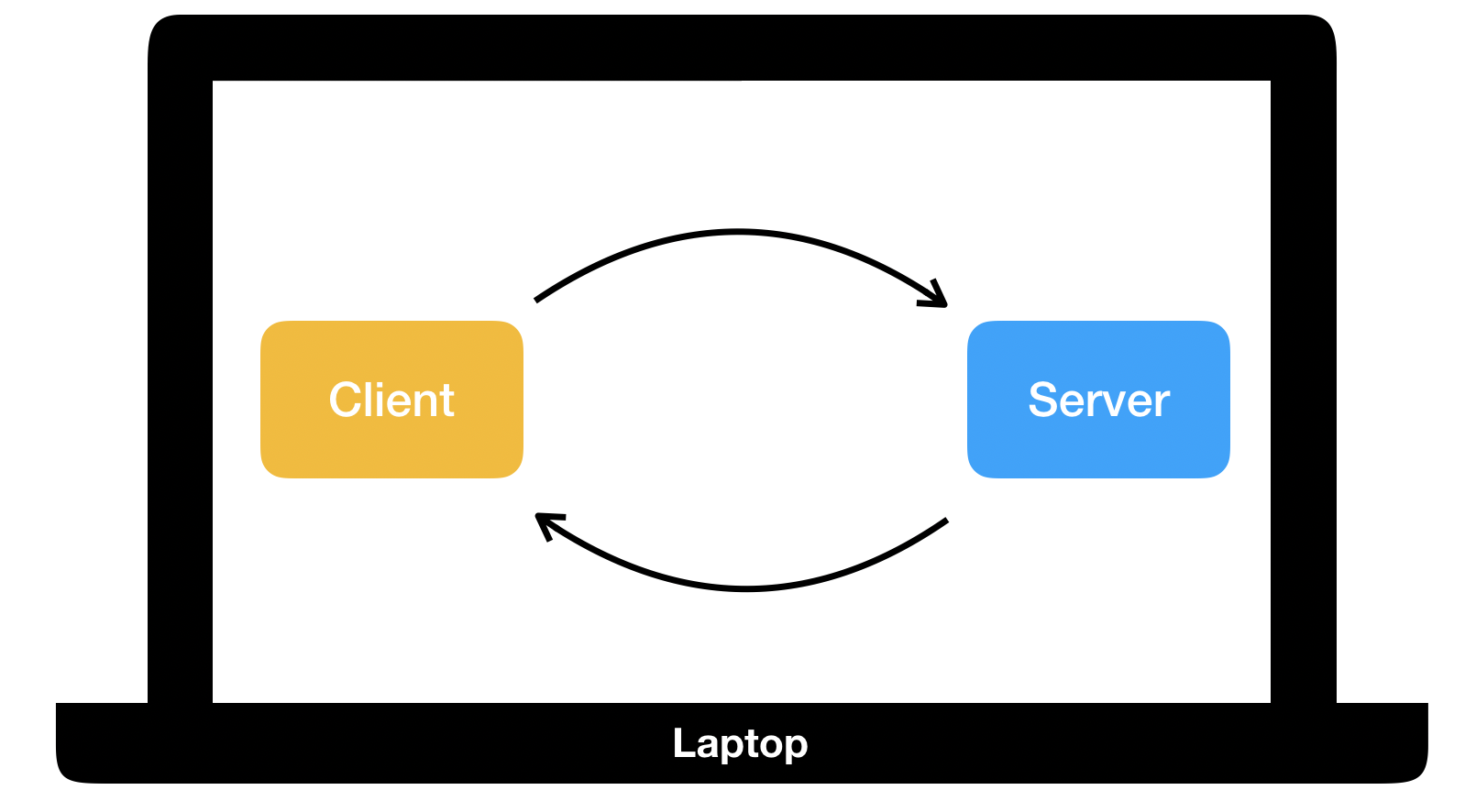
2.3.2 Request und Response
Webseiten werden über ein Protokoll namens HTTP (Hypertext Transfer Protocol) durch das Internet transportiert. Dieses Protokoll arbeitet nach dem Prinzip Anfrage-Antwort (Request-Response). Das klingt zunächst einfach, hat aber einige wichtige Implikationen.
Beispiel Webseite
Wenn ein Benutzer eine Internetseite in seinem Browser aufruft, schickt der Browser eine Anfrage mit einem bestimmten Adresse (eine URL, die auch einen Dateipfad enthalten kann) ins Internet. Im Internet wird ein Server identifiziert, der diese Anfrage bekommt. Den Benutzer nennt man in diesem Fall auch Client. Das Grundlegende Prinzip ist das von Request (Anfrage) und Response (Antwort):
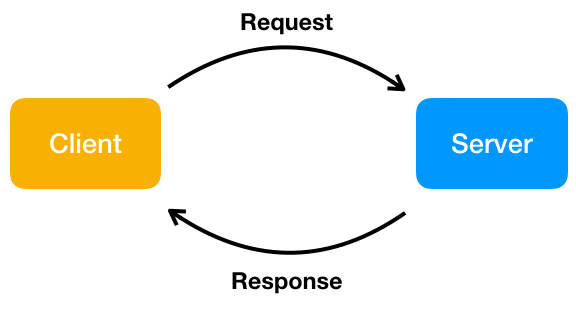
Um hier einen sinnvollen Austausch hinzubekommen, müssen natürlich noch Daten mitgeschickt werden. Bei der Request sind das die Adresse des Servers (Host-Adresse) und ein Pfad (welche Datei wird angefragt? Zum Beispiel "start.html" oder "login.html"). Bei der Response ist das dann das entsprechende HTML-Dokument.
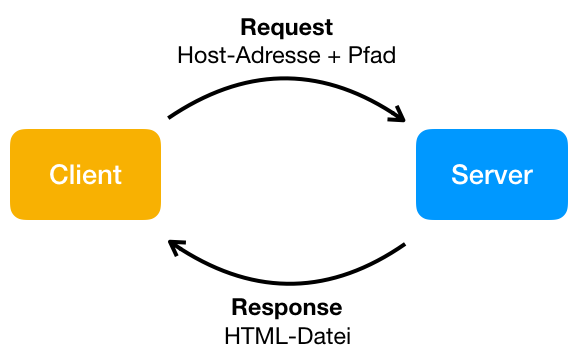
Der Server geht auf ein bestimmtes Verzeichnis und sucht nun nach dem in der Anfrage angegebenen Pfad. Wenn der Pfad ein Verzeichnis ist, wird nach einer Datei namens index.html gesucht. Ist die Datei gefunden, schickt der Server diese HTML-Datei zurück an den Browser des Benutzers.
Wie sehen Request und Response aus?
Ein Request ist zunächst mal "nur" eine Textnachricht, die z. B. so aussieht:
GET /index.html HTTP/1.1
Host: www.michaelkipp.de
[Leerzeile]Allgemein ist die Struktur eines Requests wie folgt
METHODE /path HTTP/version
Header1: value
Header2: value
[Leerzeile]
[optional Request-Body]Es gibt verschiedene Typen von Requests, genannt Methoden. Die zwei mit Abstand wichtigsten Methoden sind GET und POST (weitere sind z. B. HEAD, PUT oder DELETE). Die beiden Requestarten unterscheiden sich darin, wie Parameter verschickt werden (ein Parameter ist z. B. das Suchwort bei einer Suchanfrage). Bei GET stehen diese in der URL, sind also direkt sichtbar, wohingegen bei POST die Parameter im Request-Body "versteckt" sind.
Diese URL-Angabe resultiert z. B. in einem GET-Request:
https://www.google.com&q=snowdenDie Response ist ebenfalls eine Textnachricht. Die allgemeine Struktur ist wie folgt:
HTTP/version statuscode
explanation
Header1: value
Header2: value
[Response-Body]Wenn Sie z. B. eine Webseite zugeschickt bekommen, steht in der Response:
HTTP/1.1 200 OK
Date: Mon, 27 Jul 2009 12:28:53 GMT
Server: Apache/2.2.14 (Win32)
Last-Modified: Wed, 22 Jul 2009 19:15:56 GMT
Content-Length: 88
Content-Type: text/html
Connection: Closed
<html>
<body>
<h1>Hello, World!</h1>
</body>
</html>Der dreistellige Statuscode zeigt an, ob es Probleme beim Bearbeiten der Anfrage gab. Beginnt der Statuscode mit 2 ist alles in Ordnung. Beginnt der Code mit 4, ist ein Fehler aufgetreten, den der Client verursacht hat. Sie kennen sicher den Code 404, der zurückkommt, wenn Sie z. B. eine nicht existierende Seite/Datei aufrufen wollten. Beginnt der Code mit 5, ist ein Fehler auf seiten des Servers aufgetreten.
Mehrere Requests
Die obige Darstellung ist etwas vereinfacht. In Wirklichkeit zieht eine Anfrage fast immer weitere Anfragen nach sich. Eine Webseite besteht nämlich in der Regel aus mehreren Dateien (HTML-Datei, Bilder, CSS-Datei/en, JavaScript-Datei/en etc.). Für jede dieser Dateien wird eine eigene Anfrage gestellt und die Antwort enthält die angeforderte Datei.
Diese verschiedenen Anfragen für eine Webseite werden auch nicht immer an den gleichen Server gestellt. So kann eine Webseite Text und Layout von Server A beziehen und vereinzelt Bilder von Wikipedia und ein Video von YouTube.
Zustandslose Kommunikation
Die mit Abstand wichtigste Eigenschaft der Kommunikation über HTTP ist die Tatsache, dass die Kommunikation zustandslos ist. Das heißt, bei jedem Request weiß der Server überhaupt nichts über die vorige Kommunikation.
In einem Gespräch zwischen zwei Menschen haben Sie zum Beispiel eine (An-)Frage wie
Gesprächspartner C an S: Warum?S kennt weder die vorigen Anfragen noch die Identität von C. Sie können sich vorstellen, dass ein solcher Dialog schwierig ist.
Selbst einfachste Maschinen haben meist einen Zustand. Stellen Sie sich einen Süßigkeiten- oder Getränkeautomaten vor. Sie sind der Client C, der Automat ist Server S:
C/Anfrage 1: Einwurf von 2 Euro
S/Antwort: Zeigt 2 Euro an
C/Anfrage 2: Süßigkeit im Fach 35 (Kosten: 80 Cent)
S/Antwort: Lässt Schokoriegel raus, zeigt 1,20 Euro an
C/Anfrage 3: Süßigkeit im Fach 42 (Kosten: 1,00 Euro)
S/Antwort: Lässt Gummibärchen raus, zeigt 20 Cent an
C/Anfrage 4: Knopf für Restgeld
S/Antwort: Wirft 20 Cent ausIch hoffe, Sie sehen, dass der Zustand hier die Geldmenge ist, die dem Client zur Verfügung steht. Ohne diesen Zustand würde selbst diese doch sehr simple Interaktion nicht funktionieren!
Offensichtlich gibt es aber im Web viele Anwendungen, die einen Zustand haben müssen (z. B. ein Online-Shop mit Ihrem Warenkorb). Das heißt, es muss Mechanismen geben, die es erlauben einen Zustand zu modellieren. Cookies und Sessions sind solche Hilfsmittel, die wir im Kapitel PHP im Web noch kennenlernen werden.
2.3.3 Frontend und Backend
In der Webentwicklung unterscheidet man die Bereiche Frontend und Backend.
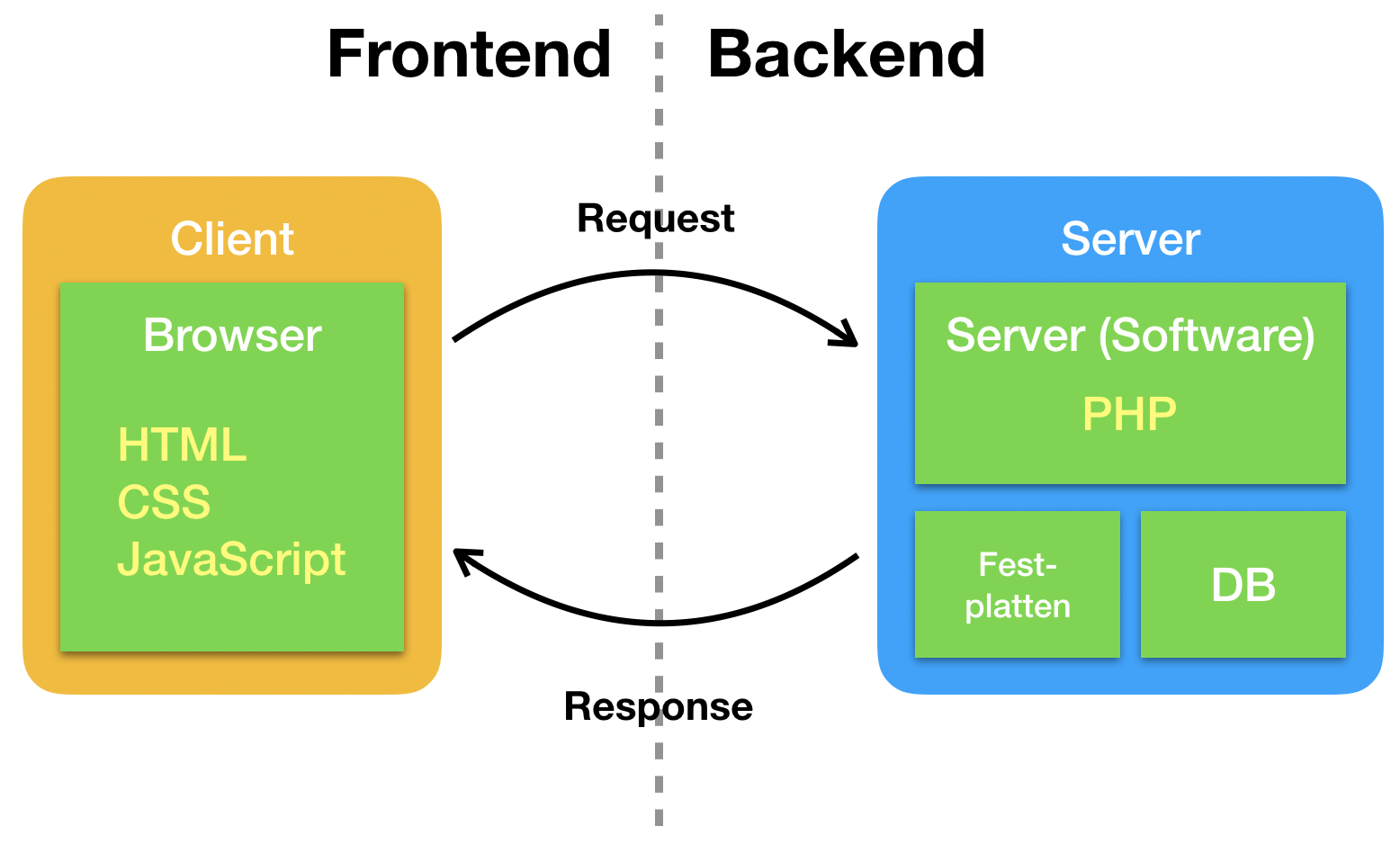
Das Frontend bezieht sich auf alles, was im Browser abläuft. Der Browser erhält vom Server Dateien mit HTML, CSS und JavaScript. Der Browser stellt anhand der Informationen in HTML/CSS die Webseite dar und startet etwaige JavaScript-Programmteile. Diese JavaScript-Programme wiederum verändern häufig die Darstellung von HTML und CSS.
Das Backend bezieht sich auf alles, was auf dem Server abläuft. Auf dem Server läuft zunächst mal eine Server-Software. Im einfachsten Fall, liefert diese Software einfach nur Dateien aus, die auf den Festplatten des Servers liegen. Die haben aber auch die Möglichkeit, Webseiten mit Hilfe einer Programmiersprache immer dann erst zusammenzubauen, wenn eine Anfrage eintrifft (das nennt man dann eine dynamische Webseite). Wenn Sie einen Online-Shop betreiben, möchten Sie für einen Kunden vielleicht speziell eine individuelle Startseite zusammenbauen. Gängige Programmiersprachen dafür sind zum Beispiel JavaScript oder PHP (möglich ist aber auch Java, Python oder Ruby). Die Inhalte für dynamische Webseiten werden oft in Datenbanken gespeichert und nicht in Dateien. Der bekannteste Typ Datenbanken sind SQL-Datenbanken (SQL ist eine Sprache zur Ansteuerung von Datenbanken).
2.3.4 Content-Management-Systeme
CMS mit Datenbank
In der Webentwicklung bezieht sich der Begriff Content-Management-System (CMS) auf eine Software, die es erlaubt, eine größere Website zu erstellen und gemeinsam mit mehreren Personen zu verwalten, also z. B. Inhalte zu erstellen. Bekannte CMS im Web-Bereich sind Wordpress, Joomla, Drupal oder TYPO3.
Der Vorteil dieser Systeme ist, dass nach Einrichtung eines solchen CMS für das Einstellen und Bearbeiten von Inhalten keine grundlegenden technischen Kenntnisse notwendig sind. Das CMS stellt ein Backend über den Browser bereit, wo das Einstellen und Bearbeiten von Inhalten und anderen Elementen über eine grafische Oberfläche gehandhabt werden kann.
Ein CMS besteht oft aus einer Software, die auf einem Server läuft und die in einer Serversprache wie PHP geschrieben ist, sowie einer Datenbank, häufig in Form einer SQL-Datenbank. Diese Software erzeugt bei User-Anfragen dynamisch HTML-Seiten aufgrund der Datenbankinhalte und schickt diese dann an den User.
Der Nachteil eines CMS besteht in der Komplexität der Software, die für einfache Webseiten oft nicht notwendig ist. Zudem können kleinere Anpassungen manchmal unmöglich sein oder unverhältnismäßig aufwändig sein. Zudem können die dynamische Generierung sowie die Datenbankzugriffe zu Performance-Problemen und somit zu längeren Ladezeiten führen.
Erstes Beispiel: Bei einer Website eines sozialen Netzwerks sind die Inhalt hochgradig dynamisch, sowohl was Inhalte (Texte, Bilder, Videos) als auch was kleinere Informationen (Likes, Follower etc.) betrifft. Hier ist ein CMS unbedingt notwendig.
Zweites Beispiel: Bei einem Blog, den nur eine einzige Person betreibt, ändern sich die Inhalte eher selten (wöchentlich, monatlich). Daher muss nicht bei jeder Anfrage eine HTML-Seite mit Hilfe von Datenbank-Inhalten (Blogartikel) neu zusammengesetzt werden. Hier wäre ein Flat-File-CMS oder ein Static-Site-Generator angemessener.
Flat-File-CMS
Neuere CMS ersetzen die Datenbank durch ein einfaches Datei-System. Man nennt diese auch Flat-File-CMS. Ein schönes Beispiel für ein Flat-File-CMS ist Kirby. Kirby für z. B. für den Showcase Interaktive Medien der TH Augsburg verwendet.
Static-Site-Generatoren
Wenn die Komplexität eines CMS zu hoch für eine einfache Webseite ist, aber dennoch eine Seite hergestellt werden soll, ohne dass alles "von Scratch" in HTML/CSS/JS programmiert wird, dann können Static-Site-Generatoren sinnvoll sein.
Hier werden Inhalte - oft in Form einer vereinfachten Markierungssprache wie Markdown - lokal auf der Festplatte des Betreibers gehalten. Die Software "übersetzt" die Inhalte in entsprechende HTML-Seiten und diese werden dann hochgeladen. Wenn man z. B. einen neuen Inhalt erstellt, wiederholt man diesen Prozess des Übersetzens und Hochladens. Auf dem Server befindet sich im Grunde eine statische Website.
Beispiele für Static-Site-Generatoren sind Hugo oder Jekyll.